上一讲讲完了 的诞生,它不是第一个,算上 g0,它要算第二个了。不过,我们要考虑的就是这个 goroutine,它会真正执行用户代码。
g0 栈用于执行调度器的代码,执行完之后,要跳转到执行用户代码的地方,如何跳转?这中间涉及到栈和 寄存器 的切换。要知道,函数调用和返回主要靠的也是 CPU 寄存器的切换。goroutine 的切换和此类似。
继续看 proc1 函数的代码。中间有一段调整运行空间的代码,计算出的结果一般为 0,也就是一般不会调整 SP 的位置,忽略好了。
// 确定参数入栈位置 spArg := sp
参数的入参位置也是从 SP 处开始,通过:
// 将参数从执行 newproc 函数的栈拷贝到新 g 的栈 memmove(unsafe.Pointer(spArg), unsafe.Pointer(argp), uintptr(narg))
将 fn 的参数从 g0 栈上拷贝到 newg 的栈上,memmove 函数需要传入源地址、目的地址、参数大小。由于 main 函数在这里没有参数需要拷贝,因此这里相当于没做什么。
接着,初始化 newg 的各种字段,而且涉及到最重要的 pc,sp 等字段:

首先,memclrNoHeapPointers 将 newg.sched 的内存全部清零。接着,设置 sched 的 sp 字段,当 goroutine 被调度到 m 上运行时,需要通过 sp 字段来指示栈顶的位置,这里设置的就是新栈的栈顶位置。
最关键的一行来了:
// newg.sched.pc 表示当 newg 被调度起来运行时从这个地址开始执行指令 newg.sched.pc = funcPC(goexit) + sys.PCQuantum // +PCQuantum so that previous instruction is in same function
设置 pc 字段为函数 goexit 的地址加 1,也说是 goexit 函数的第二条指令,goexit 函数是 goroutine 退出后的一些清理工作。有点奇怪,这是要干嘛?接着往后看。
newg.sched.g = guintptr(unsafe.Pointer(newg))
设置 g 字段为 newg 的地址。插一句,sched 是 g 结构体 的一个字段,它本身也是一个结构体,保存调度信息。复习一下:

接下来的这个函数非常重要,可以解释之前为什么要那样设置 pc 字段的值。调用 gostartcallfn:
gostartcallfn(&newg.sched, fn) //调整sched成员和newg的栈
传入 newg.sched 和 fn。

