布隆过滤器(Bloom Filter)
还是老规矩,学习一个新知识之前,我们需要了解他的基本概念
我们在布隆过滤器的基本概念中可以看到这么一句话,布隆过滤器可以用于检索一个元素是否在一个集合中。有些小伙伴可能会问:我们直接用 HashMap 去检索元素不就行了吗,为什么还要用布隆过滤器呢?HashMap 确实可以帮助我们实现这个功能,而且 HashMap 通过一次运算就能确定某个元素的位置,也就可以帮助我们检查某个元素是否在一个集合中。那么我们接下来再思考一个问题:如果这个元素集合中有 十亿 个随机数,那我们怎样来判断某个数是否存在呢?
如果元素集合中包含了十亿个随机数的话,那么首先就会给我们带来空间上的问题,按一个随机数占4个子节计算的话,这十亿个随机数就要占用将近4G的存储空间,空间消耗就非常大,这时候就需要用到布隆过滤器(Bloom Filter)来帮助我们解决这个问题了。
布隆过滤器的基本思想
上面我们提到了元素集合中包含了十亿个随机数,如果直接存储这十亿个元素的话就需要占用很大的空间,所以我们肯定不能直接存储元素。那么我们该怎样存储呢?存储方式也是十分巧妙的,可以采用位数组的方式,不直接存储元素,而是存储元素是否存在的状态,这样就可以节约大量的存储空间~(也不知道大神们是怎么想到这么巧妙的办法的)
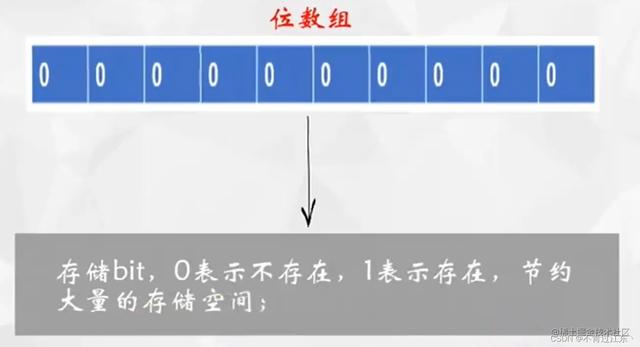
下面我们就一起看看布隆过滤器是怎么判断一个元素是否在一个集合中的
① 现在有一个集合和一个初始状态都为0的位数组

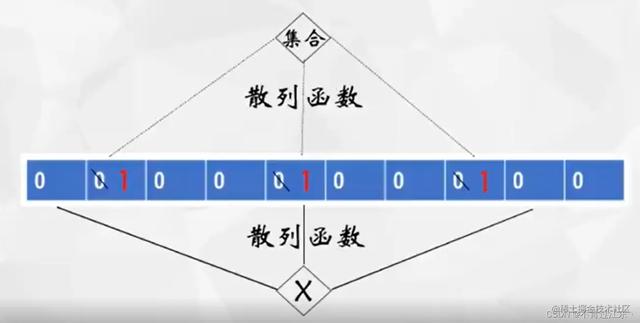
② 集合中的元素经过N个散列函数计算出元素在数组当中的位置,并且将数组中对应位置的0改成1

③ 如果此时需要判断元素X是否存在,那么元素X也会经过这N个散列函数的运算而得到数组中的若干个位置,如果得到的若干个位置中的值均为1,那么则证明元素X很可能存在与集合当中,反之则证明元素X一定不存在于集合当中。如下图所示,此时元素X经过N个散列元素计算出的位置上所存储的值不都是1,那么就证明元素X不存在集合中。
布隆过滤器的特性
在上面我们讲到了布隆过滤器的思想,在第③点中有这样一句话:如果得到的若干个位置中的值均为1,那么则证明元素X 很可能 存在与集合当中。为什么说全都是1的情况是很可能存在,而不是一定存在呢?这就和哈希函数的特点有关系了…
我们都知道哈希函数是可以将任意大小的输入数据转换成特定大小的输出数据的函数(转换后的数据称为哈希值),哈希函数还有以下两个特点:
- 如果根据同一个哈希函数得到的哈希值不同,那么这两个哈希值的原始输入值肯定不同。
- 如果根据同一个哈希函数得到的两个哈希值相等,两个哈希值的原始输入值有可能相等,有可能不相等。
这就类似于 Java 中两个对象的 HashCode 相等,但是对象本身不一定相等的道理。说白了,通过散列函数计算后得到位数组上映射点的值全都是1,不一定是要查询的这个变量之前存进来时设置的,也有可能是其他元素映射的点。这也就引出了布隆过滤器的一个特性: 存在一定的误判 。
在英雄联盟里,你可以完全信任布隆,但是写代码时还是得提防着点
那么我们能不能删除位数组中的元素呢?很显然是不行的,因为在位数组上的同一个点有可能有多个输入值映射,如果删除了会影响布隆过滤器里其他元素的判断结果。这也就是布隆过滤器的另一个特性: 不能删除布隆过滤器里的元素 。
所以我们就可以总结出布隆过滤器的优缺点
优点:在空间和时间方面,都有着巨大的优势。因为不是存完整的数据,是一个二进制向量,能节省大量的内存空间,时间复杂度方面,由于计算时是根据散列函数计算查询的,那么假设有N个散列函数,那么时间复杂度就是O(N);同时在存储元素时存储的不是元素本身,而是二进制向量,所以在一些对保密性要求严格的场景有一定优势。
缺点:存在一定的误判(存进布隆过滤器里的元素越多,误判率越高);不能删除布隆过滤器里的元素,随着使用的时间越来越长,因为不能删除,存进里面的元素越来越多,导致占用内存越来越多,误判率越来越高,最后不得不重置。
布隆过滤器的应用
我们都听说过“缓存穿透”,那我们应该如何解决缓存穿透呢?没错,就是通过布隆过滤器来解决这个问题。
缓存穿透的问题主要是因为传进来的 Key 值在 Redis 中是不存在的,那么就会直接打在数据库上,从而增大数据库的压力。针对这种情况,可以在 Redis 前加上布隆过滤器,预先把数据库中的数据加入到布隆过滤器中,在查询 Redis 之前先通过布隆过滤器判断 Key 值是否存在,如果不存在就直接返回,如果 Key 值存在的话,则按照原来的流程继续执行。
