服务监控
大家好,我是博哥爱运维。对于运维开发人员来说,不管是哪个平台服务,监控都是非常关键重要的。
在传统服务里面,我们通常会到zabbix、open-falcon、netdata来做服务的监控,但对于目前主流的K8s平台来说,由于服务pod会被调度到任何机器上运行,且pod挂掉后会被自动重启,并且我们也需要有更好的自动服务发现功能来实现服务报警的自动接入,实现更高效的运维报警,这里我们需要用到K8s的监控实现Prometheus,它是基于Google内部监控系统的开源实现。
Prometheus架构图
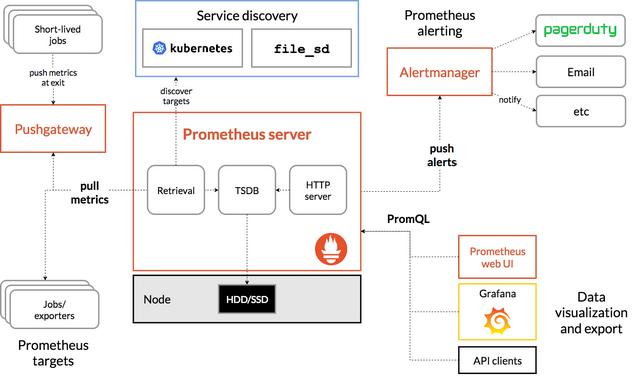
Prometheus是由golang语言编写,这样它的部署实际上是比较简单的,就一个服务的二进制包加上对应的配置文件即可运行,然而这种方式的部署过程繁琐并且效率低下,我们这里就不以这种传统的形式来部署Prometheus来实现K8s集群的监控了,而是会用到 Prometheus-Operator 来进行Prometheus监控服务的安装,这也是我们生产中常用的安装方式。
从本质上来讲Prometheus属于是典型的有状态应用,而其有包含了一些自身特有的运维管理和配置管理方式。而这些都无法通过Kubernetes原生提供的应用管理概念实现自动化。为了简化这类应用程序的管理复杂度,CoreOS率先引入了 Operator 的概念,并且首先推出了针对在Kubernetes下运行和管理Etcd的Etcd Operator。并随后推出了Prometheus Operator。
Prometheus Operator的工作原理
从概念上来讲Operator就是针对管理特定应用程序的,在Kubernetes基本的Resource和Controller的概念上,以扩展Kubernetes api的形式。帮助用户创建,配置和管理复杂的有状态应用程序。从而实现特定应用程序的常见操作以及运维自动化。
在Kubernetes中我们使用Deployment、DamenSet,StatefulSet来管理应用Workload,使用 service ,Ingress来管理应用的访问方式,使用ConfigMap和Secret来管理应用配置。我们在集群中对这些资源的创建,更新,删除的动作都会被转换为事件(Event),Kubernetes的Controller Manager负责监听这些事件并触发相应的任务来满足用户的期望。这种方式我们成为声明式,用户只需要关心应用程序的最终状态,其它的都通过Kubernetes来帮助我们完成,通过这种方式可以大大简化应用的配置管理复杂度。
而除了这些原生的Resource资源以外,Kubernetes还允许用户添加自己的自定义资源(Custom Resource)。并且通过实现自定义Controller来实现对Kubernetes的扩展。
如下所示,是Prometheus Operator的架构示意图:
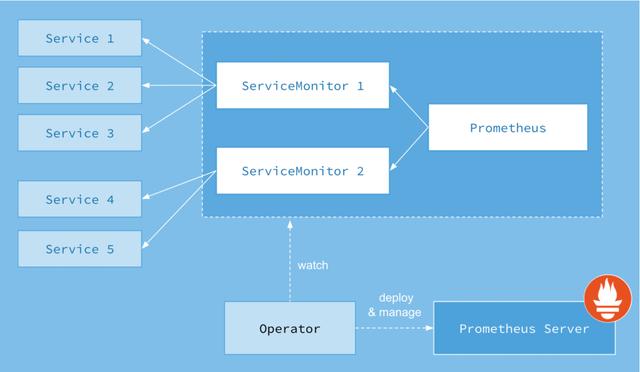
Prometheus的本质就是一组用户自定义的CRD资源以及Controller的实现,Prometheus Operator负责监听这些自定义资源的变化,并且根据这些资源的定义自动化地完成如Prometheus Server自身以及配置的自动化管理工作。
Prometheus Operator能做什么
要了解Prometheus Operator能做什么,其实就是要了解Prometheus Operator为我们提供了哪些自定义的Kubernetes资源,列出了Prometheus Operator目前提供的️4类资源:
- Prometheus:声明式创建和管理Prometheus Server实例;
- ServiceMonitor:负责声明式的管理监控配置;
- PrometheusRule:负责声明式的管理告警配置;
- Alertmanager:声明式的创建和管理Alertmanager实例。
简言之,Prometheus Operator能够帮助用户自动化的创建以及管理Prometheus Server以及其相应的配置。
实战操作篇一
在K8s集群中部署Prometheus Operator
我们这里用 prometheus-operator 来安装整套prometheus服务,建议直接用master分支即可,这也是官方所推荐的
开始安装
1. 解压下载的代码包
unzip kube-prometheus-master.zip
rm -f kube-prometheus-master.zip && cd kube-prometheus-master
2. 这里建议先看下有哪些镜像,便于在下载镜像快的节点上先收集好所有需要的离线docker镜像
# find ./ -type f |xargs grep 'image: '|sort|uniq|awk '{print $3}'|grep ^[a-zA-Z]|grep -Evw 'error|kubeRbacProxy'|sort -rn|uniq
quay.io/prometheus/prometheus:v2.22.1
quay.io/prometheus-operator/prometheus-operator:v0.43.2
quay.io/prometheus/node-exporter:v1.0.1
quay.io/prometheus/alertmanager:v0.21.0
quay.io/fabxc/prometheus_demo_service
quay.io/coreos/kube-state-metrics:v1.9.7
quay.io/brancz/kube-rbac-proxy:v0.8.0
grafana/grafana:7.3.4
gcr.io/google_containers/metrics-server-amd64:v0.2.01
directxman12/k8s-prometheus-adapter:v0.8.2
在测试的几个node上把这些离线镜像包都导入 docker load -i xxx.tar
3. 开始创建所有服务
kubectl create -f manifests/setup
kubectl create -f manifests/
过一会查看创建结果:
kubectl -n monitoring get all
# 附:清空上面部署的prometheus所有服务:
kubectl delete --ignore-not-found=true -f manifests/ -f manifests/setup
访问下prometheus的UI
# 修改下prometheus UI的service模式,便于我们访问
# kubectl -n monitoring patch svc prometheus-k8s -p '{"spec":{"type":"NodePort"}}'
service/prometheus-k8s patched
