前言
这几天在翻 github 的时候, 碰巧看到了 php 的源码, 就 down 下来随便翻了翻. 地址:
那么 PHP 中什么玩意最引人注目嘞? 一定是数组了, PHP 中的数组太强大了, 于是就想着不如进去看看数组的实现部分. 这篇文章打算全程针对代码进行解读了.
以下代码基于最新 php8.1 . commitId: ea62b8089acef6551d6cece5dfb2ce0b040a7b83 .感兴趣的可自行下载查看.
探究
首先, 如此强大的数组功能应该是有单独文件进行定义的. 因此搜索了 array.h array.c 文件, 哎, array.c 文件是存在的.
查看后发现, array.c 文件中定义了 PHP 数组的系统函数, 比如 krsort count 等等. 但是, array 的实现又在哪里呢?
随便找一个方法 array_flip , 其中第一行定义变量如下:
zval *array;
也就是说, 方法接收的参数是 结构体 zval . 但是, zval 这个结构体看名字应该是变量而不是数组啊. 果然, 再看下面变量的使用:
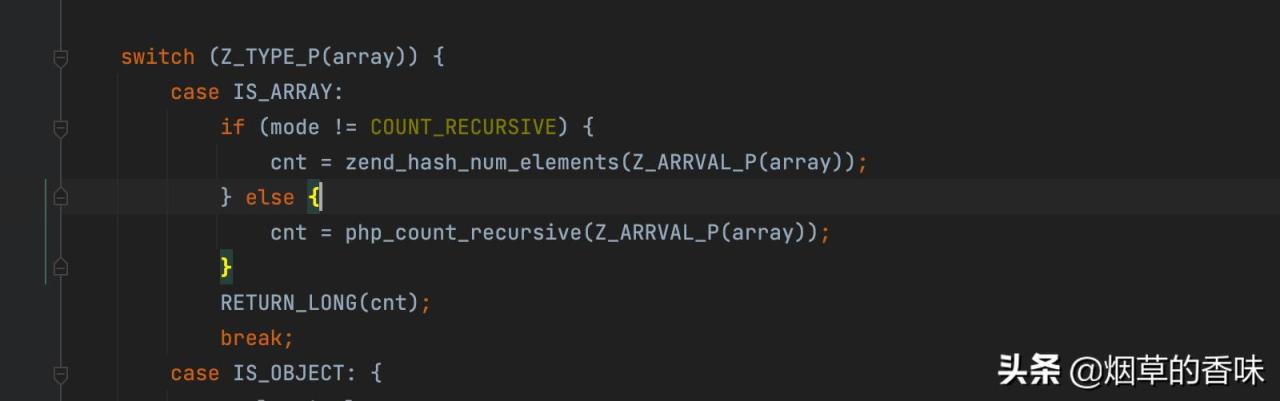
拿到变量后, 判断变量的类型, 会根据不同类型进行不同的处理.
那么这里为什么不直接接数组类型呢? 因为 PHP 的弱类型, 所有的变量都是 zval , 其实际类型定义在 zval 结构体中. 这里顺便看一下 zval 结构体的实现:
(从这里开始, 下方所有内容不再详细说明查找过程, 反正就七找八找的)
zval
zval 结构体定义在 zend_types.h 文件中, 这就是 PHP 弱类型的秘密了. 对其中各个部分的个人理解, 以注释的形式添加到代码中了.
/*
* 其在 大端和小端 使用了不同的顺序定义.
* 想来是为了解决大小端环境的问题, 保证在不同的设备上可以读取到相同的位
*/#ifdef WORDS_BIGENDIAN
# define ZEND_ENDIAN_LOHI_3(lo, mi, hi) hi; mi; lo;
#else
# define ZEND_ENDIAN_LOHI_3(lo, mi, hi) lo; mi; hi;
#endif
// 对不同变量类型的定义
/* Regular data types: Must be in sync with zend_variables.c. */#define IS_UNDEF0
#define IS_NULL1
#define IS_FALSE2
// ...
// 进行结构体的重命名
typedef struct _zval_struct zval;
/*
* 变量联合体定义.
