以下是我们如何确保我们不断发展的Gojek生态系统对我们的客户、司机伙伴和商户伙伴是安全的。

在 Gojek ,我们不断寻求创新的解决方案,以解决我们不断变化的挑战,为我们的客户、司机伙伴、商户伙伴和我们的整个生态系统保持平台安全。
ClickHouse正是用于这一目的。
它是我们最近部署的技术之一,以打击我们平台上的欺诈者。在这篇文章中,我们旨在描述我们采用ClickHouse的方法,涵盖以下主题。
- 使用ClickHouse的一个简化用例
- 为ClickHouse建立一个数据管道
- 我们的生产设置
我们正在努力解决的问题
多年来,我们的欺诈检测引擎专注于批量检测。几年来,它在帮助我们与欺诈者作斗争方面一直运作良好。然而,随着我们业务复杂性的增加,我们越来越多地看到有必要在近乎实时的情况下抓住欺诈者的用例。实时规则有助于在订单完成之前限制对我们的客户造成的损害。它还有助于我们创造更好的客户体验,因为我们将能够在损害发生之前做出反应。
我们自然而然地查看了我们现有的基础设施。我们有一个现有的数据仓库,支持我们的批量检测逻辑。然而,它不适合频繁和重复的实时查询,因为它是一个相对冷的存储,在数据更新发生之前需要几分钟。对于小型查询,它也需要几秒钟的时间,因为它需要提供资源和处理查询。因此,我们开始寻找另一种近乎实时的解决方案来补充我们基于 批处理 的解决方案。
我们的目标是为近乎实时的 规则引擎 找到一个新的数据存储。我们的用户,即数据分析师,已经表达了他们对新的规则引擎具有以下特性的愿望。
- 基于 SQL ,快速部署,快速执行(<1s),用于相对简单的查询
- 易于调试,有清晰的错误信息
- 将具有数百万数据点的实时数据流与具有数亿数据点的静态参考数据结合起来
- 加入具有数百万数据点的多个实时数据流
- 能够立即看到结果,并通过SQL轻松进行进一步分析
- 频繁地执行查询,间隔时间为几秒钟到不到一分钟
用ClickHouse进行实验
根据分析师给出的要求,我们转向了流处理引擎和在线分析处理( OLAP )数据库。我们以同样的实验场景测试了几个数据库。经过评估,我们选择了ClickHouse,它是一个开源的OLAP数据库,注重性能。
我们选择它作为我们的解决方案是因为以下原因。
- 平稳的 学习曲线 (对于SQL用户)。
- 高性能和横向可扩展性
- 可接受的维护成本
实验方案
我们将用实验中使用的一个简化样本场景来详细说明。在实验中,我们想找到有并发预订的新账户。并发预订被定义为与任何其他预订重叠的预订,预订时间由预订创建事件+预订完成/取消事件定义。新账户被定义为在过去30分钟内创建的账户。因此,我们将查询窗口限制为T-30分钟。
我们有两个相应的 kafka 流,用于客户账户活动和食品预订活动。然而,这些流是通用的流,反映了客户账户活动和食品预订的所有更新。我们也不应该针对这个例子进行任何优化,因为在现实中它们可以被用于多个查询,我们的数据分析师在为新的用例编写查询时有绝对的自由。
当我们在决定实验的模拟规模时,我们研究了数据分析师需要解决的最常见的问题的规模。对于30分钟时间跨度内的大多数实时查询,事件的平均数量约为数万到数千万,这取决于流。因此,我们挑选了典型的流的负载,我们模拟了5万个关于客户账户活动的事件,以及200万个关于预订的事件。我们要运行的查询包括对食品预订事件的自我连接,以找出持续时间,以及通常的选择、过滤和子查询。我们希望查询每5秒执行一次,并且查询应该在1秒内完成。
定义表格和填充数据
为了适应我们的用例,我们从 谷歌 云上的e2-standard-8机器上的一个单节点ClickHouse实例开始。我们必须完成的第一个任务是使测试数据在ClickHouse中可用。表的创建与其他 RDBMS 中通常的数据描述语言( DDL )略有不同,但我们能够通过遵循常见的例子为食品预订事件提出我们的第一个表定义,如下所示。
