内存泄漏 是一类即使在不再需要内存时也不会释放内存的bug。它们通常是显式的,并且高度可见,这使它们成为开始学习调试的最佳候选案例。Go是一种特别适合于识别内存泄漏的语言,因为它有强大的工具链,它附带了功能强大的工具(pprof),可以轻松地确定内存的使用情况。
我希望这篇文章能够说明如何直观地识别内存,将其缩小到特定的进程,将进程泄漏与工作关联起来,最后使用pprof找到内存泄漏的根源。这篇文章的目的是为了简单地确定内存泄漏的根本原因。pprof概述有意做得很简短,目的是说明它的功能,而不是对其特性的全面概述。
什么是内存泄漏
如果内存无限增长,并且从未达到稳定状态,那么可能存在泄漏。这里的关键是,内存在没有达到稳定状态的情况下增长,并最终通过显式崩溃或影响系统性能而导致问题。
发生内存泄漏的原因有很多。可能存在数据结构无限增长的逻辑泄漏、糟糕的对象引用处理的复杂性导致的泄漏,或者只是因为其他任何原因。不管来源是什么,许多内存泄漏在监控上看都有一个明显的特征: 锯齿状的监控图 。
Debug进程
这篇文章主要探讨如何识别和查明go内存泄漏的根源。我们将主要关注内存泄漏的特征,如何识别它们,以及如何使用go确定它们的根本原因。因此,我们没有涉及复杂的知识点和工具 。
我们分析的目的是逐步缩小问题的范围,减少可能性,直到我们有足够的信息来形成和提出假设。当我们有足够的数据和合理的范围的原因,我们应该形成一个确定的假设。
每一步都会试图找出问题的原因,或这排除一个无关的原因。在这个过程中,我们会形成一系列的假设,它们一开始必然是普遍的,然后逐渐变得更加具体。这是以科学方法为基础的。Brandon Gregg做了一项了不起的工作,涵盖了系统调查的不同方法(主要关注性能)。
我们按照方法论,来提出以下:
· 问一个问题(根据你的经验)
· 形成一个假设(可能的原因)
· 分析假设
· 重复此步骤,直到找到根本原因
如何识别是否存在问题
通常就是找到错误信息。内存泄漏的常见错误是:OOM错误或显式系统崩溃。
OOM Error
错误是问题最明确的指引。虽然用户/应用程序生成的错误可能会在逻辑关闭的情况下产生误报,但是OOM错误实际上是操作系统使用了太多的内存。对于下面列出的错误,它显示为达到cgroup限制和杀死容器。
Dmesg
[14808.063890] main invoked oom-killer: gfp_mask=0x24000c0, order=0, oom_score_adj=0 [7/972] [14808.063893] main cpuset=34186d9bd07706222bd427bb647ceed81e8e108eb653ff73c7137099fca1cab6 mems_allowed=0 [14808.063899] CPU: 2 PID: 11345 Comm: main Not tainted 4.4.0-130-generic #156-Ubuntu [14808.063901] Hardware name: innotek GmbH VirtualBox/VirtualBox, BIOS VirtualBox 12/01/2006 [14808.063902] 0000000000000286 ac45344c9134371f ffff8800b8727c88 ffffffff81401c43 [14808.063906] ffff8800b8727d68 ffff8800b87a5400 ffff8800b8727cf8 ffffffff81211a1e [14808.063908] ffffffff81cdd014 ffff88006a355c00 ffffffff81e6c1e0 0000000000000206 [14808.063911] Call Trace: [14808.063917] [<ffffffff81401c43>] dump_stack+0x63/0x90 [14808.063928] [<ffffffff81211a1e>] dump_header+0x5a/0x1c5 [14808.063932] [<ffffffff81197dd2>] oom_kill_process+0x202/0x3c0 [14808.063936] [<ffffffff81205514>] ? mem_cgroup_iter+0x204/0x3a0 [14808.063938] [<ffffffff81207583>] mem_cgroup_out_of_memory+0x2b3/0x300 [14808.063941] [<ffffffff8120836d>] mem_cgroup_oom_synchronize+0x33d/0x350 [14808.063944] [<ffffffff812033c0>] ? kzalloc_node.constprop.49+0x20/0x20 [14808.063947] [<ffffffff81198484>] pagefault_out_of_memory+0x44/0xc0 [14808.063967] [<ffffffff8106d622>] mm_fault_error+0x82/0x160 [14808.063969] [<ffffffff8106dae9>] __do_page_fault+0x3e9/0x410 [14808.063972] [<ffffffff8106db32>] do_page_fault+0x22/0x30 [14808.063978] [<ffffffff81855c58>] page_fault+0x28/0x30 [14808.063986] Task in /docker/34186d9bd07706222bd427bb647ceed81e8e108eb653ff73c7137099fca1cab6 killed as a result of limit of /docker/34186d9bd07706222bd427bb647ceed81e8e108eb653ff73c7137099fca1cab6 [14808.063994] memory: usage 204800kB, limit 204800kB, failcnt 4563 [14808.063995] memory+swap: usage 0kB, limit 9007199254740988kB, failcnt 0 [14808.063997] kmem: usage 7524kB, limit 9007199254740988kB, failcnt 0 [14808.063986] Task in /docker/34186d9bd07706222bd427bb647ceed81e8e108eb653ff73c7137099fca1cab6 killed as a result of limit of /docker/34186d9bd07706222bd427bb647ceed81e8e108eb653ff73c7137099fca1cab6 [14808.063994] memory: usage 204800kB, limit 204800kB, failcnt 4563 [14808.063995] memory+swap: usage 0kB, limit 9007199254740988kB, failcnt 0 [14808.063997] kmem: usage 7524kB, limit 9007199254740988kB, failcnt 0 [14808.063998] Memory cgroup stats for /docker/34186d9bd07706222bd427bb647ceed81e8e108eb653ff73c7137099fca1cab6: cache:108KB rss:197168KB rss_huge:0KB mapped_file:4KB dirty:0KB writeback:0KB inactive_anon:0KB active_anon:197168KB inacti ve_file:88KB active_file:4KB unevictable:0KB [14808.064008] [ pid ] uid tgid total_vm rss nr_ptes nr_pmds swapents oom_score_adj name [14808.064117] [10517] 0 10517 74852 4784 32 5 0 0 go [14808.064121] [11344] 0 11344 97590 46185 113 5 0 0 main [14808.064125] Memory cgroup out of memory: Kill process 11344 (main) score 904 or sacrifice child [14808.083306] Killed process 11344 (main) total-vm:390360kB, anon-rss:183712kB, file-rss:1016kB
问题 :这个错误是一个经常重复的问题吗?
假设 :OOM 错误很少发生,但是又是一个很严重的错误。可能有某个进程有问题导致的。
预测 :进程内存限制被设置得太低,出现了不正常的颠簸,或者出现了更大的问题。
测试 :在进一步的检查中,有相当多的OOM错误表明这是一个严重的问题,而不是一次性的。
系统内存
识别潜在问题之后的下一步是了解系统范围内的内存使用情况。内存泄漏经常显示”锯齿”模式。峰值对应于应用程序运行,而低谷对应于服务重启。
“锯齿”描述了内存泄漏,特别是与服务部署相对应的内存泄漏。我使用一个测试项目来说明内存泄漏,但即使是缓慢的泄漏,如果范围缩小到足够长的时间范围,也会像锯齿一样。如果时间范围更小,那么在重新启动过程中,它看起来会逐渐上升,然后下降。
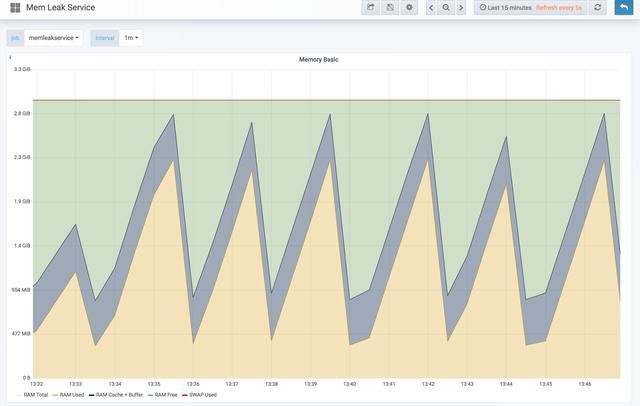
上图显示了锯齿状内存增长的例子。内存会不断增长,而不会停滞不前。这是内存有问题的确凿证据。
问题 :哪个进程(或多个进程)负责内存增长?
