无论是在后台开发,或者其他长期运行的服务开发中,对内存的使用一直是架构师或者主程序在最初就要关注的point,如果内存使用不当,频繁申请释放内存造成系统负担过大,性能降低,到最后产生大量内存碎片,无法申请可利用内存,最终宕机,给广大程序员同学造成长期加班的痛苦。
在讲到tcmalloc之前,这里不得不说 glibc 的资源释放机制:
1. glibc在多线程内存分配的场景下为了减少lock contention,会new出很多arena出来,每个 线程 都有自己默认的arena,但是内存申请时如果默认arena被占用,则round-robin到下一个arena。
2. 每个arena的空间不可直接共享和互相借用,除非通过主arena释放给操作系统然后被各个辅助arena重新申请。
3. glibc归还内存给OS有一个很苛刻的条件就是top chunk必须是free的,否则,即使应用程序已经释放了大片内存,glibc也不会将这些内存归还给OS。
这里我引入tcmalloc,相当于常见的内存池,tcmalloc的优势体现在:
(1)分配内存页的时候,直接跟 OS 打交道,而常用的内存池一般是基于别的内存管理器上分配,如果完全一样的 内存管理 策略,明显tcmalloc在性能及内存利用率上要省掉第三方内存管理的开销。之所以会出现这种情况,是因为大部分写内存池的coder都不太了解OS
(2)大部分的内存池只负责分配,不管回收。
为什么要使用TCmalloc
TCMalloc要比glibc 2.3的malloc(可以从一个叫作ptmalloc2的独立库获得)和其他我测试过的malloc都快。ptmalloc在一台2.8GHz的P4机器上执行一次小对象malloc及free大约需要300纳秒,而TCMalloc的版本同样的操作大约只需要50纳秒。malloc版本的速度是至关重要的,因为如果malloc不够快,应用程序的作者就倾向于在malloc之上写一个自己的 内存释放列表 。这就可能导致额外的代码复杂度,以及更多的内存占用――除非作者本身非常仔细地划分释放列表的大小并经常从中清除空闲的对象。
TCMalloc也减少了 多线程程序中的锁竞争 情况。对于小对象,已经基本上达到了零竞争。对于大对象,TCMalloc尝试使用恰当粒度和有效的自旋锁。ptmalloc同样是通过使用每线程各自的空间来减少锁的竞争,但是ptmalloc2使用每线程空间有一个很大的问题。在ptmalloc2中,内存不可能会从一个空间移动到另一个空间。这有可能导致大量内存被浪费。例如,在一个 Google 的应用中,第一阶段可能会为其URL标准化的数据结构分配大约300MB内存。当第一阶段结束后,第二阶段将从同样的地址空间开始。如果第二个阶段被安排到了与第一阶段不同的空间内,这个阶段不会复用任何第一阶段留下的的内存,并会给地址空间添加另外一个300MB。类似的内存爆炸问题也可以在其他的应用中看到。
TCMalloc的另一个好处表现在 小对象的空间效率 。例如,分配N个8字节对象可能要使用大约 8N * 1.01 字节的空间,即多用百分之一的空间。而ptmalloc2中每个对象都使用了一个四字节的头,我认为并将最终的尺寸圆整为8字节的倍数,最后使用了 16N 字节。
如何使用TCmalloc
一、下载
google-perftools: google -perftools/gperftools-2.1.tar.gz
libunwind:
二、libunwind安装
64位操作系统请先安装 libunwind库,32位操作系统不要安装。libunwind库为基于64位CPU和操作系统的程序提供了主要的堆栈辗转开解功能。当中包含用于输出堆栈跟踪的API、用于以编程方式辗转开解堆栈的API以及支持C++异常处理机制的API。
1: #tar zxvf libunwind-1.1.tar.gz
2: #cd libunwind-1.1
3: #./configure
4: #make
5: #make install
三、安装google-perftools:
1: #tar zxvf tar zxvf gperftools-2.1.tar.gz
2: #cd gperftools-2.1
3: #./configure
4: #make
5: #make install
四、TCMalloc库载入到 linux 系统中:
