执行计划(execution plan,也叫查询计划或者解释计划)是数据库执行 SQL 语句的具体步骤,例如通过 索引 还是全表扫描访问表中的数据,连接查询的实现方式和连接的顺序等。如果 SQL 语句性能不够理想,我们首先应该查看它的执行计划。本文主要介绍如何在各种数据库中获取和理解执行计划,并给出进一步深入分析的参考文档。
现在许多管理和开发工具都提供了查看图形化执行计划的功能,例如 MySQL Workbench、Oracle SQL Developer、SQL Server Management Studio、DBeaver 等;不过我们不打算使用这类工具,而是介绍利用数据库提供的命令查看执行计划。
我们先给出在各种数据库中查看执行计划的一个简单汇总:
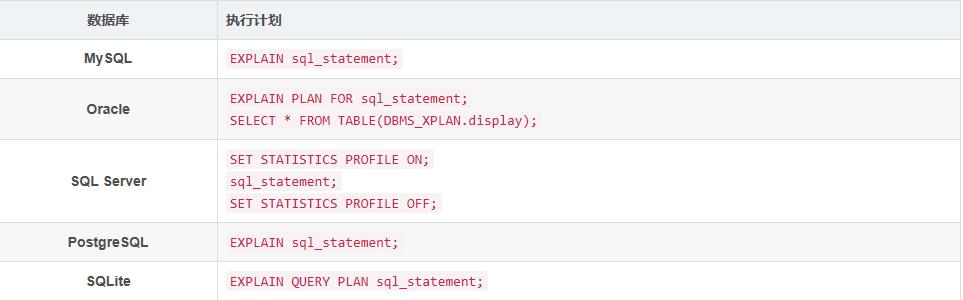
MySQL 执行计划
MySQL 中获取执行计划的方法很简单,就是在 SQL 语句的前面加上EXPLAIN关键字:

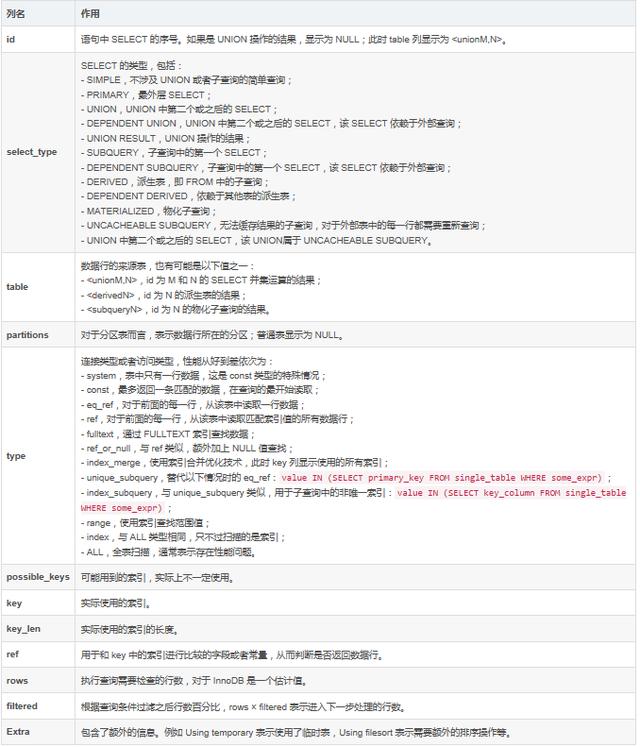
执行该语句将会返回一个表格形式的执行计划,包含了 12 列信息:
接下来,我们要做的就是理解执行计划中这些字段的含义。下表列出了 MySQL 执行计划中的各个字段的作用:
对于上面的示例,只有一个 SELECT 子句,id 都为 1;首先对 employees 表执行全表扫描(type = ALL),处理了 107 行数据,使用 WHERE 条件过滤后预计剩下 33.33% 的数据(估计不准确);然后针对这些数据,依次使用 departments 表的 主键 (key = PRIMARY)查找一行匹配的数据(type = eq_ref、rows = 1)。
使用 MySQL 8.0 新增的 ANALYZE 选项可以显示实际执行时间等额外的信息:
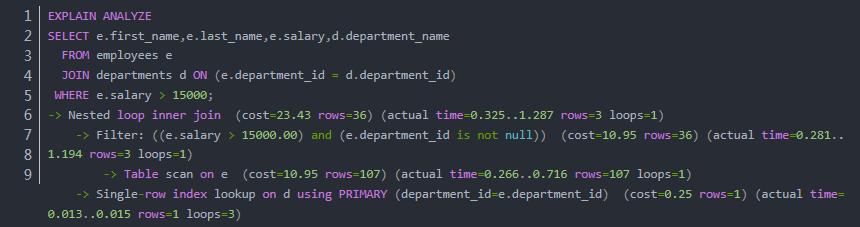
其中,Nested loop inner join 表示使用嵌套循环连接的方式连接两个表,employees 为驱动表。cost 表示估算的代价,rows 表示估计返回的行数;actual time 显示了返回第一行和所有数据行花费的实际时间,后面的 rows 表示迭代器返回的行数,loops 表示迭代器循环的次数。
关于 MySQL EXPLAIN 命令的使用和参数,可以参考 MySQL 官方文档 EXPLAIN 语句。
关于 MySQL 执行计划的输出信息,可以参考 MySQL 官方文档理解查询执行计划。
Oracle 执行计划
Oracle 中提供了多种查看执行计划的方法,本文使用以下方式:
1、使用EXPLAIN PLAN FOR命令生成并保存执行计划;
2、显示保存的执行计划。
首先,生成执行计划:

EXPLAIN PLAN FOR命令不会运行 SQL 语句,因此创建的执行计划不一定与执行该语句时的实际计划相同。