* 此联合体和保存各种类型的变量
*/typedef union _zend_value {
zend_long lval; // 8B
double dval; // 8B
zend_refcounted *counted; // 引用计数. 8B
zend_string *str; // 字符串. 8B
zend_array *arr;
zend_object *obj;
zend_resource *res;
zend_reference *ref;
zend_ast_ref *ast;
zval *zv;
void *ptr;
zend_class_entry *ce;
zend_function *func;
struct {
uint32_t w1;
uint32_t w2;
} ww; // 8B
} zend_value; // 综上: 8B
// 变量的结构体
struct _zval_struct {
// 使用 zend_value 联合体保存当前元素的值. 8B
zend_value value;/* value */ /*
* 用来保存变量类型
* 这里为什么要使用联合体呢?
* 众所周知, 联合体中变量是共用内存的
* 而其中的两个内容都是4字节的.
* 因此, 我认为是为了方便使用.
* 在统一操作时可使用 type_info, 有可以通过结构体分别获取每一位
* (不过这只是个人理解, 没有进行求证)
*/union {
uint32_t type_info; // 4B
struct {
ZEND_ENDIAN_LOHI_3(
// 用来保存当前变量的类型. 也就是上面的一批定义. 1B
zend_uchar type,/* active type */ // 当前变量的一些标志位. 如: 常量类型/不可修改 等等. 1B
zend_uchar type_ FLAGS ,
union { // 2B
uint16_t extra; /* not further specified */} u)
} v; // 4B
} u1; // 4B
// 上面两个结构体共占用 12B, 而内存对其需要16B, 因此有4个字节是空着的
// 下面的联合体可以将这4B 充分利用.
// 这里根据不同的变量类型使用不同的变量. 比如: next, 在下面介绍数组的时候有用
union {
uint32_t next; /* hash collision chain */uint32_t cache_slot; /* cache slot (for RECV_INIT) */uint32_t opline_num; /* opline number (for FAST_CALL) */uint32_t lineno; /* line number (for ast nodes) */uint32_t num_args; /* arguments number for EX(This) */uint32_t fe_pos; /* foreach position */uint32_t fe_iter_idx; /* foreach iterator index */uint32_t property_guard; /* single property guard */uint32_t constant_flags; /* constant flags */uint32_t extra; /* not further specified */} u2;
};
zend_array
在查看 zval 的时候, 应该注意到其中的 zend_array 类型了. 不用看了, 看名字也知道, 数组就是它了.
为了在下面查看数组结构体时, 这里对 PHP 中数组的实现做一个简短的介绍.
结构介绍#
众所周知, PHP 中数组是通过 hashTable 实现的, 但是 hashTable 又是如何保证读取顺序的呢? 通过如下两个数组实现了一个有序 hash :
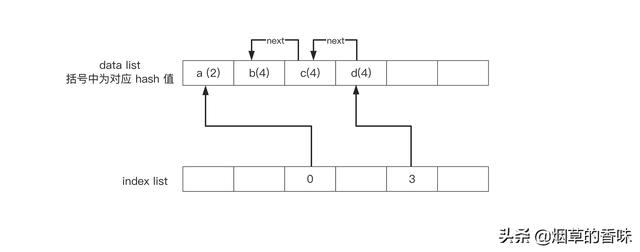
每次新增元素都向 data 数组 后面添加, 这样 foreach 的时候遍历 data 数组 , 读到的顺序就和放入的顺序是一样的了.
但是, 这不就是数组么? hash 呢? 如何保证读取的高效呢? 在第二个 hash 数组 中, HASH 数组 中保存的是元素在 data 数组 中的索引.
从数组中读取key a 元素的步骤是这样的:
- 计算 a 的 hash 值为2
- idx=indexList[2]
- data=dataList[idx]
那么 hash 冲突又是如何解决的呢? 对于哈希冲突, 目前有 开放寻址 和 链表 两种处理方式, 不过大部分实现都采用 链表 的方式. 这里也不例外.
数组中, b c d 的 hash 值均为 4 , 他们三个直接组成一个链表. 而 index 数组 中保存链表头的地址.