测试 :分析每个进程内存使用。dmesg日志中可能有信息表明OOM的目标是一个进程或一类进程。(当然被标记的进程肯定随着OOM被系统Kill了)
每个进程内存使用
一旦怀疑存在内存泄漏,下一步就是确定正在导致系统内存增长的进程。拥有每个进程的历史内存度量是一个关键的需求(基于容器的系统资源可以通过像cAdvisor这样的工具获得)。Go的prometheus客户端默认提供每个进程的内存指标,下面的图表就是从这里获取数据的。
下面的图显示了一个与上面的锯齿状内存泄漏图非常相似的进程:持续增长,直到进程重新启动。
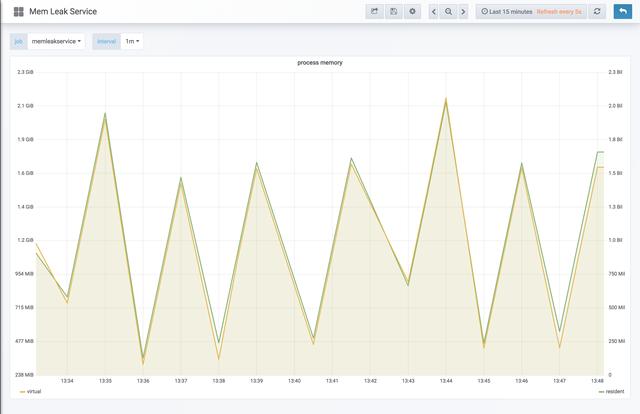
内存是一种重要的资源,可以用来指示异常的资源使用情况,也可以用来作为扩展的维度。此外,拥有内存统计信息有助于告知如何设置基于容器(cgroups)的内存限制。上面图形值的细节可以在度量源代码中找到。识别进程之后,就该深入研究并找出代码中负责内存增长的特定部分。
根本原因分析/根源分析
Go内存分析
普罗米修斯再次向我们提供了go运行时的详细信息,以及我们的进程正在做什么。该图表显示,字节不断地分配到堆,直到重新启动。每个dip都对应于服务流程重新启动。
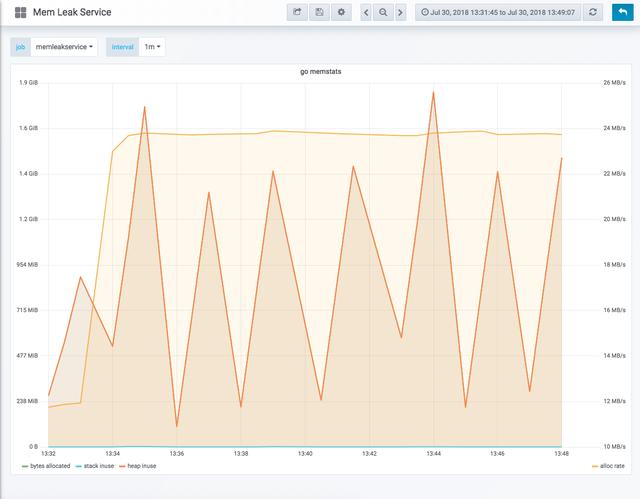
问题 :应用程序的哪些部分正在泄漏内存?
假设 :在一个不断向堆分配内存的例程中存在内存泄漏( 全局变量 或指针,可能通过escape分析可见)
测试 :将内存使用与事件关联起来。
相关工作
建立相关性将有助于通过以下问题来划分问题空间:这是在前端发生的(与事务相关)还是在后台发生的?
确定这一点的一种方法是启动服务并让它空闲,而不应用任何事务负载。服务泄漏了吗?如果是,可以是框架或共享库。我们的示例恰好与事务工作负载有很强的相关性。

上图显示了HTTP请求的数量。它们直接与系统内存增长和时间匹配,并将深入HTTP请求处理作为一个很好的起点。
问题 :应用程序的哪一部分负责堆分配?