CREATE TABLE order_log (
customer_id Int32,
order_number String,
status String,
event_timestamp DateTime64(3, ‘UTC’)
) ENGINE = MergeTree()
ORDER BY (event_timestamp)
PARTITION BY toYYYYMMDD(event_timestamp)
SETTINGS index_granularity = 8192
我们还定义了我们的客户账户活动表,如下所示。
CREATE TABLE customer_log (
customer_id Int32,
new_user UInt8,
event_timestamp DateTime64(3, ‘UTC’)
) ENGINE = MergeTree()
ORDER BY (event_timestamp)
PARTITION BY toYYYYMMDD(event_timestamp)
SETTINGS index_granularity = 8192
为了避免在 测试环境 中消耗生产数据的复杂性,我们在这个阶段没有从生产Kafka流中收集数据。相反,我们为两个流创建了一个几小时的数据转储,并使用默认的客户端将其插入到我们的测试ClickHouse实例。在我们的生产设置中,我们已经实现了一个专门的数据摄取器,以应对我们面临的各种挑战,更多的细节可以在本文的后面部分找到。
上面的代码中最陌生的部分是ENGINE= MergeTree()这一行,以及它后面的内容。让我们深入了解这一行的内部情况,并理解它对我们的用例有何帮助。
合并树引擎
ENGINE子句定义了该表所使用的引擎,它定义了数据的存储和查询的方式。MergeTree是ClickHouse中最常见的引擎,它是ClickHouse提供良好性能的原因之一。MergeTree系列中的引擎被设计为以批处理的方式向表中插入非常大量的数据。
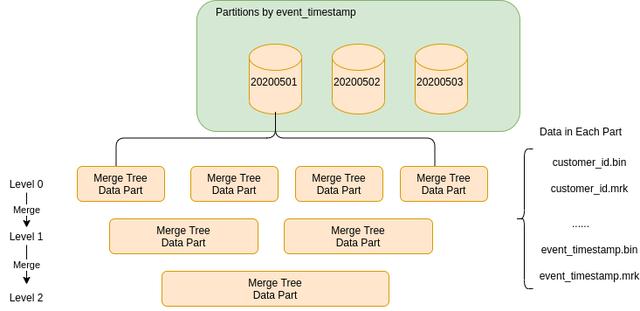
为了理解 MergeTree的工作原理,我们从最熟悉的分区概念开始,分区由PARTITION BY子句定义。这里的分区概念类似于RDBMS中的传统分区,但不同的是,没有为每个分区创建单独的表。它是一种数据的逻辑分组,用于更有效的查询:当一个SELECT查询包含一个由PARTITION BY指定的列上的条件时,ClickHouse会自动过滤掉那些不需要的分区,从而减少读取的数据量。
在每个分区中,会有许多数据部分。因此,一个单一的ClickHouse表由许多数据部分组成。每次插入都会创建一个新的数据部分,如下图所示,它由文件系统中的一个新目录表示。你可以想象,这对点插入来说不是很有效,因为每次插入只包含一条记录。因此,ClickHouse建议批量插入,同时在数据写入后进行优化,在后台应用规则来合并各部分,以提高存储效率。在我们的理解中,这就是为什么引擎中有一个Merge字样。

高效的查询通常依赖于一些专门的数据结构,ClickHouse也不例外。就像其他RDBMS一样, primary key起着重要的作用。主键通常与ORDER BY子句中定义的内容相同,但也可以是它的一个子集。数据按主键在数据部分之间和内部进行排序。然后每个数据部分被逻辑地划分为颗粒,这是最小的不可分割的数据集,ClickHouse在选择数据时读取。ClickHouse不分割行或值,所以每个颗粒总是包含一个整数的行,例如,在一个颗粒中8192行。一个颗粒的第一行被标记为该行的主键值。颗粒在数据部分的位置是由标记表示的。对于每个数据部分,ClickHouse创建了一个索引文件来存储这些标记。想象一下,如果一个查询到达,并且它包含一个关于主键的条件。ClickHouse将能够快速找到数据部分,以及使用标记的颗粒。如果我们将标记保存在内存中,那么查询将快如闪电,ClickHouse可以直接定位磁盘上的数据。
