本来 map 的遍历过程比较简单:遍历所有的 bucket 以及它后面挂的 overflow bucket,然后挨个遍历 bucket 中的所有 cell。每个 bucket 中包含 8 个 cell,从有 key 的 cell 中取出 key 和 value,这个过程就完成了。
但是,现实并没有这么简单。还记得前面讲过的扩容过程吗?扩容过程不是一个原子的操作,它每次最多只搬运 2 个 bucket,所以如果触发了扩容操作,那么在很长时间里,map 的状态都是处于一个中间态:有些 bucket 已经搬迁到新家,而有些 bucket 还待在老地方。
因此,遍历如果发生在扩容的过程中,就会涉及到遍历新老 bucket 的过程,这是难点所在。
我先写一个简单的代码样例,假装不知道遍历过程具体调用的是什么函数:
1 | package main import “fmt” func main() { for name, age := range ageMp { |
执行命令:
1 | go tool compile -S main.go |
得到汇编命令。这里就不逐行讲解了,可以去看之前的几篇文章,说得很详细。
关键的几行汇编代码如下:
1 | // …… // …… // …… |
这样,关于 map 迭代,底层的函数调用关系一目了然。先是调用 mapiterinit 函数初始化迭代器,然后循环调用 mapiternext 函数进行 map 迭代。
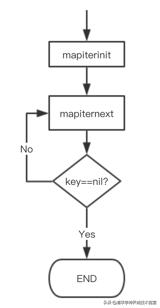
迭代器的结构体定义:
1 | type hiter struct { |
mapiterinit 就是对 hiter 结构体里的字段进行初始化赋值操作。
前面已经提到过,即使是对一个写死的 map 进行遍历,每次出来的结果也是无序的。下面我们就可以近距离地观察他们的实现了。
1 | // 生成随机数 r // 从哪个 bucket 开始遍历 |
例如,B = 2,那 uintptr(1)<<h.B – 1 结果就是 3,低 8 位为 0000 0011,将 r 与之相与,就可以得到一个 0~3 的 bucket 序号;bucketCnt – 1 等于 7,低 8 位为 0000 0111,将 r 右移 2 位后,与 7 相与,就可以得到一个 0~7 号的 cell。
于是,在 mapiternext 函数中就会从 it.startBucket 的 it.offset 号的 cell 开始遍历,取出其中的 key 和 value,直到又回到起点 bucket,完成遍历过程。
源码部分比较好看懂,尤其是理解了前面注释的几段代码后,再看这部分代码就没什么压力了。所以,接下来,我将通过图形化的方式讲解整个遍历过程,希望能够清晰易懂。
假设我们有下图所示的一个 map,起始时 B = 1,有两个 bucket,后来触发了扩容(这里不要深究扩容条件,只是一个设定),B 变成 2。并且, 1 号 bucket 中的内容搬迁到了新的 bucket,1 号裂变成 1 号和 3 号;0 号 bucket 暂未搬迁。老的 bucket 挂在在 *oldbuckets 指针上面,新的 bucket 则挂在 *buckets 指针上面。

这时,我们对此 map 进行遍历。假设经过初始化后,startBucket = 3,offset = 2。于是,遍历的起点将是 3 号 bucket 的 2 号 cell,下面这张图就是开始遍历时的状态:
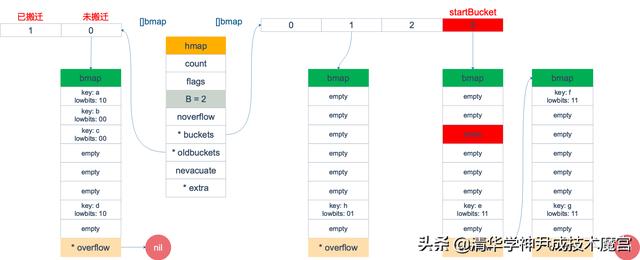
标红的表示起始位置,bucket 遍历顺序为:3 -> 0 -> 1 -> 2。
因为 3 号 bucket 对应老的 1 号 bucket,因此先检查老 1 号 bucket 是否已经被搬迁过。判断方法就是:
1 | func evacuated(b *bmap) bool { |
如果 b.tophash[0] 的值在标志值范围内,即在 (0,4) 区间里,说明已经被搬迁过了。
1 | empty = 0 |
在本例中,老 1 号 bucket 已经被搬迁过了。所以它的 tophash[0] 值在 (0,4) 范围内,因此只用遍历新的 3 号 bucket。
依次遍历 3 号 bucket 的 cell,这时候会找到第一个非空的 key:元素 e。到这里,mapiternext 函数返回,这时我们的遍历结果仅有一个元素:

由于返回的 key 不为空,所以会继续调用 mapiternext 函数。
继续从上次遍历到的地方往后遍历,从新 3 号 overflow bucket 中找到了元素 f 和 元素 g。
遍历结果集也因此壮大:

新 3 号 bucket 遍历完之后,回到了新 0 号 bucket。0 号 bucket 对应老的 0 号 bucket,经检查,老 0 号 bucket 并未搬迁,因此对新 0 号 bucket 的遍历就改为遍历老 0 号 bucket。那是不是把老 0 号 bucket 中的所有 key 都取出来呢?
并没有这么简单,回忆一下,老 0 号 bucket 在搬迁后将裂变成 2 个 bucket:新 0 号、新 2 号。而我们此时正在遍历的只是新 0 号 bucket(注意,遍历都是遍历的 *bucket 指针,也就是所谓的新 buckets)。所以,我们只会取出老 0 号 bucket 中那些在裂变之后,分配到新 0 号 bucket 中的那些 key。
因此,lowbits == 00 的将进入遍历结果集:

和之前的流程一样,继续遍历新 1 号 bucket,发现老 1 号 bucket 已经搬迁,只用遍历新 1 号 bucket 中现有的元素就可以了。结果集变成:

继续遍历新 2 号 bucket,它来自老 0 号 bucket,因此需要在老 0 号 bucket 中那些会裂变到新 2 号 bucket 中的 key,也就是 lowbit == 10 的那些 key。
这样,遍历结果集变成:

最后,继续遍历到新 3 号 bucket 时,发现所有的 bucket 都已经遍历完毕,整个迭代过程执行完毕。
顺便说一下,如果碰到 key 是 math.NaN() 这种的,处理方式类似。核心还是要看它被分裂后具体落入哪个 bucket。只不过只用看它 top hash 的最低位。如果 top hash 的最低位是 0 ,分配到 X part;如果是 1 ,则分配到 Y part。据此决定是否取出 key,放到遍历结果集里。
map 遍历的核心在于理解 2 倍扩容时,老 bucket 会分裂到 2 个新 bucket 中去。而遍历操作,会按照新 bucket 的序号顺序进行,碰到老 bucket 未搬迁的情况时,要在老 bucket 中找到将来要搬迁到新 bucket 来的 key。



