package main
import (
"errors"
"flag"
"io/ioutil"
"log"
"net/http"
"os"
"strconv"
"strings"
"github.com/PuerkitoBio/goquery" // 解析html
)
var website = ""
var dir string = ""
var file_size int64 = 200 //文件大于200kb则下载
func loadUrl(uri string) (*goquery.Document, error) {
resp , err_resp := http.Get(uri)
if err_resp != nil {
return nil, err_resp
}
defer resp.Body. Close ()
log.Printf("resp.Status %v", resp.Status)
if resp.StatusCode != 200 {
log.Fatalf("访问 异常 %v", uri)
return nil, errors.New("访问异常,code:" + resp.Status)
}
return goquery.NewDocumentFromResponse(resp)
}
func getCatagreyUrls() []string {
var urls []string
doc, _ := loadUrl(website)
if doc == nil {
return nil
}
doc.Find(".pagelist > .thisclass").Each(func(i int, s *goquery. Selection ) {
pageTotal := s.Text()
log.Printf("共%v页", pageTotal)
p_count, ee := strconv.Atoi(pageTotal)
if ee == nil {
var url string
for i := 1; i < p_count; i++ {
url = website + "/list_" + strconv.Itoa(i) + ".html" //网址信息
urls = append(urls, url)
}
}
})
return urls
}
//分析栏目
func parseCatagrey(url string) {
doc, err := loadUrl(url)
if err != nil {
log.Fatal(err)
}
if doc == nil {
return
}
nodes := doc.Find(".w170img > a ")
if nodes == nil {
return
}
log.Printf("栏目分页 %v\t当前页共%v图片", url, nodes.Length())
nodes.Each(func(i int, s *goquery.Selection) { //遍历整个文档
item_url, _ := s.Attr("href")
log.Printf("item_url:%v", item_url)
if item_url == "" || item_url == "#" {
return
}
// 启动协程下载图片
if strings.Index(item_url, "//") == 0 {
item_url = "https:" + item_url
}
parseImgDetail(item_url, true)
})
}
//分析展示详情页的图片地址
func parseImgDetail(uri string, repeat bool) {
uri = strings. Replace (uri, "/p/", website, -1)
log.Printf("图片浏览页:%v", uri)
doc, err_doc := loadUrl(uri)
if err_doc != nil {
log.Printf("%v,解析异常:%v", uri, err_doc)
}
if doc == nil {
return
}
imgs := doc.Find(".imagebody > p > a > img")
log.Printf("图片数量 %v", imgs.Length())
img_src, _ := imgs.Attr("src")
// imgs.Each(func(j int, t *goquery.Selection) {
// img_src, _ := t.Attr("src")
if img_src == "" {
return
}
go download(img_src)
if repeat == false {
return
}
pageList := doc.Find(".pagelist > a")
log.Printf("%v\t当前页共%v页", uri, pageList.Length())
pageList.Each(func(i int, s *goquery.Selection) {
href, _ := s.Attr("href")
text := s.Text()
if href == "" || text == "" || text == "下一页" || href == uri {
return
}
parseImgDetail(href, false)
})
}
// 下载图片
func download(img_url string) {
log.Printf("图片:%v", img_url)
file_name := strings.Replace(img_url, "#34;, dir, -1)
log.Printf("保持文件:%v", file_name)
os.MkdirAll(file_name+"_", os.ModePerm)
os.RemoveAll(file_name + "_")
_, err_stat := os.Stat(file_name)
if err_stat == nil {
log.Printf("已存在:%v", file_name)
return
}
f, err := os.Create(file_name)
if err != nil {
log.Panic("文件创建失败", err)
return
}
defer f.Close() //结束关闭文件
resp, err := http.Get(img_url)
if err != nil {