函数 gostartcallfn 只是拆解出了包含在 funcval 结构体里的函数指针,转过头就调用 gostartcall。将 sp 减小了一个指针的位置,这是给返回地址留空间。果然接着就把 buf.pc 填入了栈顶的位置:
*(*uintptr)(unsafe.Pointer(sp)) = buf.pc
原来 buf.pc 只是做了一个搬运工,搞什么啊。重新设置 buf.sp 为送减掉一个指针位置之后的值,设置 buf.pc 为 fn,指向要执行的函数,这里就是指的 runtime .main 函数。
对嘛,这才是应有的操作。之后,当调度器“光顾”此 goroutine 时,取出 buf.sp 和 buf.pc,恢复 CPU 相应的寄存器,就可以构造出 goroutine 的运行环境。
而 goexit 函数也通过“偷天换日”将自己的地址“强行”放到 newg 的栈顶,达到自己不可告人的目的:每个 goroutine 执行完之后,都要经过我的一些清理工作,才能“放行”。这样一说,goexit 函数还真是无私,默默地做一些“扫尾”的工作。
设置完 newg.sched 这后,我们的图又可以前进一步:
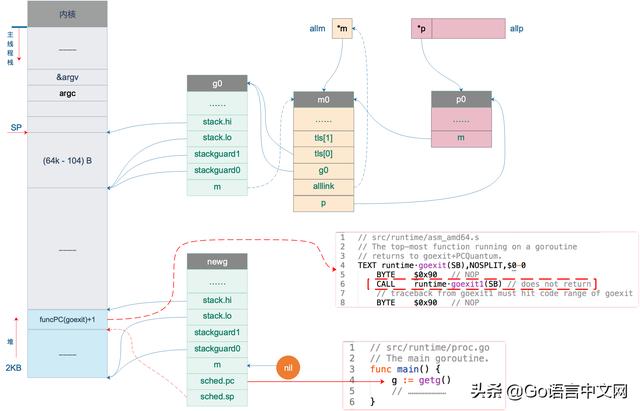
设置 newg.sched
上图中,newg 新增了 sched.pc 指向 runtime.main 函数,当它被调度起来执行时,就从这里开始;新增了 sched.sp 指向了 newg 栈顶位置,同时,newg 栈顶位置的内容是一个跳转地址,指向 runtime.goexit 的第二条指令,当 goroutine 退出时,这条地址会载入 CPU 的 PC 寄存器,跳转到这里执行“扫尾”工作。
之后,将 newg 的状态改为 runnable,设置 goroutine 的 id:
// 设置 g 的状态为 _Grunnable,可以运行了 casgstatus(newg, _Gdead, _Grunnable) newg.goid = int64(_p_.goidcache)
每个 P 每次会批量(16个)申请 id,每次调用 newproc 函数,新创建一个 goroutine,id 加 1。因此 g0 的 id 是 0,而 main goroutine 的 id 就是 1。
newg 的状态变成可执行后(Runnable),就可以将它加入到 P 的本地运行队列里,等待调度。所以,goroutine 何时被执行,用户代码决定不了。来看源码:
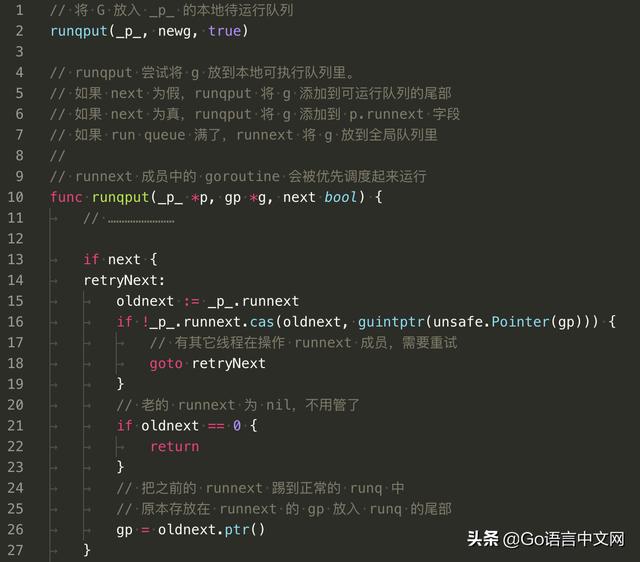
runqput 函数的主要作用就是将新创建的 goroutine 加入到 P 的可运行队列,如果本地队列满了,则加入到全局可运行队列。前两个参数都好理解,最后一个参数 next 的作用是,当它为 true 时,会将 newg 加入到 P 的 runnext 字段,具有最高优先级,将先于普通队列中的 goroutine 得到执行。
先将 P 老的 runnext 成员取出,接着用一个 原子操作 cas 来试图将 runnext 成员设置成 newg,目的是防止其他 线程 在同时修改 runnext 字段。
设置成功之后,相当于 newg “挤掉” 了原来老的处于 runnext 的 goroutine,还得给人遣散费,安顿好人家嘛,不然和强盗有何区别?
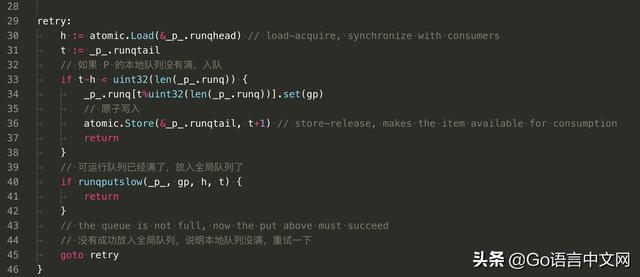
“安顿”的动作在 retry 代码段中执行。先通过 head,tail,len(_p_.runq) 来判断队列是否已满,如果没满,则直接写到队列尾部,同时修改队列尾部的指针。
// store-release, makes it available for consumption atomic.Store(&_p_.runqtail, t+1)
这里使用原子操作写入 runtail,防止编译器和 CPU 指令重排,保证上一行代码对 runq 的修改发生在修改 runqtail 之前,并且保证当前线程对队列的修改对其它线程立即可见。
如果本地队列满了,那就只能试图将 newg 添加到全局可运行队列中了。调用 runqputslow(_p_, gp, h, t) 完成。

先将 P 本地队列里所有的 goroutine 加入到一个数组中,数组长度为 len(_p_.runq)/2 + 1,也就是 runq 的一半加上 newg。
接着,将从 runq 的头部开始的前一半 goroutine 存入 bacth 数组。然后,使用原子操作尝试修改 P 的队列头,因为出队了一半 goroutine,所以 head 要向后移动 1/2 的长度。如果修改失败,说明 runq 的本地队列被其他线程修改了,因此后面的操作就不进行了,直接返回 false,表示 newg 没被添加进来。
batch[n] = gp
将 newg 本身添加到数组。
通过循环将 batch 数组里的所有 g 串成链表:
for i := uint32(0); i < n; i++ {
batch[i].schedlink.set(batch[i+1])
}

批量 goroutine 连接成链表
最后,将链表添加到全局队列中。由于操作的是全局队列,因此需要获取锁,因为存在竞争,所以代价较高。这也是本地可运行队列存在的原因。调用 globrunqputbatch(batch[0], batch[n], int32(n+1)):

如果全局的队列尾 sched.runqtail 不为空,则直接将其和前面生成的链表头相接,否则说明全局的可运行列队为空,那就直接将前面生成的链表头设置到 sched.runqhead。
最后,再设置好队列尾,增加 runqsize。
设置完成之后:

放到全局可运行队列
再回到 runqput 函数,如果将 newg 添加到全局队列失败了,说明本地队列在此过程中发生了变化,又有了位置可以添加 newg,因此重试 retry 代码段。我们也可以发现,P 的本地可运行队列的长度为 256,它是一个循环队列,因此最多只能放下 256 个 goroutine。
因为本文还是处于初始化的场景,所以 newg 被成功放入 p0 的本地可运行队列,等待被调度。
将我们的图再完善一下:

newg 添加到本地 runq
参考资料
【阿波张 Go语言调度器之调度 main 】


