
hbase 是什么?
Apache HBase is an open-source, distributed, versioned, non-relational database modeled after Google's Bigtable: A Distributed Storage System for Structured Data by Chang et al. Just as Bigtable leverages the distributed data storage provided by the Google File System, Apache HBase provides Bigtable-like capabilities on top of hadoop and HDFS.
hbase的应用场景
Use Apache HBase™ when you need random, realtime read/write access to your Big Data. This project's goal is the hosting of very large tables -- billions of rows X millions of columns -- atop clusters of commodity hardware.
hbase的特性
>>>Linear and modular scalability. >>>Strictly consistent reads and writes. >>>Automatic and configurable sharding of tables >>>Automatic failover support between RegionServers. >>>Convenient base classes for backing Hadoop MapReduce jobs with Apache HBase tables. >>>Easy to use Java API for client access. >>>Block cache and Bloom Filters for real-time queries. >>>Query predicate push down via server side Filters >>>Thrift gateway and a REST-ful Web service that supports XML, Protobuf, and binary data encoding options >>>Extensible jruby-based (JIRB) shell >>>Support for exporting metrics via the Hadoop metrics subsystem to files or Ganglia; or via JMX
Hbase window下安装
下载目前最新版本
最新版本
hbase-1.2.6
1. 解压到D:softwarehbase-1.2.6
进入conf目录
配置hbase-site.xml文件
<configuration>
<property>
<name>hbase.rootdir</name>
<value>file:///D:/software/hbase-1.2.6/data</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>D:/software/hbase-1.2.6/data/tmp</value>
</property>
<property>
<name>hbase. zookeeper .quorum</name>
<value>127.0.0.1</value>
</property>
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>D:/software/hbase-1.2.6/data/zoo</value>
</property>
<property>
<name>hbase.cluster.distributed</name>
<value>false</value>
</property>
</configuration>
进入到bin目录
运行:
start-hbase.cmd
2.测试
执行 bin>hbase shell
hbase(main):001:0> create 'mytable', 'data'
0 row(s) in 1.1420 seconds
=> HBase ::Table - mytable
hbase(main):002:0> put 'mytable', 'row1', 'data:1', 'value1'
0 row(s) in 0.0580 seconds
hbase(main):003:0> put 'mytable', 'row2', 'data:2', 'value2'
0 row(s) in 0.0090 seconds
hbase(main):004:0> put 'mytable', 'row3', 'data:3', 'value3'
0 row(s) in 0.0080 seconds
hbase(main):005:0> list
TABLE
mytable
1 row(s) in 0.0200 seconds
=> ["mytable"]
hbase(main):006:0> scan 'mytable'
ROW COLUMN+CELL
row1 column=data:1, timestamp=1416554699558, value=value1
row2 column=data:2, timestamp=1416554715456, value=value2
row3 column=data:3, timestamp=1416554730255, value=value3
3 row(s) in 0.0520 seconds
hbase 有哪些操作?
先看一下hbase的基本操作:创建一个表,删除一个表,增加一条记录,删除一条记录,遍历一条记录。
import java.io.IOException; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.KeyValue; import org.apache.hadoop.hbase.MasterNotRunningException; import org.apache.hadoop.hbase.ZooKeeperConnectionException; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.HBaseAdmin; import org.apache.hadoop.hbase.client.HTable; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.util. byte s; public class HBaseTest { private static Configuration conf = null; /** * Initialization */ static { conf = HBaseConfiguration.create(); } /** * Create a table */ public static void creatTable(String tableName, String[] familys) throws Exception { HBaseAdmin admin = new HBaseAdmin(conf); if (admin.tableExists(tableName)) { System.out.println("table already exists!"); } else { HTableDescriptor tableDesc = new HTableDescriptor(tableName); for (int i = 0; i < familys.length; i++) { tableDesc.addFamily(new HColumnDescriptor(familys[i])); } admin.createTable(tableDesc); System.out.println("create table " + tableName + " ok."); } } /** * Delete a table */ public static void deleteTable(String tableName) throws Exception { try { HBaseAdmin admin = new HBaseAdmin(conf); admin.disableTable(tableName); admin.deleteTable(tableName); System.out.println("delete table " + tableName + " ok."); } catch (MasterNotRunningException e) { e.printStackTrace(); } catch (ZooKeeperConnectionException e) { e.printStackTrace(); } } /** * Put (or insert) a row */ public static void addRecord(String tableName, String rowKey, String family, String qualifier, String value) throws Exception { try { HTable table = new HTable(conf, tableName); Put put = new Put(Bytes.toBytes(rowKey)); put.add(Bytes.toBytes(family), Bytes.toBytes(qualifier), Bytes .toBytes(value)); table.put(put); System.out.println("insert recored " + rowKey + " to table " + tableName + " ok."); } catch (IOException e) { e.printStackTrace(); } } /** * Delete a row */ public static void delRecord(String tableName, String rowKey) throws IOException { HTable table = new HTable(conf, tableName); List<Delete> list = new ArrayList<Delete>(); Delete del = new