好, PHP 数组的实现结构概念部分介绍完了. 接下来看一下 PHP 是如何实现的吧.
结构体#
在介绍结构体代码之前, 还是得先上一个图. 在上方介绍中存在 dataList indexList 两个数组. 在 PHP 的实现中, 或许是为了节省空间. 将这两个数组合并成了一个, 只需要记录一个地址. 如下图:
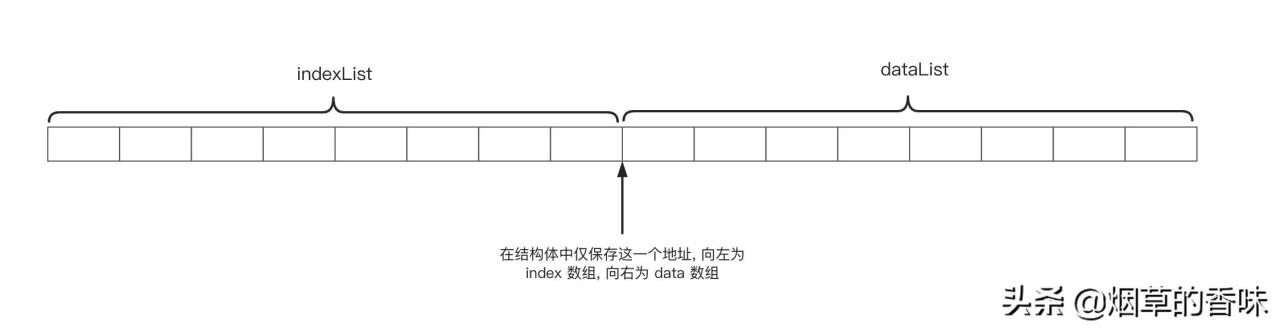
上图的说明是为了防止你看到结构体中的 union 会懵. 一样的, 我将自己的理解放到注释中了.
typedef struct _zend_array zend_array;
// 没毛病, 数组的别名就是 hashTable
typedef struct _zend_array HashTable;
// 用来保存数组中的数据
typedef struct _Bucket {
// 当前元素值
zval val;
// 当前元素的 hash
zend_ulong h; /* hash value (or numeric index) */ // 元素的 key
zend_string *key; /* string key or NULL for numerics */} Bucket;
typedef struct _zend_array HashTable;
struct _zend_array {
zend_refcounted_h gc; // 对数组进行引用计数. 8B
union {
struct {
ZEND_ENDIAN_LOHI_4(
/*
* 标志位. 其常量定义如下:
* #define HASH_FLAG_CONSISTENCY ((1<<0) | (1<<1))
* #define HASH_FLAG_PACKED (1<<2)
* #define HASH_FLAG_UNINITIALIZED (1<<3)
* #define HASH_FLAG_ static _KEYS (1<<4) // long and interned strings
* #define HASH_FLAG_HAS_EMPTY_IND (1<<5)
* #define HASH_FLAG_ALLOW_COW_VIOLATION (1<<6)
*/zend_uchar flags,
zend_uchar _unused,
zend_uchar nIteratorsCount,
zend_uchar _unused2)
} v;
uint32_t flags; // 4B
} u; // 4B
// 用来保存数组中的元素信息. 这是一个数组, 记录数组首地址.
// 关于这里的 两个数组为什么使用 联合体记录, 在上图中解释了.
union {
// 用来读取上方的 hashList 8B
uint32_t *arHash; /* hash table (allocated above this pointer) */ // 用来读取上方的 dataList 8B
Bucket *arData; /* array of hash buckets */ // 当前数组中其实保存了两个数组, 但是对于key是连续数字的数组来说, arrHash 其实并不需要. 可以直接使用数组存储
// 所以使用了 arPacked 来表示key全部为数字的, 通过标识位 HASH_FLAG_PACKED 来标识. 以节省内存占用
// 所以, 其实对于连续数字的数组, 其底层真的是数组, 而不是 hashTable
// 这里你可以简单的实验一下, 通过构造一个连续数字索引的数字, 然后在给其赋值一个key 为 字符串 的元素, 通过 memory _get_usage 函数查看内存的变化. 很明显的.
zval *arPacked; /* packed array of zvals */}; // 8B
// 数组中存储的元素个数. 4B
uint32_t nNumOfElements;
/*
* 向数组中添加元素时, 使用的数组索引.