最后,ClickHouse是一个列式数据库。这意味着ClickHouse中的数据是按列而不是按行存储在磁盘上的。这就减少了在查询时从磁盘上读取的数据量,因为不需要读取或跳过不必要的数据。列数据需要与 索引 一起工作。因此,对于每一列,无论它是否在主键中,ClickHouse也会存储相同的标记。这些标记可以让你直接在列文件中找到数据。
下面是对MergeTree结构的总结。
优化性能
一旦我们建立了表和基础设施,我们就开始执行我们的数据分析师在这个例子上准备的查询。经过一些小的调整,我们能够执行该查询(所以我们相信我们的数据分析师也能轻而易举地做到这一点!)。
在我们的第一次尝试中,我们发现性能是合理的。在我们描述的问题的规模下,查询大约需要1.5秒的时间。我们采取了一些调整措施来提高性能。
- 做一个更小的分区。由于我们的规则不需要一天的数据,我们把PARTITION BY子句从每天改为每小时,以减少读取的数据量。
- 使得枚举列(如状态)成为LowCardinality。 LowCardinality是一个上层建筑,改变了数据存储方法和数据处理的规则。ClickHouse将字典编码应用于LowCardinality-columns。它有助于通过减少从磁盘读取的数据大小来提高性能。
- Enable uncompressed cache.在我们的例子中,客户账户活动表相对较小,因此可以被缓存。因此,我们通过设置use_uncompressed_cache为1来启用缓存,以避免每次从磁盘读取表。这可以安全地完成,因为ClickHouse避免了自动缓存大表。我们还注意到,当读取的数据量较小时,这甚至对较大的表也有效。
经过优化,我们成功地将查询时间减少到800ms以下。我们对其性能感到满意,因为它符合我们的性能目标。
ClickHouse数据采集器
正如上一节提到的,我们直接从CLI转储数据进行实验。当我们进行生产设置时,我们认为在ClickHouse中复制Kafka流是很容易的,因为在ClickHouse中有一个Kafka引擎可以使用。然而,在尝试使用它之后,我们决定编写我们自己的基于Golang的应用程序来处理来自Kafka的数据摄入。这个应用程序有简单的职责。
- 作为消费者从Kafka读取数据
- 在其内存中对数据进行短暂的缓冲
- 将数据从内存中冲到ClickHouse
这一决定背后有几个原因。
支持 Protobuf
我们的Kafka流中的数据都是用Protobuf序列化的。如果我们使用内置的Kafka引擎,我们的表定义会像ClickHouse给出的例子一样,如下所示。为了解决模式问题,我们需要把我们的Protobuf定义放在/var/lib/clickhouse/format_ Schema s中,然后创建如下的表。
CREATE TABLE table (
field String
) ENGINE = Kafka()
SETTINGS
kafka_broker_list = ‘kafka:9092’,
kafka_topic_list = ‘topic’,
kafka_group_name = ‘group’,
kafka_format = ‘Protobuf’,
kafka_schema = ‘social:User’,
kafka_row_delimiter = ‘’
它开箱即用,但它在我们的基础设施中产生了一个问题。我们的Protobuf 的Schema存储在一个共同的存储库中,并且由于业务需求的不断变化而不断地更新。我们经常需要添加或更新我们的protobuf模式,从我们的存储库中获取最新版本。我们有时也会更新我们的Kafka主题名称。如果我们使用内置的方法,每次更新都需要在我们的服务器中使用git pull进行手动修改。我们希望能避免这种手动操作。