log.Println("http.get err", err)
}
log.Printf("resp: %s", resp.Status)
ctLen := resp.ContentLength / 1024
log.Printf("图片大小 %v", ctLen)
if file_size > 0 && ctLen <= file_size {
log.Printf("文件太小<%v", file_size)
return
}
body, err1 := ioutil.ReadAll(resp.Body)
if err1 != nil {
log.Println("读取数据失败")
}
defer resp.Body.Close() //结束关闭
f.Write(body)
}
func main() {
flag.StringVar(&website, "url", "", "网址")
flag.StringVar(&dir, "d", "", "保存目录,默认当前目录下")
flag.Int64Var(&file_size, "fsize", 0, "文件大小 kb 默认0kb 表示不限制")
flag.Parse() //一定要执行
if website == "" {
log.Println("未设置网址,使用-url 传参数")
return
}
urls := getCatagreyUrls()
for _, url := range urls {
parseCatagrey(url)
}
}
线程池方式执行
package main
import (
"errors"
"flag"
"io/ioutil"
"log"
"net/http"
"os"
"runtime"
"strconv"
"strings"
"time"
"github.com/PuerkitoBio/goquery" // 解析html
)
//任务接口
type Job interface {
Do()
}
//工人
type worker struct {
JobQueue chan Job
Quit chan bool
}
func NewWorker() Worker {
return Worker{
JobQueue: make(chan Job),
Quit: make(chan bool),
}
}
func (w Worker) Run(wq chan chan Job) {
go func() {
for {
wq <- w.JobQueue
select {
case job := <-w.JobQueue:
job.Do()
case <-w.Quit:
return
}
}
}()
}
type WorkerPool struct {
WokerLen int
JobQueue chan Job
WorkerQueue chan chan Job
}
func NewWorkerPool(workerlen int) *WorkerPool {
return &WorkerPool{
WokerLen: workerlen, //开始建立 workerlen 个worker(工人)协程
JobQueue: make(chan Job), //工作队列 通道
WorkerQueue: make(chan chan Job, workerlen), //最大通道参数设为 最大协程数 workerlen 工人的数量最大值
}
}
func (wp *WorkerPool) Run() {
log.Println("初始化worker")
for i := 0; i < wp.WokerLen; i++ {
worker := NewWorker()
worker.Run(wp.WorkerQueue)
}
go func() {
for {
select {
case job := <-wp.JobQueue: //读取任务
//尝试获取一个可用的worker作业通道 这将阻塞,直到一个worker空闲
worker := <-wp.WorkerQueue
//将任务分配给工人
worker <- job
}
}
}()
}
var website = ""
var dir string = ""
var file_size int64 = 0 //文件大于200kb则下载
var workpool *WorkerPool
func loadUrl(uri string) (*goquery.Document, error) {
resp, err_resp := http.Get(uri)
if err_resp != nil {
return nil, err_resp
}
defer resp.Body.Close()
log.Printf("resp.Status %v", resp.Status)
if resp.StatusCode != 200 {
log.Fatalf("访问 异常 %v", uri)
return nil, errors.New("访问异常,code:" + resp.Status)
}
return goquery.NewDocumentFromResponse(resp)
}
func getCatagreyUrls() []string {
var urls []string
doc, _ := loadUrl(website)
if doc == nil {
return nil
}
doc.Find(".pagelist > .thisclass").Each(func(i int, s *goquery.Selection) {
pageTotal := s.Text()
log.Printf("共%v页", pageTotal)
p_count, ee := strconv.Atoi(pageTotal)
if ee == nil {
var url string
for i := 1; i < p_count; i++ {
url = website + "/list_" + strconv.Itoa(i) + ".html" //网址信息
urls = append(urls, url)
}
}
})
return urls
}
//分析栏目
func parseCatagrey(url string) {
doc, err := loadUrl(url)
if err != nil {
log.Fatal(err)
}
if doc == nil {
return
}
nodes := doc.Find(".w170img > a ")