* 此变量与 nNumOfElements 的区别是,
* 当数组中元素释放的时候, 比如 unset 操作.
* nNumOfElements 进行减一操作, 而 nNumUsed 变量不变.
* 同时, 元素也并没有从数组中抹去, 仅仅是将其 type 修改为 IS_UNDEF
* 等到下一次内存扩充的时候, 在将这些元素释放掉, 以保证释放的高效
* 4B
*/ uint32_t nNumUsed;
// 记录当前数组已经分配的地址大小. 2的 n 次幂(分配地址每次乘2). 4B
uint32_t nTableSize;
// 计算 key 的 hash 散列值时使用(在下方具体介绍). 4B
uint32_t nTableMask;
// 数组遍历是使用的 游标 , 如调用函数: next/prev/end/reset/current 等. 4B
uint32_t nInternalPointer;
/*
* 用来记录下一个元素插入时的默认 key.
* 比如代码:
* $arr = [];
* $arr[] = 1; // 相当于 $arr[0]=1;
* 但是, 你或许会疑惑, 这还需要单独记录么? 直接使用数组的大小计算不就行了?
* 再看一段:
* $arr = [];
* $arr['a'] = 1;
* $arr[] = 2; // 相当于 $arr[0] = 1;
* 是不是懂了??
* 8B
*/zend_long nNextFreeElement;
/*
* 此方法在数组中的元素更新或删除时调用.
* 若元素是引用计数的类型, 会更新其引用计数
* 相当于元素的 析构函数
* 8B
*/dtor_func_t pDestructor;
}; // 56B
nTableMask
nTableMask 变量在计算元素的的散列值(在 indexList 中的索引)时使用.
首先在上面, indexList 与 dataList 大小相等, 且都等于 nTableSize . 也就是说, 散列值 的取值范围为: [-nTableSize, -1] .
PHP 中是如何处理的呢? 其计算规则为: nIndex = h | ht->nTableMask; 其中 nTableMask=-nTableSize .
这里简单证明一下, 还记得上面提到过, nTableMask 的取值为2的 n 次幂. 我们假设长度为16. (为了简化逻辑, 以8byte 为例).
那么, nTableMask 等于 -16, 其二进制补码表示为: 11110000 . 我们分别使用两个极端值和 nTableMask 进行或运算.
11110000 与 00000000 进行或运算, 结果为 11110000 , 其值等于-16.
11110000 与 01111111 进行或运算, 结果为 11111111 , 其值等于 -1.
刚好与需要的取值范围相等. 既然是通过变量 nTableSize 计算得到的, 为什么要单独使用变量记录呢? 我想是为了效率吧. 毕竟 hash 取值的操作是很频繁的. 而位运算是很快的, 如果加上额外的计算操作会导致其效率下降.
数组插入操作#
通过上面的介绍, 对于其插入操作应该如何实现想比心中有数了. 这里简单罗列一下:
// 判断需要时对数组进行扩容
#define ZEND_HASH_IF_FULL_DO_RESIZE(ht)\
if ((ht)->nNumUsed >= (ht)->nTableSize) {\
zend_hash_do_resize(ht);\
}
static zend_always_inline zval *_zend_hash_add_or_update_i(HashTable *ht, zend_string *key, zval *pData, uint32_t flag)
{
// 一些额外处理...