# kubectl -n monitoring get svc prometheus-k8s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus-k8s NodePort 10.68.23.79 <none> 9090:22129/ TCP 7m43s
点击上方菜单栏 Status — Targets ,我们发现kube-controller-manager和kube-scheduler未发现
monitoring/kube-controller-manager/0 (0/0 up)
monitoring/kube-scheduler/0 (0/0 up)
接下来我们解决下这一个碰到的问题吧
注:如果发现下面不是监控的127.0.0.1,并且通过下面地址可以获取metric指标输出,那么这个改IP这一步可以不用操作
curl 10.0.1.201:10251/metrics curl 10.0.1.201:10252/metrics
# 这里我们发现这两服务监听的IP是127.0.0.1
# ss -tlnp|egrep 'controller|schedule'
LISTEN 0 32768 127.0.0.1:10251 *:* users:(("kube-scheduler",pid=567,fd=5))
LISTEN 0 32768 127.0.0.1:10252 *:* users:(("kube-controller",pid=583,fd=5))
问题定位到了,接下来先把两个组件的监听地址改为0.0.0.0
# 如果大家前面是按我设计的4台NODE节点,其中2台作master的话,那就在这2台master上把systemcd配置改一下
# 我这里第一台master 10.0.1.201
# sed -ri 's+127.0.0.1+0.0.0.0+g' /etc/systemd/system/kube-controller-manager.service
# sed -ri 's+127.0.0.1+0.0.0.0+g' /etc/systemd/system/kube-scheduler.service
# systemctl daemon-reload
# systemctl restart kube-controller-manager.service
# systemctl restart kube-scheduler.service
# 我这里第二台master 10.0.1.202
# sed -ri 's+127.0.0.1+0.0.0.0+g' /etc/systemd/system/kube-controller-manager.service
# sed -ri 's+127.0.0.1+0.0.0.0+g' /etc/systemd/system/kube-scheduler.service
# systemctl daemon-reload
# systemctl restart kube-controller-manager.service
# systemctl restart kube-scheduler.service
# 获取下metrics指标看看
curl 10.0.1.201:10251/metrics
curl 10.0.1.201:10252/metrics
然后因为K8s的这两上核心组件我们是以二进制形式部署的,为了能让K8s上的prometheus能发现,我们还需要来创建相应的service和endpoints来将其关联起来
注意:我们需要将endpoints里面的NODE IP换成我们实际情况的
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-controller-manager
labels:
k8s-app: kube-controller-manager
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10252
targetPort: 10252
protocol : TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-controller-manager
name: kube-controller-manager
namespace: kube-system
subsets:
- addresses:
- ip: 10.0.1.201
- ip: 10.0.1.202
ports:
- name: http-metrics
port: 10252
protocol: TCP
---
apiVersion: v1
kind: Service
metadata:
namespace: kube-system
name: kube-scheduler
labels:
k8s-app: kube-scheduler
spec:
type: ClusterIP
clusterIP: None
ports:
- name: http-metrics
port: 10251
targetPort: 10251
protocol: TCP
---
apiVersion: v1
kind: Endpoints
metadata:
labels:
k8s-app: kube-scheduler
name: kube-scheduler
namespace: kube-system
subsets:
- addresses:
- ip: 10.0.1.201
- ip: 10.0.1.202
ports:
- name: http-metrics
port: 10251
protocol: TCP
将上面的 yaml 配置保存为repair-prometheus.yaml,然后创建它
kubectl apply -f repair-prometheus.yaml
创建完成后确认下
# kubectl -n kube-system get svc |egrep 'controller|scheduler'
kube-controller-manager ClusterIP None <none> 10252/TCP 58s
kube-scheduler ClusterIP None <none> 10251/TCP 58s
记得还要修改一个地方
# kubectl -n monitoring edit servicemonitors.monitoring.coreos.com kube-scheduler
# 将下面两个地方的https换成http
port: https-metrics
scheme : https
# kubectl -n monitoring edit servicemonitors.monitoring.coreos.com kube-controller-manager
# 将下面两个地方的https换成http
port: https-metrics
scheme: https
然后再返回prometheus UI处,耐心等待几分钟,就能看到已经被发现了
monitoring/kube-controller-manager/0 (2/2 up)
monitoring/kube-scheduler/0 (2/2 up)


