为什么分析map
在计算机编程语言当中,用的最多的数据结构估计就是map。map以他近乎o(1)的查找效率和修改效率让他在大多数场景下都比较受青睐。map的常规的实现方式都是hash+其他数据结构,如java是hash+红黑树,而我现在即将要分析的go的实现方式是hash+链表。我会分析map的几乎每段代码,并且在我的GitHub: 可以查看到我的分析,注释十分详尽,欢迎批评指正。我的打算是把一些常用的数据结构都分析一遍,如果有志同道合的人,可以联系我。
我的环境
为了给那些感兴趣看源码分析我的博客的同学阅读得更加清晰,列举了我的环境:
- go1.14.7 amd64 ;
- windows和mac接口,linux没有测试,估计没问题 ;
- goland,目前最好的golang ide,虽然笔者用起来感觉还是不太完美 ;
- 着重分析map[string]string,其他类型的源码变化不大 ;
本篇重点
1. go的map和java的map有区别,go中是一个关键字,而java确实可以直接查看源码,那么如何分析go的map源码?
2. 调试过程当中,go充斥着大量指针,如何知道指针指向的内容?map的最小单位bmap除了查看tophash,怎么查看里面的其他隐藏字段?
3. go的map源码为何给不同的key的类型设计不同的实现?
4. 其他一些查看源码的小技巧:内存对齐、指针偏移、类型大小等等
如何找到map对应的源码
go的map的结构体是hmap,代码位于 runtime/map.go ,当编译器编译你申明使用map的源码时候,其实是使用了 runtime/map*.go ,后面对map的增删改查都是执行该代码,故要弄懂map的底层原理只需要分析该源码,也可以断点调试。 我下面有个自己测试的源码,注意我编译之后查看,就可以发现端倪:
1 package main
2
3 import "fmt"
4
5 func main() {
6 m1 := make(map[string]string)
7 fmt.Println(m1)
8 m2 := make(map[string]string, 8)
9 fmt.Println(m2)
10 m3 := make(map[string]string, 9)
11 fmt.Println(m3)
12 m4 := map[string]string{}
13 fmt.Println(m4)
14 m3["1"] = "2"
15 for k, v := range m3 {
16 fmt.Println(k)
17 fmt.Println(v)
18 }
19 v1 := m3["1"]
20 fmt.Println(v1)
21 if v2, ok := m3["1"]; ok {
22 fmt.Println(v2)
23 }
24 }
上面代码有几种不同申明map的方式,对应 runtime/map.go 也不同。还有赋值和遍历查找的代码。 下面编译得到汇编指令文件,执行
go tool compile -N -l -S main.go > main.txt
生成了汇编指令文件:
"".main STEXT size=1891 args=0x0 locals=0x288
0x0039 00057 (main.go:6) CALL runtime.makemap_small(SB)
0x00ca 00202 (main.go:8) CALL runtime.makemap_small(SB)
0x015b 00347 (main.go:10) LEAQ type.map[string]string(SB), AX
0x0178 00376 (main.go:10) CALL runtime.makemap(SB)
0x020a 00522 (main.go:12) CALL runtime.makemap_small(SB)
0x02a0 00672 (main.go:14) LEAQ type.map[string]string(SB), AX
0x02ca 00714 (main.go:14) CALL runtime.mapassign_faststr(SB)
0x0354 00852 (main.go:15) CALL runtime.mapiterinit(SB)
0x0527 01319 (main.go:15) CALL runtime.mapiternext(SB)
0x055b 01371 (main.go:19) CALL runtime.mapaccess1_faststr(SB)
0x063e 01598 (main.go:21) CALL runtime.mapaccess2_faststr(SB)
东西有点多,但是我们只分析几个重点
- main.go 的第6行、第8行和第12行的map申明分别对应着 main.txt 23行、57行和132行,都是调用的 runtime.makemap_small 方法
- main.go 的第10行对应着 main.txt 的97行 runtime.makemap 方法
- main.go 的第14行的赋值对应着 main.txt 的184行 runtime.mapassign_faststr 方法
- main.go 的第15行的循环对应着 main.txt 第224行的 runtime.mapiterinit 方法初始化得到迭代器
- main.go 的第19行和第21行分别对着 main.txt 2个不同的方法 runtime.mapaccess1 faststr 和 runtime.mapaccess2 faststr
runtime/map.go 的方法包括上面列举的方法: runtime.makemap small 、 runtime.makemap 和 runtime.mapiterinit 方法

由于我的示例代码的map的key是string类型,故 runtime.mapassign faststr、 runtime.mapaccess1 faststr 和 runtime.mapaccess2 faststr方法在 runtime/map_faststr.go 代码里面,该文件优化了string类型的key的操作:

go的map对应的结构体hmap
go的map的基础结构体是hmap,在 runtime/map.go中,
// A header for a Go map.
type hmap struct {
// Note: the format of the hmap is also encoded in cmd/compile/internal/gc/reflect.go.