解决缓存穿透利用的就是 布隆过滤器判断结果为不存在的话就一定不存在 这一个特点,但是由于布隆过滤器有一定的误判,所以并不能说完全解决缓存穿透,但是能很大程度缓解缓存穿透的问题。
模拟实现布隆过滤器
最后贴上一段代码,来模拟实现一下布隆过滤器
import java.util.BitSet;
/**
* @description: MyBloomFilter
* @author: 庄霸.liziye
* @create: 2022-04-01 16:50
**/public class MyBloomFilter {
/**
* 一个长度为10亿的比特位
*/ private static final int DEFAULT_SIZE = 256 << 22;
/**
* 为了降低错误率,使用加法hash算法,所以定义一个8个元素的质数数组
*/ private static final int[] seeds = {3, 5, 7, 11, 13, 31, 37, 61};
/**
* 相当于构建8个不同的hash算法
*/ private static HashFunction[] functions = new HashFunction[seeds.length];
/**
* 初始化布隆过滤器的bitmap,即位数组
*/ private static BitSet bitset = new BitSet(DEFAULT_SIZE);
/**
* 添加数据
*
* @param value 需要加入的值
*/ public static void add(String value) {
if (value != null) {
for (HashFunction f : functions) {
//计算 hash 值并修改 bitmap 中相应位置为 true
bitset.set(f.hash(value), true);
}
}
}
/**
* 判断相应元素是否存在
* @param value 需要判断的元素
* @return 结果
*/ public static boolean contains(String value) {
if (value == null) {
return false;
}
boolean ret = true;
for (HashFunction f : functions) {
ret = bitset.get(f.hash(value));
//一个 hash 函数返回 false 则跳出循环
if (!ret) {
break;
}
}
return ret;
}
/**
* 测试
*/ public static void main(String[] args) {
for (int i = 0; i < seeds.length; i++) {
functions[i] = new HashFunction(DEFAULT_SIZE, seeds[i]);
}
//添加1亿个元素
for (int i = 0; i < 100000000; i++) {
add(String.valueOf(i));
}
String id = "123456789";
add(id);
System.out.println("元素 123456789 是否存在:" + contains(id));
System.out.println("元素 234567890 是否存在:" + contains("234567890"));
}
}
class HashFunction {
private int size;
private int seed;
public HashFunction(int size, int seed) {
this.size = size;
this.seed = seed;
}
public int hash(String value) {
int result = 0;
int len = value.length();
for (int i = 0; i < len; i++) {
result = seed * result + value.charAt(i);
}
int r = (size - 1) & result;
return (size - 1) & result;
}
}
复制代码 