该命令会将生成的执行计划保存到全局的临时表 PLAN_TABLE 中,然后使用系统包 DBMS_XPLAN 中的存储过程格式化显示该表中的执行计划。以下语句可以查看当前会话中的最后一个执行计划:
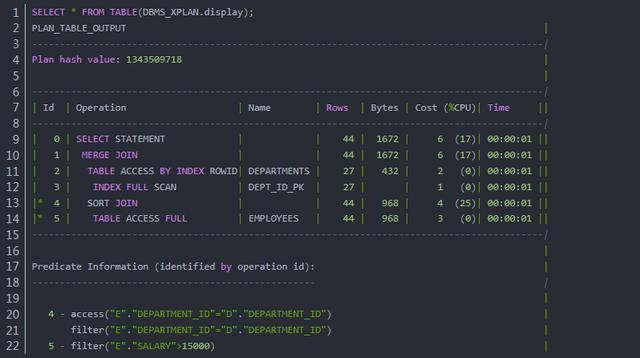
Oracle 中的EXPLAIN PLAN FOR支持 SELECT、UPDATE、INSERT 以及 DELETE 语句。
接下来,我们同样需要理解执行计划中各种信息的含义:
- Plan hash value 是该语句的哈希值。SQL 语句和执行计划会存储在库缓存中,哈希值相同的语句可以重用已有的执行计划,也就是软解析;
- Id 是一个序号,但不代表执行的顺序。执行的顺序按照缩进来判断,缩进越多的越先执行,同样缩进的从上至下执行。Id 前面的星号表示使用了谓词判断,参考下面的 Predicate Information;
- Operation 表示当前的操作,也就是如何访问表的数据、如何实现表的连接、如何进行排序操作等;
- Name 显示了访问的表名、索引名或者子查询等,前提是当前操作涉及到了这些对象;
- Rows 是 Oracle 估计的当前操作返回的行数,也叫基数(Cardinality);
- Bytes 是 Oracle 估计的当前操作涉及的数据量
- Cost (%CPU) 是 Oracle 计算执行该操作所需的代价;
- Time 是 Oracle 估计执行该操作所需的时间;
- Predicate Information 显示与 Id 相关的谓词信息。access 是访问条件,影响到数据的访问方式(扫描表还是通过索引);filter 是过滤条件,获取数据后根据该条件进行过滤。
在上面的示例中,Id 的执行顺序依次为 3 -> 2 -> 5 -> 4- >1。首先,Id = 3 扫描主键索引 DEPT_ID_PK,Id = 2 按主键 ROWID 访问表 DEPARTMENTS,结果已经排序;其次,Id = 5 全表扫描访问 EMPLOYEES 并且利用 filter 过滤数据,Id = 4 基于部门编号进行排序和过滤;最后 Id = 1 执行合并连接。显然,此处 Oracle 选择了排序合并连接的方式实现两个表的连接。
关于 Oracle 执行计划和 SQL 调优,可以参考 Oracle 官方文档《SQL Tuning Guide》。
SQL Server 执行计划
SQL Server Management Studio 提供了查看图形化执行计划的简单方法,这里我们介绍一种通过命令查看的方法:
SET STATISTICS PROFILE ON
以上命令可以打开 SQL Server 语句的分析功能,打开之后执行的语句会额外返回相应的执行计划:
SQL Server 中的执行计划支持 SELECT、INSERT、UPDATE、DELETE 以及 EXECUTE 语句。
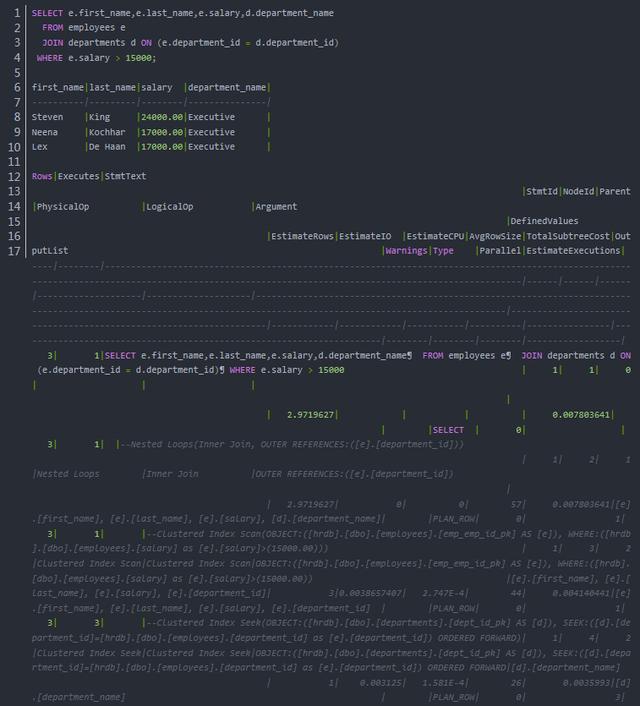