1: echo “/usr/local/lib” > /etc/ld.so.conf.d/usr_local_lib.conf
2: /sbin/ldconfig
五、TCMalloc库链接到你的程序中:
要使用TCMalloc,只要将tcmalloc通过“-ltcmalloc”链接器标志接入你的应用即可。
你也可以通过使用LD_PRELOAD在不是你自己编译的应用中使用tcmalloc:
$ LD_PRELOAD="/usr/lib/libtcmalloc.so" LD _PRELOAD比较麻烦,我们也不十分推荐这种用法。
TCMalloc还包含了一个 堆检查器 以及一个 堆测量器 。
如果你更想链接不包含堆测量器和检查器的TCMalloc版本(比如可能为了减少静态二进制文件的大小),你应该链接 libtcmalloc_minimal 。
測试代码:
# include <iostream>
using namespace std; int main()
{
int *p = new int();
return 0;
} 编译:g++ main.cpp -o main -ltcmalloc -g -O0
内存泄漏 检查: env HEAPCHECK=normal ./main
结果:
WARNING: Perftools heap leak checker is active — Performance may sufferHave memory regions w/o callers: might report false leaksLeak check _main_ detected leaks of 4 bytes in 1 objectsThe 1 largest leaks:Using local file ./main.Leak of 4 bytes in 1 objects allocated from: @ 4007a6 main @ 7f1734263d1d __libc_start_main @ 4006d9 _startIf the preceding stack traces are not enough to find the leaks, try running THIS shell command:pprof ./main “/tmp/main.54616._main_-end.heap” –inuse_objects –lines –heapcheck –edgefraction=1e-10 –nodefraction=1e-10 –gvIf you are still puzzled about why the leaks are there, try rerunning this program with HEAP_CHECK_TEST_POINTER_ALIGNMENT=1 and/or with HEAP_CHECK_MAX_POINTER_OFFSET=-1If the leak report occurs in a small fraction of runs, try running with TCMALLOC_MAX_FREE_QUEUE_SIZE of few hundred MB or with TCMALLOC_RECLAIM_MEMORY=false, it might help find leaks more repeatablyExiting with error code (instead of crashing) because of whole-program memory leaks |
这里不细讲内存泄漏检测,我将专门分享一篇文章来分析内存泄漏。
相关视频推荐
学习地址:
需要C/C++ Linux服务器架构师学习资料加qun 812855908 获取(资料包括 C/C++,Linux,golang技术, Nginx ,ZeroMQ,MySQL, Redis ,fastdfs, MongoDB , ZK ,流媒体, CDN ,P2P,K8S, Docker ,TCP/IP,协程,DPDK, ffmpeg 等),免费分享
TCmalloc的一些环境变量和参数
我们可以通过环境变量来控制tcmalloc的行为,通常有用的标志。
标志 | 默认值 | 作用 |
TCMALLOC_SAMPLE_PARAMETER | 0 | 采样时间间隔 |
