一、基础知识
1、一个主机的端口号为所有进程所共享,但普通用户进程绑定bind不了一些特殊端口号如20、80等。
多个进程不能同时监听listen同一个端口,会失败。当然父进程可以先listen然后fork多个子进程,多个子进程都可以accept这个sock,即抢夺式响应(惊群效应)。
关注4元组是否能唯一确定一个连接?
2、每个进程都有自己的文件描述符(包括file fd, socket fd, timer fd, event fd, signal fd),一般是1024,可以通过ulimit -n 设置,但所有进程打开的文件描述符总数有上限,跟主机的内存有关。
3、一个进程内的所有 线程 共享进程的文件描述符。
二、并发服务器方案:
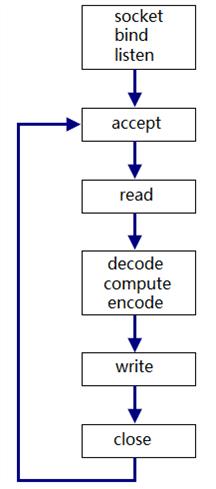
1、循环式/迭代式( iterative )服务器
无法充分利用 多核 CPU,不适合执行时间较长的服务,即适用于短连接。如果是长连接则需要在read/write之间循环,那么只能服务一个客户端。
2、并发式(concurrent)服务器
one connection per process/one connection per thread
适合执行时间比较长的服务
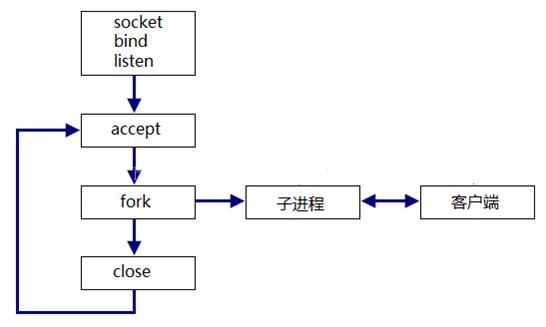
one connection per process : 主进程每次fork 之后要关闭connfd,子进程要关闭listenfd
one connection per thread : 主线程每次accept 回来就创建一个子线程服务,由于线程共享文件描述符,故不用关闭。
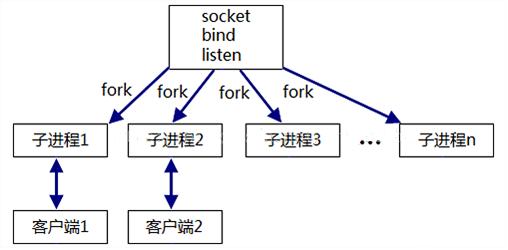
3、prefork or pre threaded(容易发生“惊群”现象,即多个子进程都处于accept状态)
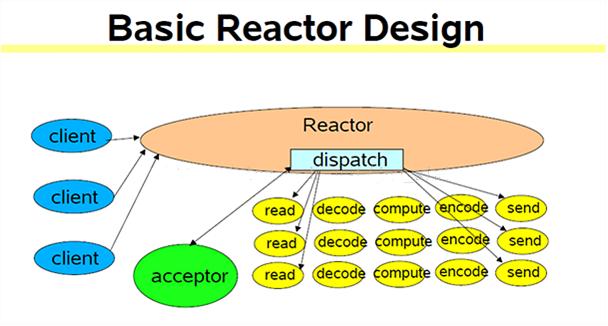
4、反应式( reactive )服务器 (reactor模式)(select/ poll /epoll)
并发处理多个请求,实际上是在一个线程中完成。无法充分利用多核CPU
不适合执行时间比较长的服务,所以为了让客户感觉是在“并发”处理而不是“循环”处理,每个请求必须在相对较短时间内执行。
5、reactor + thread per request(过渡方案)
6、reactor + worker thread(过渡方案)
7、reactor + thread pool(能适应密集计算)

muduo库中的/example/suduku/ 中有这样一个例子,因为数独求解是计算密集型任务。
在实践中为了reactor能快速回到事件循环去响应请求,经常将读到的数据put到一个环形内存队列(一般内存or共享内存),而thread pool的线程则从中读取进行数据计算。
需要C/C++ Linux 服务器架构师学习资料私信“资料”(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享
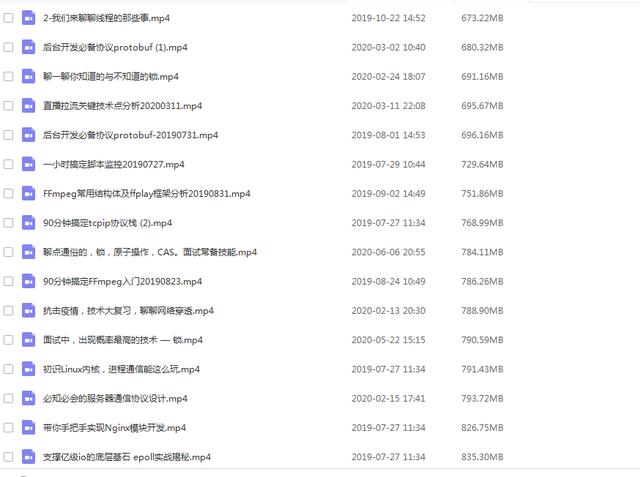
8、multiple reactors(能适应更大的突发I/O)
reactors in threads(one loop per thread)
reactors in processes
一般来说一个subReactor适用于一个千兆网口
