最近有个小学弟去某大厂面试了,然后倒在了一个和 LRU 相关实现上。其实我个人觉得 LRU 这个问题很适合作为面试题,因为这个问题既有实用性,而又不像普通的那种看上去用处不大的算法问题,所以很多公司面试都喜欢问题 LRU 的实现问题。
导读
文本包含三个部分,大家可以根据自己的熟悉程度和感兴趣的部分进行选择阅读。
第一部分:简单了解 LRU 是什么,介绍 LRU 的概念。
第二部分:LRU 机制实现分析,介绍 LRU 缓存实现原理及合适的数据结构。
第三部分:Go 实现基于内存的 LRU 缓存,使用 Go 语言对 LRU 缓存的关键部分进行了实现。
简单了解 LRU 是什么
提到 LRU,很多人第一反应会想到 Redis 的淘汰策略,没错,这里的 LRU 和 Redis 使用的 LRU 是相同的概念。
LRU(L east Recently Used )表示的是 最近最久未使用, 或者也有称为最近最少使用,但是为了避免和 LFU 产生歧义,本文中我们都成为最近最久未使用。下面我们通过一个示例来快速描述下 LRU 的概念(如果已经对 LRU 的概念了解,可以跳过这部分):
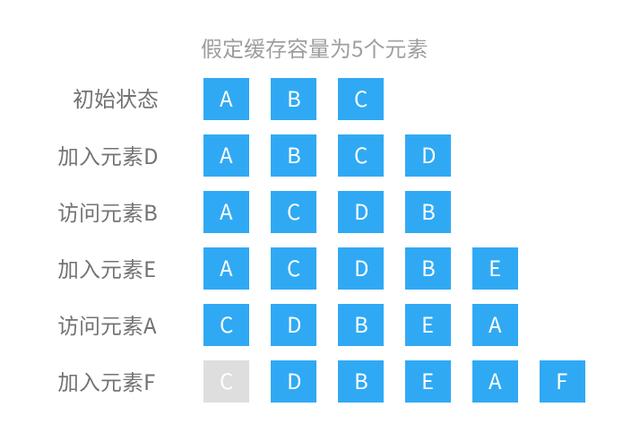
LRU 概念示例
当缓存容量未满时,加入元素则加入到队尾,有元素访问时,则被访问的元素移动到队尾,所以在这个例子中,我们可以认为在队尾的为最近使用的元素,相反在队首的则为最近最久未使用的元素。所以在元素 E 加入后,缓存容量达到最大,此时最近最久未使用的元素为 A,如果再有元素加入时会淘汰掉 A,但是接下来的操作为访问 A 元素,所以此时 A 被移动到队尾,在队首的元素成为了 C,那么接下来在 F 元素加入后,C元素被淘汰。
LRU 机制实现分析
在了解 LRU 的概念之后,我们回到主题,就是实现一个 LRU 的缓存。这里我们以开始提到的面试为例:
首先我们分析下这个题目,要满足 LRU 的淘汰机制,则缓存一定是限定容量的。其次就是要对性能的分析,既然是作为缓存使用的,那么对于 Set 和 Get 的操作的时间复杂度要求一定要控制在 O(1) 级别。( 这里提一个其他问题,我们在解一个问题的时候,一定优先考虑的是最优的实现方式,而不是你认为的最简单的实现方式,这里如果我们使用 O(n) 甚至 O(n^2) 的解法也可以实现,但是这样既不满足实际的使用场景,更不满足面试对你的考核要求 )
再回到这个问题,从最开始我们分析的例子中可以看出,在 LRU 的实现中最重要的一点就是要管理缓存中每个元素的时间属性,所以有人就会考虑,给每个元素记录一个时间戳,然后将元素和时间戳信息存入到一个哈希表中,但是这样虽然满足了 O(1) 的元素访问时间复杂度,但是在元素淘汰的时候就需要遍历所有元素来找到最早的那个元素。
所以我们在对这个问题思考的时候,不要对时间这个概念太过于注重,因为我们并不需要知道每个元素的具体时间,而是只需要知道元素之间的先后时间顺序即可。所以这里我们只需要维护每个元素的先后顺序。那么这里有人就会考虑到使用数组或者链表,这两者都是有顺序的。但是对于数组来讲,数组中的元素移动并不是 O(1) 的操作,所以可能链表会更加适合。但是如果使用链表实现的话,要访问缓存中的元素就需要去遍历链表来找到这个元素。
我们再梳理下这个问题实现的要点:
- Set 和 Get 满足 O(1) 时间复杂度
- 元素顺序调整满足 O(1) 时间复杂度
对于要点1,我们可以使用哈希表来实现,对于要点2,我们可以使用链表来实现。这两种结构都没有办法同时满足两个点。所以我们就需要考虑把这两种数据结构结合起来考虑。(如果有对于Java了解的同学,可以参考LinkedHashMap),这种结构细节可以参考下图:
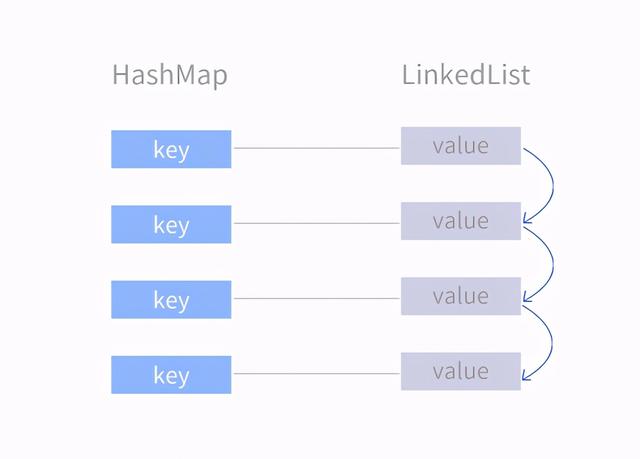
LinkedHashMap