假设 :有一个HTTP处理程序不断地向堆分配内存。
测试 :在程序运行期间定期分析堆分配,以跟踪内存增长。
Go内存分配
为了检查分配了多少内存以及这些分配的来源,我们将使用pprof。pprof绝对是一个了不起的工具,也是我个人使用go的主要原因之一。为了使用它,我们必须首先启用它,然后拍一些快照。如果你已经在使用http,启用它真的很简单:
import _ "net/http/pprof"
一旦启用了pprof,我们将在进程内存增长的整个生命周期中定期获取堆快照。堆快照也很简单:
curl > heap.0.pprofsleep 30curl > heap.1.pprofsleep 30curl > heap.2.pprofsleep 30curl > heap.3.pprof
目标是了解记忆是如何在程序的整个生命周期中增长的。让我们检查最近的堆快照:
$ go tool pprof pprof/heap.3.pprof Local symbolization failed for main: open /tmp/go-build598947513/b001/exe/main: no such file or directory Some binary filenames not available. Symbolization may be incomplete. Try setting PPROF_BINARY_PATH to the search path for local binaries. File: main Type: inuse_space Time: Jul 30, 2018 at 6:11pm (UTC) Entering interactive mode (type "help" for commands, "o" for options) (pprof) svg Generating report in profile002.svg (pprof) top20 Showing nodes accounting for 410.75MB, 99.03% of 414.77MB total Dropped 10 nodes (cum <= 2.07MB) flat flat% sum% cum cum% 408.97MB 98.60% 98.60% 408.97MB 98.60% bytes .Repeat 1.28MB 0.31% 98.91% 410.25MB 98.91% main.(*Request Track er).Track 0.50MB 0.12% 99.03% 414.26MB 99.88% net/http.(*conn).serve 0 0% 99.03% 410.25MB 98.91% main.main.func1 0 0% 99.03% 410.25MB 98.91% net/http.(*ServeMux).ServeHTTP 0 0% 99.03% 410.25MB 98.91% net/http.HandlerFunc.ServeHTTP 0 0% 99.03% 410.25MB 98.91% net/http.serverHandler.ServeHTTP
这真是太神奇了。pprof默认为Type: inuse_space,它显示快照时当前内存中的所有对象。我们可以看到这里的字节。重复直接占我们全部内存的98.60% !!
下面是 byte s.Repeat的显示结果:
1.28MB 0.31% 98.91% 410.25MB 98.91% main.(*RequestTracker).Track
它显示轨迹本身有1.28 mb或0.31%,但占用了98.91%的内存!!此外,我们可以看到,http使用的内存甚至更少,但它所负责的内存甚至比Track更多(因为Track是从它调用的)。
pprof提供了许多方法来内窥镜和可视化内存(在使用内存大小,在使用对象数量,分配内存大小,分配内存对象),它允许列出跟踪方法和显示每一行负责多少:
(pprof) list Track
Total: 414.77MB
ROUTINE ======================== main.(*RequestTracker).Track in /vagrant_data/go/src/github.com/dm03514/grokking-go/simple-memory-leak/main.go
1.28MB 410.25MB (flat, cum) 98.91% of Total
. . 19:
. . 20:func (rt *RequestTracker) Track(req *http.Request) {
. . 21: rt.mu.Lock()
. . 22: defer rt.mu.Unlock()
. . 23: // alloc 10KB for each track
1.28MB 410.25MB 24: rt.requests = append (rt.requests, bytes.Repeat([]byte("a"), 10000))
. . 25:}
. . 26:
. . 27:var (
. . 28: requests RequestTracker
. . 29:
这直接找到了罪魁祸首:
1.28MB 410.25MB 24: rt.requests = append(rt.requests, bytes.Repeat([]byte(“a”), 10000))
pprof还允许可视化生成上面的文本信息:
(pprof) svgGenerating report in profile003.svg
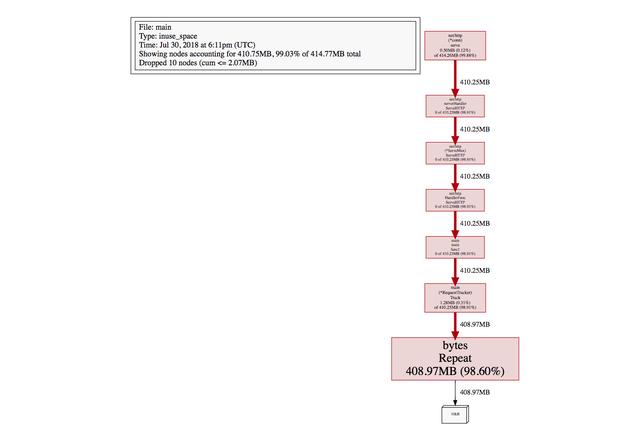
这清楚地显示了占用进程内存的当前对象。现在我们有了罪魁祸首跟踪,我们可以验证它正在将内存分配给全局变量,而不需要清理它,并修复根问题。
解决方案:在每个HTTP请求上,内存被不断地分配给一个全局变量。
我希望这篇文章能够说明用监控图识别内存泄漏和逐步缩小问题范围的这种方法论。最后,我希望大家能够了解pprof的强大,并且在coding中经常使用它来检查性能。
如果大家觉得有帮助,请订阅本头条号。
谢谢。