if nodes == nil {
return
}
log.Printf("栏目分页 %v\t当前页共%v图片", url, nodes.Length())
nodes.Each(func(i int, s *goquery.Selection) { //遍历整个文档
item_url, _ := s.Attr("href")
log.Printf("item_url:%v", item_url)
if item_url == "" || item_url == "#" {
return
}
// 启动协程下载图片
if strings.Index(item_url, "//") == 0 {
item_url = "https:" + item_url
}
parseImgDetail(item_url, true)
})
}
//分析展示详情页的图片地址
func parseImgDetail(uri string, repeat bool) {
uri = strings.Replace(uri, "/p/", website, -1)
log.Printf("图片浏览页:%v", uri)
doc, err_doc := loadUrl(uri)
if err_doc != nil {
log.Printf("%v,解析异常:%v", uri, err_doc)
}
if doc == nil {
return
}
imgs := doc.Find(".imagebody > p > a > img")
log.Printf("图片数量 %v", imgs.Length())
img_src, _ := imgs.Attr("src")
if img_src == "" {
return
}
// go download(img_src)
//使用线程池
//创建任务
sc := &DownloadJob{uri: img_src}
//加入线程队列
workpool.JobQueue <- sc
if repeat == false {
return
}
pageList := doc.Find(".pagelist > a")
log.Printf("%v\t当前页共%v页", uri, pageList.Length())
pageList.Each(func(i int, s *goquery.Selection) {
href, _ := s.Attr("href")
text := s.Text()
if href == "" || text == "" || text == "下一页" || href == uri {
return
}
parseImgDetail(href, false)
})
}
type DownloadJob struct {
uri string
}
//实现Job Do 接口
func (d *DownloadJob) Do() {
download(d.uri)
}
// 下载图片
func download(img_url string) {
log.Printf("图片:%v", img_url)
file_name := strings.Replace(img_url, "#34;, dir, -1)
os.MkdirAll(file_name+"_", os.ModePerm)
os.RemoveAll(file_name + "_")
_, err_stat := os.Stat(file_name)
if err_stat == nil {
log.Printf("已存在:%v", file_name)
return
}
f, err := os.Create(file_name)
if err != nil {
log.Panic("文件创建失败", err)
return
}
defer f.Close() //结束关闭文件
resp, err := http.Get(img_url)
if err != nil {
log.Println("http.get err", err)
}
log.Printf("resp: %s", resp.Status)
ctLen := resp.ContentLength / 1024
log.Printf("图片大小 %v", ctLen)
if file_size > 0 && ctLen <= file_size {
log.Printf("文件太小<%v", file_size)
return
}
body, err1 := ioutil.ReadAll(resp.Body)
if err1 != nil {
log.Println("读取数据失败")
}
defer resp.Body.Close() //结束关闭
f.Write(body)
log.Printf("保存文件:%v", file_name)
}
func main() {
var poolSzie int = 1000
flag.StringVar(&website, "url", "", "网址")
flag.StringVar(&dir, "dir", "", "保存目录,默认当前目录下")
flag.Int64Var(&file_size, "file-size", 0, "文件大小 kb 默认0 表示不限制")
flag.IntVar(&poolSzie, "pool", 1000, "线程池大小 默认1000")
flag.Parse() //一定要执行
if website == "" {
log.Println("未设置网址,使用-url 传参数")
return
}
workpool = NewWorkerPool(poolSzie)
workpool.Run()
urls := getCatagreyUrls()
for _, url := range urls {
parseCatagrey(url)
}
for { //阻塞主程序结束
log.Println("=========\nruntime.NumGoroutine() :%v", runtime.NumGoroutine())
time.Sleep(5 * time.Second)
}
}
跑了4个小时下载的文件数量
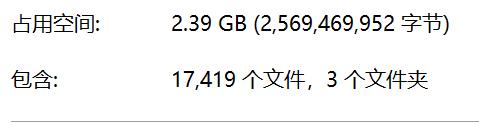
由于目标网站的IP封锁,所以开设的线程数10个,耗时比较长。
原理是使用goquery分析页面,查找对应的链接地址,然后再访问该地址获取图片链接,再http.get获取并保存。