通过拥有一个单独的数据摄取器,我们能够导入我们编译的protobuf作为一个依赖。拉取最新版本的protobuf模式将由应用程序部署完成,在我们的ClickHouse基础设施上将不需要手动改变。此外,由于ClickHouse不支持Protobuf中的所有数据类型(如地图),拥有一个自定义的数据摄取器有助于我们保持两种格式之间的数据兼容性。我们可以安全地忽略不支持的字段,甚至可以执行定制的映射,如果这些数据在我们的商业案例中是至关重要的。
DB模式的版本控制和性能调控
每当一个新的Kafka流被复制到Clickhouse,我们需要为它创建一个相应的表。像往常一样,我们希望对它进行版本控制,并且能够在末日场景中完全恢复我们的数据库模式,或者当我们需要通过添加新的ClickHouse节点来扩大我们的容量时。我们需要一个应用程序来处理迁移过程,而数据采集器原来是一个好地方。
当我们建立了从给定的Protobuf模式自动生成表定义DDL的功能时,我们看到了一个额外的优势。由于我们的分析师不熟悉性能调整,我们能够在我们的表定义上应用一些性能调整技术,例如将Enums定义为LowCardinality列和编码。这确保了表为通用查询进行了充分的优化。如果数据采集器不存在,这将更难实现。
可配置的批量插入
由于ClickHouse建议分批插入,我们需要为我们想要插入的数据点创建一个缓冲区,并且只以每秒数次的频率进行插入。挑战在于,不同的Kafka流有非常不同的流量,从每秒超过数万条记录到几秒钟一条记录不等。对于高流量的流,我们需要通过改变批次大小和冲刷间隔来控制摄取的频率。另一方面,对于低流量的数据流,我们需要确保数据不会被缓冲太长时间,因为查询是近乎实时地运行。
因此,尽管 logic每个流的配置总是相同的,但我们对不同的流应用不同的配置。在我们的数据摄取器中,我们为每个流提取了以下配置。flush_max_messages控制了缓冲区的最大尺寸,flush_timeout_ms定义了一条记录在缓冲区中可以保留的最大时间。通过改变这些值,我们可以确保每个流的摄取得到很好的处理。
[
{
“brokers”: [
“The list of brokers, depending on the environment”
],
“topic”: “topic to which the ingestor listens to”,
“table_name”: “destination table in ClickHouse”,
“proto_url”: “the Protobuf Schema URL, so that we can deserialize the message”,
“flush_max_message”: Maximum number of messages per batch ,
“flush_timeout_ms”: the interval that the messages are inserted into Clickhouse, if flush_max_message is not fully utilized
}
]
可测试性
独立摄取器的最后但也是重要的好处是,我们能够在投入生产之前充分测试我们的数据摄取。在我们的CI/CD管道中,我们进行了以下工作。
- 创建一个Clickhouse集群
- 迁移数据库模式
- 对于每一个表,在上面描述的配置中找到它的proto
- 为原件填充测试数据并进行摄取
- 核实Clickhouse中是否存在同样的情况
这确保了我们永远不会把有问题的模式推到生产中,而且我们有足够的信心通过这套测试使我们的部署管道完全自动化。此外,这些测试不需要太多的维护,因为所有的表和流的逻辑是统一的。
生产部署