TCMALLOC_RELEASE_RATE | 1.0 | 释放未使用内存的概率 |
TCMALLOC_LARGE_ALLOC_REPORT_THRESHOLD | 1073741824 | 内存最大分配阈值 |
TCMALLOC_MAX_TOTAL_THREAD_CACHE_BYTES | 16777216 | 分配给线程缓冲的最大内存上限 |
微调参数:
TCMALLOC_SKIP_ mmap | default: false | If true, do not try to use mmap to obtain memory from the kernel. |
TCMALLOC_SKIP_SBRK | default: false | If true, do not try to use sbrk to obtain memory from the kernel. |
TCMALLOC_DEVMEM_START | default: 0 | Physical memory starting location in MB for /dev/mem allocation. Setting this to 0 disables/dev/mem allocation. |
TCMALLOC_DEVMEM_LIMIT | default: 0 | Physical memory limit location in MB for /dev/mem allocation. Setting this to 0 means no limit. |
TCMALLOC_DEVMEM_DEVICE | default: /dev/mem | Device to use for allocating unmanaged memory. |
TCMALLOC_MEMFS_MALLOC_PATH | default: “” | If set, specify a path where hugetlbfs or tmpfs is mounted. This may allow for speedier allocations. |
TCMALLOC_MEMFS_LIMIT_MB | default: 0 | Limit total memfs allocation size to specified number of MB. 0 means “no limit”. |
TCMALLOC_MEMFS_ABORT_ON_FAIL | default: false | If true, abort() whenever memfs_malloc fails to satisfy an allocation. |
TCMALLOC_MEMFS_IGNORE_MMAP_FAIL | default: false | If true, ignore failures from mmap. |
TCMALLOC_MEMFS_MAP_PRVIATE | default: false | If true, use MAP_PRIVATE when mapping via memfs, not MAP_SHARED. |
修改TCmalloc的一些行为
我们可以通过包含malloc_extension.h头文件中的MallocExtension类提供了一些微调的接口来修改tcmalloc的行为来使得你的程序达到更高的效率。
默认情况下,tcmalloc将逐渐的释放长时间未使用的内存给内核。tcmalloc_release_rate标志控制归还给操作系统内存的速度大,你也可以长治释放内存通过执行如下操作:
MallocExtension::instance()->ReleaseFreeMemory();
你同样可以调用SetMemoryReleaseRate()来在运行时修改tcmalloc_release_rate的值,或者调用GetMemoryReleaseRate来查看当前释放的概率值。
MallocExtension::instance()->SetMemoryReleaseRate(10.0);
// 【0-10】数值越大,回收速度越快,这个需要根据自己项目情况测试给一个最合理的参数。
当然你也可以通过以下接口来获取tcmalloc的相关堆栈使用情况:
MallocExtension::instance()->GetStats(buffer, buffer_length);
MallocExtension::instance()->GetHeapSample(&string); MallocExtension::instance()->GetHeapGrowthStacks(&string);
TCmalloc和PTMalloc的性能参数对比
PTMalloc2包(现在已经是glibc的一部分了)包含了一个单元测试程序 t-test1.c 。它会产生一定数量的线程并在每个线程中进行一系列分配和解除分配;线程之间没有任何通信除了在内存分配器中同步。
t-test1 (放在 tests/tcmalloc/ 中,编译为 ptmalloc_unittest1 )用一系列不同的线程数量(1~20)和最大分配尺寸(64B~32KB)运行。这些测试运行在一个2.4GHz 双核心Xeon的RedHat 9系统上,并启用了超线程技术, 使用了Linux glibc-2.3.2,每个测试中进行一百万次操作。在每个案例中,一次正常运行,一次使用 LD_PRELOAD=libtcmalloc.so 。
下面的图像显示了TCMalloc对比PTMalloc2在不同的衡量指标下的性能。首先,现实每秒操作次数(百万)以及最大分配尺寸,针对不同数量的线程。用来生产这些图像的原始数据( time 工具的输出)可以在 t-test1.times.txt 中找到。
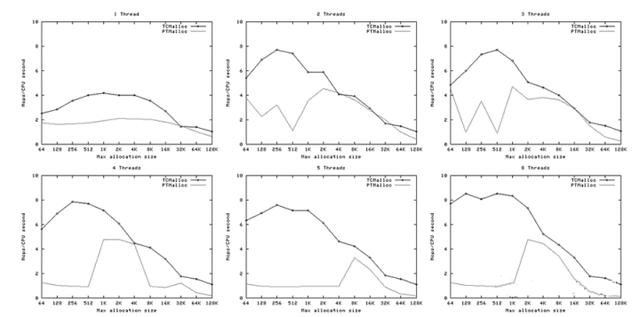
- TCMalloc要比PTMalloc2更具有一致地伸缩性——对于所有线程数量>1的测试,小分配达到了约7~9百万操作每秒,大分配降到了约2百万操作每秒。单线程的案例则明显是要被剔除的,因为他只能保持单个处理器繁忙因此只能获得较少的每秒操作数。PTMalloc2在每秒操作数上有更高的 方差 ——某些地方峰值可以在小分配上达到4百万操作每秒,而在大分配上降到了<1百万操作每秒。
- TCMalloc在绝大多数情况下要比PTMalloc2快,并且特别是小分配上。线程间的争用在TCMalloc中问题不大。
- TCMalloc的性能随着分配尺寸的增加而降低。这是因为每线程缓存当它达到了阈值(默认是2MB)的时候会被垃圾收集。对于更大的分配尺寸,在垃圾收集之前只能在缓存中存储更少的对象。
- TCMalloc性能在约32K最大分配尺寸附件有一个明显的下降。这是因为在每线程缓存中的32K对象的最大尺寸;对于大于这个值得对象TCMalloc会从中央页面堆中进行分配。
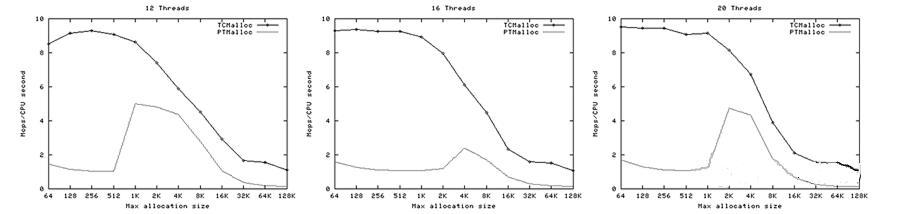
下面是每秒 CPU 时间的操作数(百万)以及线程数量的图像,最大分配尺寸64B~128KB。
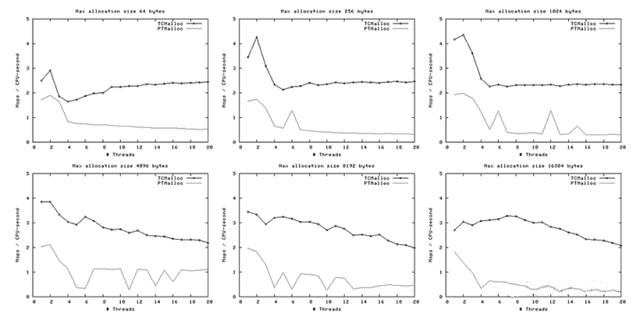
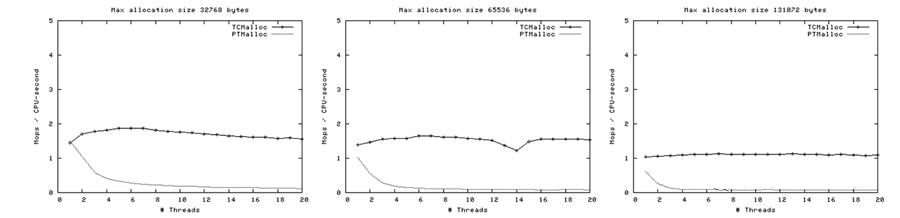
这次我们再一次看到TCMalloc要比PTMalloc2更连续也更高效。对于<32K的最大分配尺寸,TCMalloc在大线程数的情况下典型地达到了CPU时间每秒约0.5~1百万操作,同时PTMalloc通常达到了CPU时间每秒约0.5~1百万,还有很多情况下要比这个数字小很多。在32K最大分配尺寸之上,TCMalloc下降到了每CPU时间秒1~1.5百万操作,同时PTMalloc对于大线程数降到几乎只有零(也就是,使用PTMalloc,在高度 多线程 的情况下,很多CPU时间被浪费在轮流等待锁定上了)。
关于TCmalloc的一些说明
对于某些系统,TCMalloc可能无法与没有链接 libpthread.so (或者你的系统上同等的东西)的应用程序正常工作。它应该能正常工作于使用glibc 2.3的Linux上,但是其他OS/libc的组合方式尚未经过任何测试。
TCMalloc可能要比其他malloc版本在某种程度上更吃内存,(但是倾向于不会有其他malloc版本中可能出现的爆发性增长。)尤其是在启动时TCMalloc会分配大约240KB的内部内存。
不要试图将TCMalloc载入到一个运行中的 二进制 程序中(例如,在 Java 中使用 JNI )。 二进制程序已经使用系统malloc分配了一些对象,并会尝试将它们传递到TCMalloc进行解除分配 。TCMalloc是无法处理这种对象的。