SQL Server 执行计划各个步骤的执行顺序按照缩进来判断,缩进越多的越先执行,同样缩进的从上至下执行。接下来,我们需要理解执行计划中各种信息的含义:
- Rows 表示该步骤实际产生的记录数;
- Executes 表示该步骤实际被执行的次数;
- StmtText 包含了每个步骤的具体描述,也就是如何访问和过滤表的数据、如何实现表的连接、如何进行排序操作等;
- StmtId,该语句的编号;
- NodeId,当前操作步骤的节点号,不代表执行顺序;
- Parent,当前操作步骤的父节点,先执行子节点,再执行父节点;
- PhysicalOp,物理操作,例如连接操作的嵌套循环实现;
- LogicalOp,逻辑操作,例如内连接操作;
- Argument,操作使用的参数;
- DefinedValues,定义的变量值;
- EstimateRows,估计返回的行数;
- EstimateIO,估计的 IO 成本;
- EstimateCPU,估计的 CPU 成本;
- AvgRowSize,平均返回的行大小;
- TotalSubtreeCost,当前节点累计的成本;
- OutputList,当前节点输出的字段列表;
- Warnings,预估得到的警告信息;
- Type,当前操作步骤的类型;
- Parallel,是否并行执行;
- EstimateExecutions,该步骤预计被执行的次数;
对于上面的语句,节点执行的顺序为 3 -> 4 -> 2 -> 1。首先执行第 3 行,通过聚集索引(主键)扫描 employees 表加过滤的方式返回了 3 行数据,估计的行数(3.0841121673583984)与此非常接近;然后执行第 4 行,循环使用聚集索引的方式查找 departments 表,循环 3 次每次返回 1 行数据;第 2 行是它们的父节点,表示使用 Nested Loops 方式实现 Inner Join,Argument 列(OUTER REFERENCES:([e].[department_id]))说明驱动表为 employees ;第 1 行代表了整个查询,不执行实际操作。
最后,可以使用以下命令关闭语句的分析功能:
SET STATISTICS PROFILE OFF
关于 SQL Server 执行计划和 SQL 调优,可以参考 SQL Server 官方文档执行计划。
PostgreSQL 执行计划
PostgreSQL 中获取执行计划的方法与 MySQL 类似,也就是在 SQL 语句的前面加上EXPLAIN关键字:
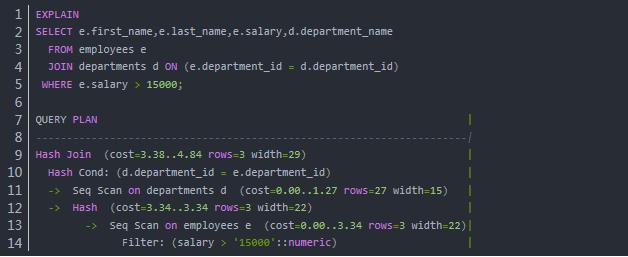
PostgreSQL 中的EXPLAIN支持 SELECT、INSERT、UPDATE、DELETE、VALUES、EXECUTE、DECLARE、CREATE TABLE AS 以及 CREATE MATERIALIZED VIEW AS 语句。
