介绍
在本教程中,我们将在Golang中从头开始构建一个简单的神经网络(单层感知器)。我们还将根据样本数据对其进行培训并进行预测。从头开始创建自己的神经网络将帮助您更好地了解神经网络内部发生的事情以及学习算法的工作。
什么是感知器?
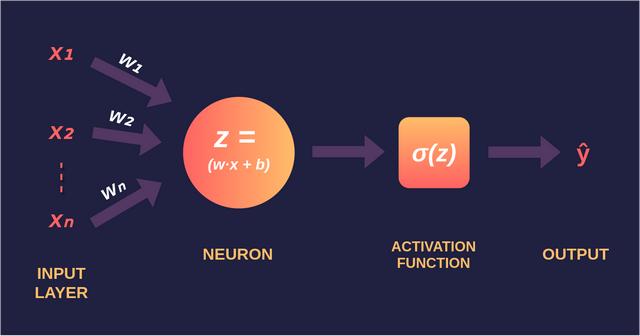
感知器——由Frank Rosenblatt于1958年发明,是最简单的神经网络,由n个输入、1个神经元和1个输出组成,其中n是我们数据集的特征数。
因此,我们的单层感知器由以下组件组成:
- 输入层(x)
- 输出层(ŷ)
- 这两层之间的一组权重(w)和一个偏差(b)
- 输出层的激活函数(σ)。在本教程中,我们将使用sigmoid激活函数。
我们的神经网络被称为单层感知器(SLP),因为神经网络只有一层神经元。具有一层以上神经元的神经网络称为多层感知器(MLP)。
(注:epoch是指整个训练数据集的一个周期)
type Perceptron struct {
input [][]float64
actualOutput []float64
weights []float64
bias float64
epochs int
} 开始之前
我们将为以下数学运算构建自己的函数- 向量 加法、向量点积和标量矩阵乘法。
func dotProduct(v1, v2 []float64) float64 { //Dot Product of Two Vectors of same size
dot := 0.0
for i := 0; i < len(v1); i++ {
dot += v1[i] * v2[i]
}
return dot
}
func vecAdd(v1, v2 []float64) []float64 { //Addition of Two Vectors of same size
add := make([]float64, len(v1))
for i := 0; i < len(v1); i++ {
add[i] = v1[i] + v2[i]
}
return add
}
func scalarMatMul(s float64, mat []float64) []float64 { //Multiplication of a Vector & Matrix
result := make([]float64, len(mat))
for i := 0; i < len(mat); i++ {
result[i] += s * mat[i]
}
return result
} 最初,神经网络的权值设置为0到1之间的随机浮点数,而偏差设置为0。
func (a *Perceptron) initialize() { // rand om Initialization
rand.Seed(time.Now().UnixNano())
a. bias = 0.0
a.weights = make([]float64, len(a.input[0]))
for i := 0; i < len(a.input[0]); i++ {
a.weights[i] = rand.Float64()
}
} 正向传播
通过神经网络传递数据的过程称为前向传播或前向传递。感知器的输出是:
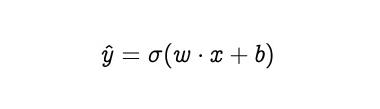
简而言之,权向量(w)和输入向量(x)的点积加上偏压(b),求和通过激活函数。乙状结肠激活函数的输出将为0和1。
func (a *Perceptron) sigmoid(x float64) float64 { //Sigmoid Activation
return 1.0 / (1.0 + math.Exp(-x))
}
func (a *Perceptron) forwardPass(x []float64) (sum float64) { //Forward Propagation
return a.sigmoid(dotProduct(a.weights, x) + a.bias)
} 学习算法
学习算法由反向传播和优化两部分组成。
反向传播,简称误差反向传播,是指计算损失函数相对于权重的梯度的算法。然而,这个术语经常被用来指代整个学习算法。
损失函数用来估计我们离期望解有多远。一般来说,回归问题的损失函数是均方误差,分类问题的损失函数是交叉熵。为了简单起见,我们将使用均方误差作为损失函数。另外,我们不会计算MSE,而是直接计算它的梯度。