// 需要时对数组进行扩充
ZEND_HASH_IF_FULL_DO_RESIZE(ht);/* If the Hash table is full, resize it */
add_to_hash:
// INTERNED 字符串不会被销毁, 用来实现相同字符串共用内存
// 当数组中所有key 都是 INTERNED 字符串
// 那么数组释放的时候就不需要释放 key 了, 同时数组 copy 的时候也不需要增加字符串引用计数
// HASH_FLAG_STATIC_KEYS 标记位就是用来标记数组中所有 key 均为 INTERNED 字符串
// 若当前字符串不是 INTERNED 的, 则修改数组的标记位
if (!ZSTR_IS_INTERNED(key)) {
zend_string_addref(key);
HT_FLAGS(ht) &= ~HASH_FLAG_STATIC_KEYS;
}
// 获取当前元素的 dataList index
idx = ht->nNumUsed++;
// 数组中元素内容增加
ht->nNumOfElements++;
// 元素赋值
arData = ht->arData;
p = arData + idx;
p->key = key;
p->h = h = ZSTR_H(key);
// 计算 hashList index
nIndex = h | ht->nTableMask;
// 这一步就是用来处理 hash 冲突的
// 将当前元素的 next 指向原来 hashList 中的值
Z_NEXT(p->val) = HT_HASH_EX(arData, nIndex);
// 更新 hashList
HT_HASH_EX(arData, nIndex) = HT_IDX_TO_HASH(idx);
// 对 val 进行赋值.
// 这里判断标志位 HASH_LOOKUP, 然后将 val 置为 null. 这里看了半天没看懂其作用, 如果有知道的还望不吝赐教
if (flag & HASH_LOOKUP) {
ZVAL_NULL(&p->val);
} else {
ZVAL_COPY_VALUE(&p->val, pData);
}
return &p->val;
}
其他的数组操作函数这里就不再罗列了, 感兴趣的下载源码自己看一下吧.
hash 函数#
在上面查看函数 zend_hash_do_resize 的时候, 突然想到了一个有意思的事情, 函数每次扩容都是乘2的操作. 如果说, 有一个长度为65536的数组, 每一个 key 的散列值计算后均为0, 那么 hashTable 不就退化为链表了么?
具体是什么思路呢? 第一个元素 key 为0, 那么根据长度取模, 第二个元素就是 65536, 第三个元素就是 65536*2, 这样每次插入的时候都需要遍历链表, 导致插入效率变慢. 整个demo 试一下.
<?php
// 统计函数的耗时
function echoCallCostTime($msg, $call){
$startTime = microtime(true) * 1000;
$call();
$endTime = microtime(true) * 1000;
$ diff Time = $endTime - $startTime;
echo "$msg 耗时 $diffTime", PHP_EOL;
}
$size = 2**16;
$array = [];
echoCallCostTime('异常数组-构造', function () use ($size, &$array){
$array = array();
for ($i = 0; $i <= $size; $i++) {
$key = $size * $i;
$array[$key] = 0;
}
});
echoCallCostTime('异常数组-首个元素访问', function () use ($array){
$b = $array[0];
});
echoCallCostTime('异常数组-最后元素访问', function () use ($array, $size){
$b = $array[$size * $size];
});
echoCallCostTime('普通数组-构造', function () use ($size, &$array){
$array = array();
for ($i = 0; $i <= $size; $i++) {
$array[$i] = 0;
}
});
echoCallCostTime('普通数组-首个元素访问', function () use ($array){
$b = $array[0];
});
echoCallCostTime('普通数组-最后元素访问', function () use ($array, $size){
$b = $array[$size];
});
我们先按照这个逻辑推理一下, 异常数组的构造一定比普通数组耗时要久, 因为每次插入都要遍历链表嘛.
而且, 异常数组的首个元素访问时间要更新, 因为它现在出在链表的末尾, 要想访问它就要将链表遍历一遍. 看下结果:
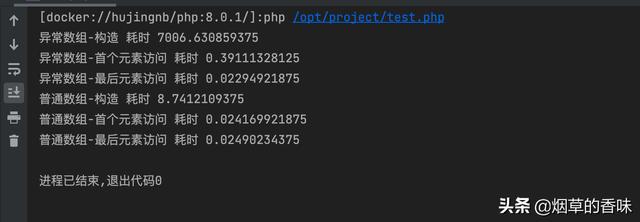
和之前的推论丝毫不差, 而且性能相差很多倍哦. 不过这里 hash 算法的具体实现我没有看