Delete(rowKey.getBytes()); list.add(del); table.delete(list); System.out.println("del recored " + rowKey + " ok."); } /** * Get a row */ public static void getOneRecord (String tableName, String rowKey) throws IOException{ HTable table = new HTable(conf, tableName); Get get = new Get(rowKey.getBytes()); Result rs = table.get(get); for(KeyValue kv : rs.raw()){ System.out.print(new String(kv.getRow()) + " " ); System.out.print(new String(kv.getFamily()) + ":" ); System.out.print(new String(kv.getQualifier()) + " " ); System.out.print(kv.getTimestamp() + " " ); System.out.println(new String(kv.getValue())); } } /** * Scan (or list) a table */ public static void getAllRecord (String tableName) { try{ HTable table = new HTable(conf, tableName); Scan s = new Scan(); ResultScanner ss = table.getScanner(s); for(Result r:ss){ for(KeyValue kv : r.raw()){ System.out.print(new String(kv.getRow()) + " "); System.out.print(new String(kv.getFamily()) + ":"); System.out.print(new String(kv.getQualifier()) + " "); System.out.print(kv.getTimestamp() + " "); System.out.println(new String(kv.getValue())); } } } catch (IOException e){ e.printStackTrace(); } } public static void main(String[] agrs) { try { String tablename = "scores"; String[] familys = { " grade ", "course" }; HBaseTest.creatTable(tablename, familys); // add record zkb HBaseTest.addRecord(tablename, "zkb", "grade", "", "5"); HBaseTest.addRecord(tablename, "zkb", "course", "", "90"); HBaseTest.addRecord(tablename, "zkb", "course", "math", "97"); HBaseTest.addRecord(tablename, "zkb", "course", "art", "87"); // add record baoniu HBaseTest.addRecord(tablename, "baoniu", "grade", "", "4"); HBaseTest.addRecord(tablename, "baoniu", "course", "math", "89"); System.out.println("===========get one record========"); HBaseTest.getOneRecord(tablename, "zkb"); System.out.println("===========show all record========"); HBaseTest.getAllRecord(tablename); System.out.println("===========del one record========"); HBaseTest.delRecord(tablename, "baoniu"); HBaseTest.getAllRecord(tablename); System.out.println("===========show all record========"); HBaseTest.getAllRecord(tablename); } catch (Exception e) { e.printStackTrace(); } } }
基本概念
HTable
核心概念,实现了Table,用来和hbase的一个单表进行通信。轻量级的,提供获取和关闭方法。
这个类不能通过构造函数直接构建出来。可以通过Connection获取该类的一个实例。参考ConnectionFactory类生成实例:
Connection connection = ConnectionFactory.createConnection(config);
Table table = connection.getTable(TableName.valueOf("table1"));
try {
// Use the table as needed, for a single operation and a single thread
} finally {
table.close();
connection.close();
}
Htable的字段有哪些呢?
public class HTable implements HTableInterface, RegionLocator {
private static final Log LOG = LogFactory.getLog(HTable.class);
protected ClusterConnection connection;
private final TableName tableName;
private volatile Configuration configuration;
private TableConfiguration tableConfiguration;
protected BufferedMutatorImpl mutator;
private boolean autoFlush = true;
private boolean closed = false;
protected int scannerCaching;
private ExecutorService pool; // For Multi & Scan
private int operationTimeout;
private final boolean cleanupPoolOnClose; // shutdown the pool in close()
private final boolean cleanupConnectionOnClose; // close the connection in close()
private Consistency defaultConsistency = Consistency.STRONG;
/** The Async process for batch */
protected AsyncProcess multiAp;
private RpcRetryingCallerFactory rpcCallerFactory;
private RpcControllerFactory rpcControllerFactory;
}
HTableDescriptor包含了HBase表的详细信息,例如所有列家族的描述,该表是否一个分类表,ROOT或者hbase:meta,该表是否只读,当region分片时memstore的最大值,关联的coprocessor等等。
Htable继承并实现了 Table ,Table用来和一个hbase单表进行通信,从表中获取,插入,删除或者扫描数据。使用Connection来获取Table实例,使用完毕后调用close()方法。
Htable也继承实现了 RegionLocator ,RegionLocator用来定位一张Hbase单表的区域位置信息,可以通过Connection获取该类的实例,RegionLocator的getRegionLocation方法返回HRegionLocation。
HRegionLocation
记录HRegionInfo和HRegionServer的主机地址的数据结构。
构造函数:
public HRegionLocation(HRegionInfo regionInfo, ServerName serverName) {
this(regionInfo, serverName, HConstants.NO_SEQNUM);
}
public HRegionLocation(HRegionInfo regionInfo, ServerName serverName, long seqNum) {
this.regionInfo = regionInfo;
this.serverName = serverName;
this.seqNum = seqNum;
}
HRegionInfo
一个区域的信息。区域是在一张表的整个键空间中一系列的键,一个标识(时间戳)区分不同子序列(在区间分隔之后),一个复制ID区分同一序列和同一区域状态信息的不同实例。
一个区域有一个位于的名称,名称由下列的字段组成:
表名(tableName):表的名称。
开始键(startKey):一个区间的开始键。
区域ID(regionId):创建区域的时间戳。
复制ID(replicaId):一个区分同一区域序列的Id,从0开始,保存到不同的服务器,同一个区域的序列可以保存在多个位置中。
加密后的名称(encodedName):md5加密后的区域名称。
除了区域名称外,区域信息还包含:
结束键(endkey):区域的结束键(独有的)
分片(split):区域是否分片
离线(offline):区域是否离线
在0.98版本或者之前,一组表的区域会完全包含所有的键空间,在任何时间点,一个行键通常属于一个单独的区域,该单独区域又属于一个单独的服务器。在0.99+版本,一个区域可以有多个实例(叫做备份),因此一行可以对应多个HRegionInfo。这些HRI除了备份Id字段外都可以共用字段。若备份Id未设置,默认为0。
/**
* The new format for a region name contains its encodedName at the end.