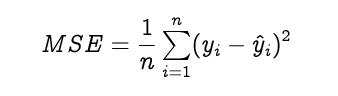
用链式法则计算损失函数的梯度,损失函数相对于权重和偏差的梯度计算如下。
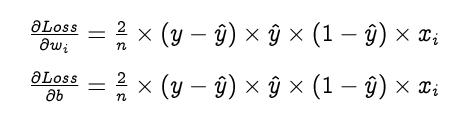
优化就是选择感知器的最佳权值和偏差,以达到预期的效果。我们选择梯度下降作为优化算法。权值和偏差更新如下,直到收敛。
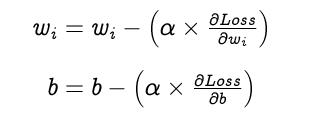
学习率(α)是一个超参数,用来控制权重和偏差的变化量。但是,我们不会在本教程中使用学习率。
func (a *Perceptron) gradW(x []float64, y float64) []float64 { //Calculate Gradients of Weights
pred := a.forwardPass(x)
return scalarMatMul(-(pred-y)*pred*(1-pred), x)
}
func (a *Perceptron) gradB(x []float64, y float64) float64 { //Calculate Gradients of Bias
pred := a.forwardPass(x)
return -(pred - y) * pred * (1 - pred)
}
func (a *Perceptron) train() { //Train the Perceptron for n epochs
for i := 0; i < a.epochs; i++ {
dw := make([]float64, len(a.input[0]))
db := 0.0
for length, val := range a.input {
dw = vecAdd(dw, a.gradW(val, a.actualOutput[length]))
db += a.gradB(val, a.actualOutput[length])
}
dw = scalarMatMul(2 / float64(len(a.actualOutput)), dw)
a.weights = vecAdd(a.weights, dw)
a.bias += db * 2 / float64(len(a.actualOutput))
}
} 装配零件
现在让我们用神经网络对以下数据进行训练和预测。数据有三个输入,只有一个输出属于两个类(0和1)。因此,数据可以在我们的单层感知器上训练。

如你所见,输出Y仅依赖于输入X1。现在我们将在上面的数据上训练我们的神经网络,并检查它在1000个时代之后的表现。为了进行预测,我们只需要用测试输入做一个正向传播。
func main() {
goPerceptron := Perceptron{
input: [][]float64{{0, 0, 1}, {1, 1, 1}, {1, 0, 1}, {0, 1, 0}}, //Input Data
actualOutput: []float64{0, 1, 1, 0}, //Actual Output
epochs: 1000, //Number of Epoch
}
goPerceptron.initialize()
goPerceptron.train()
print(goPerceptron.forwardPass([]float64{0, 1, 0}), "\n") //Make Predictions
print(goPerceptron.forwardPass([]float64{1, 0, 1}), "\n")
} 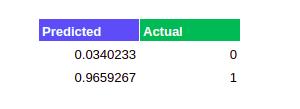
当我们将预测值与实际值进行比较时,我们可以看到我们训练的单层感知器表现良好。我们已经成功地建立了一个神经网络,并对其进行训练,以产生理想的结果。
接下来是什么?
现在你已经完全从头开始创建了自己的神经网络。下面有几件事你应该试试。
- 测试自己的数据
- 尝试除乙状结肠功能外的其他激活功能
- 计算每个历元后的MSE
- 尝试除MSE以外的其他错误函数
- 尝试创建多层感知器
–END–
欢迎大家关注我们的公众号: 为AI呐喊(weainahan)
为了帮助更多缺少项目实战的同学入门Python,我们在头条上创建了一个专栏: , 欢迎大家 点击下方链接 或者 阅读原文 进行试看~