Clickhouse成为我们关于欺诈检测的规则引擎的核心部分。因此,我们的系统需要高度可用,如果一个ClickHouse节点发生故障,不应该有数据损失。ClickHouse允许我们通过配置来解决这个问题。它支持 cluster mode并支持表的`ReplicatedMergeTree`引擎。`ReplicatedMergeTree`引擎只是一个普通的MergeTree引擎,具有跨ClickHouse节点复制数据的能力。使用Apache ZooKeeper ,ClickHouse为我们处理这个问题,我们不需要担心这个问题。
部署还应该处理以下要求。
- 按需摄取数据。我们需要将数据从Kafka实时摄取到Clickhouse。这将是根据用户的要求而进行的,所以我们将经常需要在Clickhouse中添加新的数据流。
- 数据摄取和数据查询将并行进行
- 用户将在生产数据上运行实验,而这些实验不应该影响生产运行时间。
我们用 读写分离 的方式处理了上述要求,你可以在下面看一看。注意我们在图中排除了ZooKeeper。
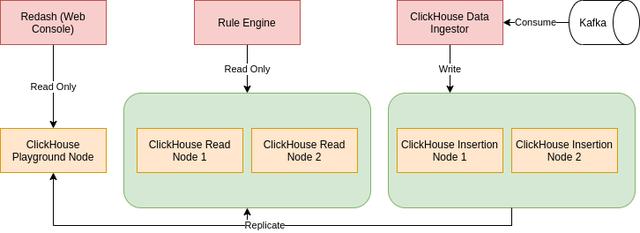
读/写分离
我们的ClickHouse集群目前共包含5个节点,其中两个节点只用于数据摄取,三个节点只用于读取。这些节点都是由同一个ZooKeeper集群管理的。我们将它们的职责明确定义如下。
插入节点
插入节点只用于写入数据,从不用于查询执行。我们确保所有的数据只从我们的数据摄取器写到摄取节点上。在数据被写入插入节点后,它将使用ReplicatedMergeTree引擎自动复制到所有其他节点。插入节点被配置为对所有其他节点具有可见性,因此它总是将数据复制到所有节点。
生产节点
生产节点负责执行我们的数据分析师在其规则中编写的查询。我们从不向生产节点写入数据。我们还确保我们的规则引擎只与生产节点有连接。
游乐场节点
Playground Node拥有与Production Node相同的数据,并且是只读的,但它是用于数据分析师使用数据控制台(如Redash)来试验他们的查询。我们的规则引擎并不连接到Playground Node。Playground Node与Production Node的分离是为了确保实验性查询不会影响生产中查询的运行时间。
能力规划
职责的不同为能力规划创造了灵活性。在处理能力和扩容要求上有很大的不同。下面是我们最终使用的每个节点的能力总结。
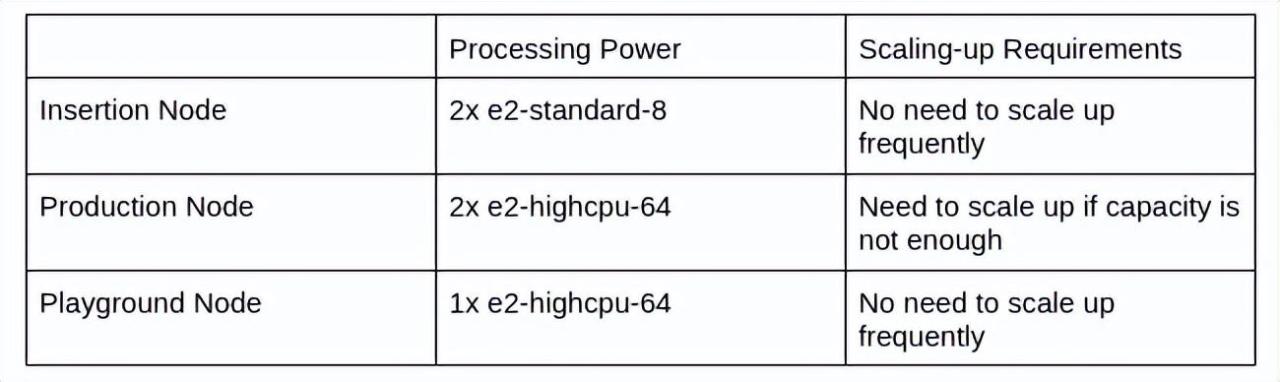
我们根据我们的监测统计数据和样本查询的观察结果来规划我们的容量。首先,插入节点的容量要比其他节点小很多。原因是插入节点执行的工作非常简单,没有查询在那里运行。我们最初对插入节点使用了与其他节点相同的容量,但我们发现它们的利用率非常低。于是我们决定大幅缩减插入节点的规模。此刻,我们的插入节点能够处理每秒数万次的写入,没有问题。
其次,我们为我们的生产节点和游乐场节点选择了高 CPU 设置,而不是标准设置。我们的查询是接近实时的,并且有复杂的逻辑。大多数时候,它不需要超过几十GB的数据大小,但它需要大量的计算能力。我们的监测还显示,我们的查询对CPU的要求比较高,即使是有大量数据的查询。因此,CPU更有可能成为查询处理的瓶颈。使用高cpu设置的决定是根据我们查询的特点和执行查询时使用的资源来决定的。
结束语
我们的ClickHouse集群已经生产了大约一年。到目前为止,我们有几十条近乎实时的规则在上面运行,而更多的规则正在开发或从基于批处理的规则中转换。
我们已经看到,我们目前的ClickHouse设置能够支持我们的业务需求的发展,以对抗不同的欺诈案件。基于Clickhouse的规则已经被整合到许多下游的应用程序中,使我们能够实现过去不可能实现的目标。我们期待着在不久的将来看到更多的用例被纳入我们的ClickHouse集群。