首先创建一个哈希表用了存储键值对,然后将哈希表的 Value 进行链表的关联,这样就可以同时满足上述条件了,而这也是 LRU 的最普遍的实现方式。
Go 实现基于内存的 LRU 缓存
我们了解了实现方法后,就可以着手来实现一个缓存,首先我们需要先定义出这个缓存的结构:
type Cache struct {
mu sync.Mutex
mp map[string]*Node
list *List
size int
}
func (c *Cache) Set(k string, v interface{})
func (c *Cache) Get(k string) interface{}
type Node struct {
Key string
Val interface{}
next *Node
prev *Node
}
type List struct {
head *Node
tail *Node
len int
}
func (l *List) Len() int
func (l *List) MoveToBack(n *Node)
func (l *List) PushBack(n *Node)
func (l *List) RemoveFront() *Node 首先我们定义了 Cache,Node,List 三种结构,其中 List 表示一个双向链表,Node 表示链表中的节点。 这里为什么使用双向链表,因为我们需要的操作是将指定的节点移动到链表最后端,这就需要我们知道一个节点的前置节点和后置节点,所以这里只能使用双向链表 。当然这里也可以使用 Go 标准库提供的 list 对象。这里我们不对链表操作的方法进行实现,大家可以参考标准库的 container/list 包。
接下来我们来看下 Get 方法的实现:
func (c *Cache) Get(key string) interface{} {
c.mu.Lock()
defer c.mu.Unlock()
node, ok := c.mp[key]
if !ok {
return nil
}
c.list.MoveToBack(node)
return node.Val
} Get 方法实现很简单,就是从 Map 中后去指定 Key 的节点,然后将这个节点移动到链表的最后端,最后将这个节点的值返回即可。
然后来实现下 Set 方法:
func (c *Cache) Set(key string, val interface{}) {
c.mu.Lock()
defer c.mu.Unlock()
if existNode, ok := c.mp[key]; ok {
existNode.Val = val
c.list.MoveToBack(existNode)
return
}
if c.list.Len() >= c.size {
frontNode := c.list.RemoveFront()
delete(c.mp, frontNode.Key)
}
node := Node{
Key: key,
Val: val,
}
c.list.PushBack(&node)
c.mp[key] = &node
} Set 方法的实现逻辑为首先检查 Key 在缓存中是否存在,如果存在则更新值并且移动到链表尾端,如果不存在,则先检查缓存容量,如果已经达到最大缓存容量,则将链表头元素删除,并且将这个元素在哈希表中删除,然后将新的节点信息分别添加进链表尾和哈希表中。
至此,一个基于内存的 LRU 缓存的简单实现就完成了,当然这里没有包括链表操作部分的实现,这里大家可以使用标准库提供的 list 包或者参考其他链表实现步骤。总结一下,LRU 缓存我们通过 Map 来存储 key 和 value 的关系来保证快速访问,然后通过双向链表来控制节点顺序,保证 LRU 淘汰策略。
欢迎大家能够交流自己的一些问题和经验,持续学习,共同成长!