// Make sure this stays in sync with the compiler's definition.
// map存储的键值对个数
count int // # live cells == size of map. Must be first (used by len() builtin)
// 表示map的一些标志位
flags uint8
// map的桶的2的对数就是B值
B uint8 // log_2 of # of buckets (can hold up to loadFactor * 2^B items)
// 溢出桶个数,是个近似数,不完全相等
noverflow uint16 // approximate number of overflow buckets; see incrnoverflow for details
// hash种子
hash0 uint32 // hash seed
// 桶,真正存数据的地方,2^B个桶
buckets unsafe.Pointer // array of 2^B Buckets. may be nil if count==0.
// 保存一些即将迁移的桶
oldbuckets unsafe.Pointer // previous bucket array of half the size, non-nil only when growing
// 从oldbuckets迁移到新的buckets的进度
nevacuate uintptr // progress counter for evacuation (buckets less than this have been evacuated)
// 当key不是指针类型的数据的时候,里面会存溢出桶,这样会避免go的扫描
extra *mapextra // optional fields
}
既然是map结构体,为何注释说是一个header呢?这是因为buckets和oldbuckets这2个字段并没有真正存取数据,只是存了一个指针,指向存取buckets的地址,故我们在使用过程中拷贝hmap的时候,并没有真正拷贝map的数据,只是拷贝了hmap这个结构体的一些数据。 再看看hmap的字段mapextra:
// mapextra holds fields that are not present on all maps.
type mapextra struct {
// If both key and elem do not contain pointers and are inline, then we mark bucket
// 如果key和value都不包括指针并且内敛,然后我们就标记bucket没有指针
// type as containing no pointers. This avoids scanning such maps.
// 这样会避免gc扫描
// However, bmap.overflow is a pointer. In order to keep overflow buckets
// 但是,虽然key和value不包括指针,但是逸出桶却是个指针,为了让逸出桶一直
// alive, we store pointers to all overflow buckets in hmap.extra.overflow and hmap.extra.oldoverflow.
// 存在,所以就把逸出桶和需要迁移的逸出桶的指针存到hamp的extra字段里面
// overflow and oldoverflow are only used if key and elem do not contain pointers.
// 如果key和elme包含指针,overflow和oldoverflow就不会被使用了
// overflow contains overflow buckets for hmap.buckets.
// oldoverflow contains overflow buckets for hmap.oldbuckets.
// The indirection allows to store a pointer to the slice in hiter.
overflow *[]*bmap
oldoverflow *[]*bmap
// nextOverflow holds a pointer to a free overflow bucket.
nextOverflow *bmap
}
如mapextra结构体为啥说有些字段并不会在所有map里面全部都有呢?mapextra是一个为了优化bucket而设计的,当key或value是指针的时候,此时overflow和oldoverflow就不会被使用,只有nextOverflow会被使用,该字段保存了预先申请的逸出桶,在没有发生扩容的时候,而一个桶或者说bmap的8个tophash都被使用完了,那么就要考虑使用逸出桶。 当key和value都没有指针的时候bucket的bmap的_type的ptrdata就是0,意味着该结构体是没有指针的,申请bmap内存的时候,会申请一个没有指针的span,这样会避免gc扫描该内存,会提高效率,但是bmap的最后一个内存块是确确实实存放指针的,所以用uintptr存储着该map的逸出桶的地址,但是由于没有指向下一个逸出桶,可能会被gc回收掉,所以就需要overflow存取指向该逸出桶的指针避免被gc回收掉。 overflow和oldoverflow的用处差不多,只是oldoverflow为了迁移使用,后面的系列会详说。
bucket的结构体bmap
bmap就是真正存数据的结构体了,bmap在源码中定义十分简单:
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
但其实真正的在内存中分配的结构体是这样的:
// A bucket for a Go map.
type bmap struct {
// tophash generally contains the top byte of the hash value
// for each key in this bucket. If tophash[0] < minTopHash,
// tophash[0] is a bucket evacuation state instead.
tophash [bucketCnt]uint8
keys [bucketCnt]string // 由于我举例的key是string,故我这里写string
values [bucketCnt]string // 由于上面我的例子的value的类型是string,故这里也是string
pointer unsafe.pointer // 由于key和value都是指针,所以这里是一个指针
// Followed by bucketCnt keys and then bucketCnt elems.