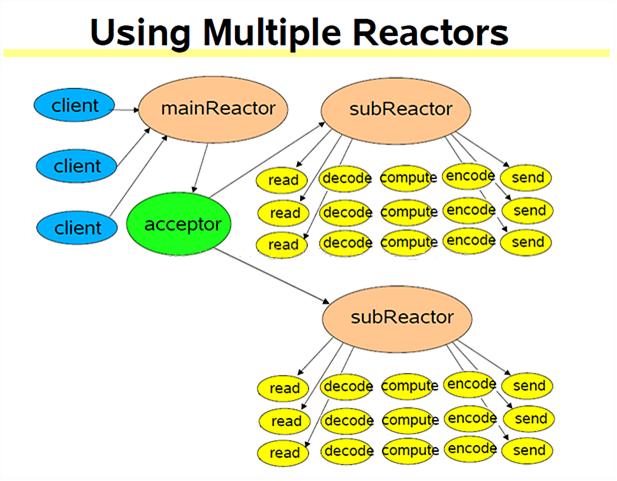
9、multiple reactors + thread pool(one loop per thread + threadpool)(突发I/O与密集计算)
subReactor可以有多个,但threadpool只有一个。

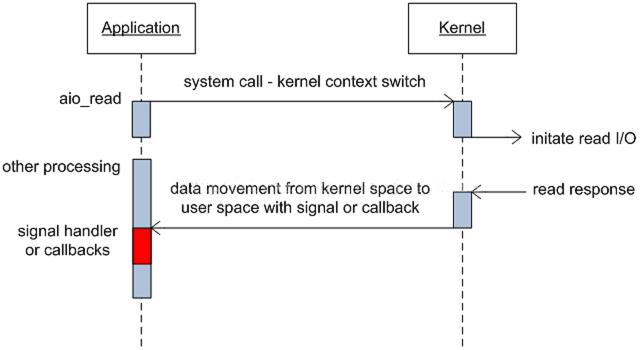
10、proactor服务器(proactor模式,基于异步I/O)
理论上proactor比reactor效率要高一些
异步I/O能够让I/O操作与计算重叠。充分利用DMA特性。
Linux异步IO
glibc aio(aio_*),有bug
kernel native aio(io_*),也不完美。目前仅支持 O_DIRECT 方式来对磁盘读写,跳过系统缓存。要自已实现缓存,难度不小。
boost asio实现的proactor,实际上不是真正意义上的异步I/O,底层是用epoll来实现的,模拟异步I/O的。
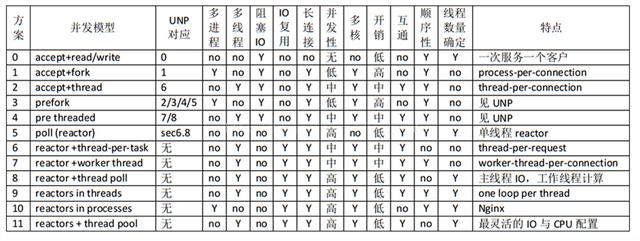
常见并发服务器方案比较:
三、一些常见问题
1、Linux能同时启动多少个线程?
对于 32-bit Linux,一个进程的地址空间是 4G,其中用户态能访问 3G 左右,而一个线程的默认栈 (stack) 大小是 8M,心算可知,一个进程大约最多能同时启动 350 个线程左右。
2、 多线程 能提高并发度吗?
如果指的是“并发连接数”,不能。
假如单纯采用 thread per connection 的模型,那么并发连接数大约350,这远远低于基于事件的单线程程序所能轻松达到的并发连接数(几千上万,甚至几万)。所谓“基于事件”,指的是用 IO multiplexing event loop 的编程模型,又称 Reactor 模式。
3、多线程能提高吞吐量吗?
对于计算密集型服务,不能。
如果要在一个8核的机器上压缩100个1G的文本文件,每个core的处理能力为200MB/s,那么“每次起8个进程,一个进程压缩一个文件”与“只启动一个进程(8个线程并发压缩一个文件)”,这两种方式总耗时相当,但是第二种方式能较快的拿到第一个压缩完的文件。
4、多线程能提高响应时间吗?
可以。参考问题3
5、多线程程序日志库要求
线程安全,即多个线程可以并发写日志,两个线程的日志消息不会出现交织。
用一个全局的mutex保护IO
每个线程单独写一个日志文件
前者造成全部线程抢占一个锁(串行写入)
后者有可能让业务线程阻塞在写磁盘操作上。(磁盘IO时间比较长)
解决办法:用一个logging线程负责收集日志消息,并写入日志文件,其他业务线程只管往这个“日志线程”发送日志消息(如通过BlockingQueue提供接口),这称为“异步日志”,也是一个经典的生产者消费者模型。
6、 线程池 大小的选择
如果池中执行任务时,密集计算所占时间比重为P(0<P<=1),而系统一共有C个CPU,为了让C个CPU跑满而不过载,线程池大小的经验公式T=C/P,即T*P=C(让CPU刚好跑满 )
假设C=8,P=1.0,线程池的任务完全密集计算,只要8个活动线程就能让CPU饱和
假设C=8,P=0.5,线程池的任务有一半是计算,一半是IO,那么T=16,也就是16个“50%繁忙的线程”能让8个CPU忙个不停。
7、线程分类
I/O线程(这里特指网络I/O)
计算线程
第三方库所用线程,如logging,又比如database