PostgreSQL 执行计划的顺序按照缩进来判断,缩进越多的越先执行,同样缩进的从上至下执行。对于以上示例,首先对 employees 表执行全表扫描(Seq Scan),使用 salary > 15000 作为过滤条件;cost 分别显示了预估的返回第一行的成本(0.00)和返回所有行的成本(3.34);rows 表示预估返回的行数;width 表示预估返回行的大小(单位 Byte)。然后将扫描结果放入到内存 哈希表 中,两个 cost 都等于 3.34,因为是在扫描完所有数据后一次性计算并存入哈希表。接下来扫描 departments 并且根据 department_id 计算哈希值,然后和前面的哈希表进行匹配(d.department_id = e.department_id)。最上面的一行表明数据库采用的是 Hash Join 实现连接操作。
PostgreSQL 中的EXPLAIN也可以使用 ANALYZE 选项显示语句的实际运行时间和更多信息:
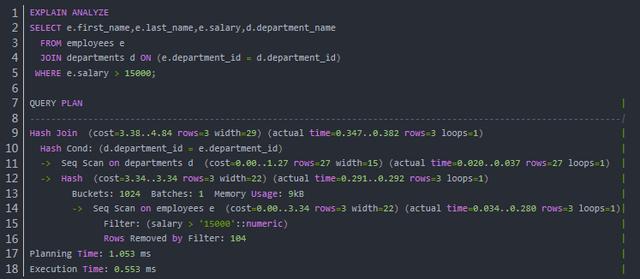
EXPLAIN ANALYZE通过执行语句获得了更多的信息。其中,actual time 是每次迭代实际花费的平均时间(ms),也分为启动时间和完成时间;loops 表示迭代次数;Hash 操作还会显示桶数(Buckets)、分批数量(Batches)以及占用的内存(Memory Usage),Batches 大于 1 意味着需要使用到磁盘的临时存储;Planning Time 是生成执行计划的时间;Execution Time 是执行语句的实际时间,不包括 Planning Time。
关于 PostgreSQL 的执行计划和性能优化,可以参考 PostgreSQL 官方文档性能提示。
SQLite 执行计划
SQLite 也提供了EXPLAIN QUERY PLAN命令,用于获取 SQL 语句的执行计划:

SQLite 中的EXPLAIN QUERY PLAN支持 SELECT、INSERT、UPDATE、DELETE 等语句。
SQLite 执行计划同样按照缩进来显示,缩进越多的越先执行,同样缩进的从上至下执行。以上示例先扫描 employees 表,然后针对该结果依次通过主键查找 departments 中的数据。SQLite 只支持一种连接实现,也就是 nested loops join。
另外,SQLite 中的简单EXPLAIN也可以用于显示执行该语句的虚拟机指令序列:
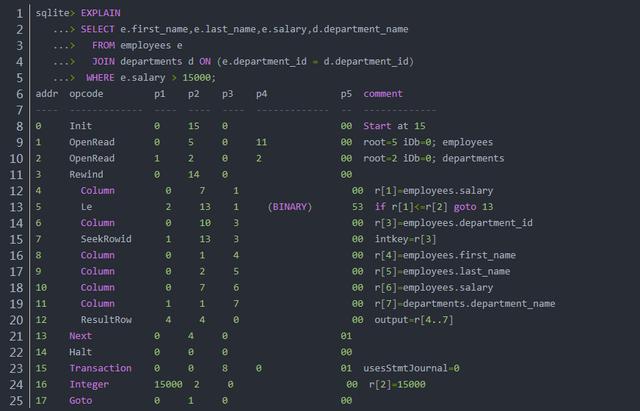
关于 SQLite 的执行计划和优化器相关信息,可以参考 SQLite 官方文档解释查询计划。
需要C/C++ Linux服务器开发学习资料私信“资料”(资料包括C/C++,Linux,golang技术,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,流媒体,CDN,P2P,K8S,Docker,TCP/IP,协程,DPDK,ffmpeg等),免费分享