// NOTE: packing all the keys together and then all the elems together makes the
// code a bit more complicated than alternating key/elem/key/elem/... but it allows
// us to eliminate padding which would be needed for, e.g., map[int64]int8.
// Followed by an overflow pointer.
}
隐藏的字段在map源码中都是靠地址偏移来得到,tophash我们能轻易找到位置,但是如何找到keys、values和pointer呢? 在map中是这么做的:
dataOffset = unsafe.Offsetof(struct {
b bmap
v int64
}{}.v)
在64位机器上,需要对齐8个字节,这里int64正好也是8个字节,所以恰好解决内存对齐的问题,找到v的起始地址也就是values的起始地址:
dataOffset+bucketCnt*2*sys.PtrSize // string16个字节,相当于2个指针,bucketCnt等于8
pointer的起始地址
dataOffset+bucketCnt*2*sys.PtrSize+sys.PtrSize
tophash存的是key的hash高8位,为了方便查找key,为什么keys和values分别存在一堆呢?不是k|v|k|v这种呢?由于key和value的变量类型可能不一样,对齐系数不一致,可能导致内存不紧凑而浪费内存,所以把8个keys存到一堆,8个values存到一堆,然后最后在pointer之前对齐就可以了。所以此时也能算出来整个bmap的大小:
bucketCnt*(uint8的字节为1)+bucketCnt*(string的字节16)+bucketCnt*(string的字节16)+指针大小8字节 = 272
在真正调试的时候如查看bucket里面的具体的key和value呢?这里给大家展示一个小技巧,如果大家有其他方法,可以留言讨论:
type dmap struct {
tophash [bucketCnt]uint8
debugKeys [bucketCnt]string
debugElems [bucketCnt]string
//debugOverflows unsafe.Pointer
debugOverflows uintptr
}
这是我定义的调试结构体,将该代码和bmap的结构体放到一堆,当你获取到bmap桶的地址的时候,就可以如下转换,就可以查看bmap的具体值了:
b0 := (*dmap)(add(buckets, uintptr(0)*uintptr(t.bucketsize)))
println(b0.debugOverflows)
buckets假设是桶数组的起始地址,加上bucketsize就会得到第二个桶的起始地址,然后直接转型为*dmap,最后你可以可以打印出来你想查看的真实的值了。
map的整体结构
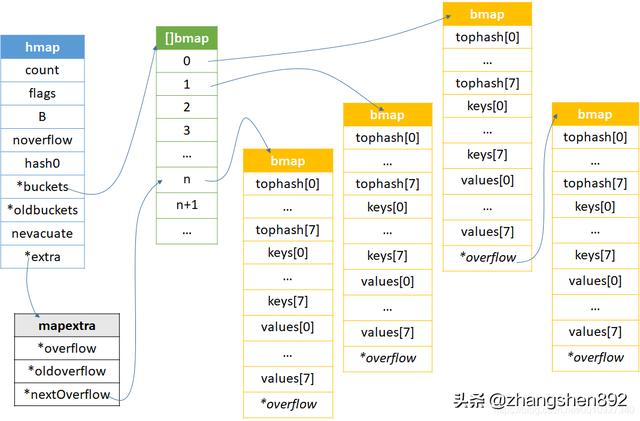
如果申请内存桶的时候有多余的溢出桶,那么mapextra的nextOverflow就会指向[]bmap其中的某块桶的地址,地址后之后的桶都是溢出桶。在一个桶装不下的时候,会去溢出桶拿桶然后bmap的overflow指向溢出桶。
总结
上面大概介绍了map的数据结构,后面系列map的具体代码分析,包括增、删、改、查、扩容等都会分篇细解,如有不足之处,请共同讨论学习。