* The encoded name also serves as the directory name for the region
* in the filesystem.
*
* New region name format:
* <tablename>,,<startkey>,<regionIdTimestamp>.<encodedName>.
* where,
* <encodedName> is a hex version of the MD5 hash of
* <tablename>,<startkey>,<regionIdTimestamp>
*
* The old region name format:
* <tablename>,<startkey>,<regionIdTimestamp>
* For region names in the old format, the encoded name is a 32-bit
* JenkinsHash integer value (in its decimal notation, string form).
*<p>
* **NOTE**
*
* The first hbase:meta region, and regions created by an older
* version of HBase (0.20 or prior) will continue to use the
* old region name format.
*/
/** Separator used to demarcate the encodedName in a region name
* in the new format. See description on new format above.
*/
private static final int ENC_SEPARATOR = '.';
public static final int MD5_HEX_LENGTH = 32;
/** A non-capture group so that this can be embedded. */
public static final String ENCODED_REGION_NAME_REGEX = "(?:[a-f0-9]+)";
// to keep appended int's sorted in string format. Only allows 2 bytes to be
// sorted for replicaId
public static final String REPLICA_ID_FORMAT = "%04X";
public static final byte REPLICA_ID_DELIMITER = (byte)'_';
private static final int MAX_REPLICA_ID = 0xFFFF;
static final int DEFAULT_REPLICA_ID = 0;
private byte [] endKey = HConstants.EMPTY_BYTE_ARRAY;
// This flag is in the parent of a split while the parent is still referenced
// by daughter regions. We USED to set this flag when we disabled a table
// but now table state is kept up in zookeeper as of 0.90.0 HBase.
private boolean offLine = false;
private long regionId = -1;
private transient byte [] regionName = HConstants.EMPTY_BYTE_ARRAY;
private boolean split = false;
private byte [] startKey = HConstants.EMPTY_BYTE_ARRAY;
private int hashCode = -1;
//TODO: Move NO_HASH to HStoreFile which is really the only place it is used.
public static final String NO_HASH = null;
private String encodedName = null;
private byte [] encodedNameAsBytes = null;
private int replicaId = DEFAULT_REPLICA_ID;
// Current TableName
private TableName tableName = null;
/** HRegionInfo for first meta region */
public static final HRegionInfo FIRST_META_REGIONINFO =
new HRegionInfo(1L, TableName.META_TABLE_NAME);
先了解一下HBase的数据结构:

组成部件说明:
Row Key: Table主键 行键 Table中记录按照Row Key排序
Timestamp: 每次对数据操作对应的时间戳,也即数据的version number
Column Family: 列簇,一个table在水平方向有一个或者多个列簇,列簇可由任意多个Column组成,列簇支持动态扩展,无须预定义数量及类型,二进制存储,用户需自行进行类型转换。
行操作
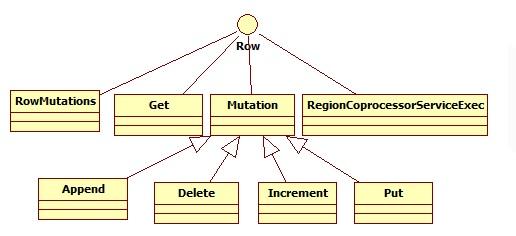
Get用来对一个单独的行进行Get操作:
获取一个row的所有信息前,需要实例化一个Get对象。
获取特定家族的所有列,使用addFamily(byte[])。
获取特定列,使用addColumn(byte[], byte[])
获取在特定的时间戳内的一系列列,使用setTimeRange(long, long)
获取在特定时间戳的列,使用setTimeStamp(long)
限制返回的列数,使用setMaxVersions(int)
增加过滤器,使用setFilter(Filter)。
Put用来对一个单独的列进行Put操作:
使用Put前需初始化Put对象,来插入一行使用add(byte[], byte[], byte[]),若设定时间戳则使用add(byte[], byte[], long, byte[])。
Append 操作:
对一行增加多个列,使用add(byte[], byte[], byte[]);
参考文献:
【1】
【2】
【3】


