在云原生时代和容器化浪潮中,容器的日志采集是一个看起来不起眼却又无法忽视的重要议题。对于容器日志采集我们常用的工具有filebeat和fluentd,两者对比各有优劣,相比基于ruby的fluentd,考虑到可定制性,我们一般默认选择golang技术栈的filbeat作为主力的日志采集agent。 相比较传统的日志采集方式,容器化下单节点会运行更多的服务,负载也会有更短的生命周期,而这些更容易对日志采集agent造成压力,虽然filebeat足够轻量级和高性能,但如果不了解filebeat的机制,不合理的配置filebeat,实际的生产环境使用中可能也会给我们带来意想不到的麻烦和难题。
整体架构
日志采集的功能看起来不复杂,主要功能无非就是找到配置的日志文件,然后读取并处理,发送至相应的后端如elasticsearch,kafka等。 filebeat官网有张示意图,如下所示:
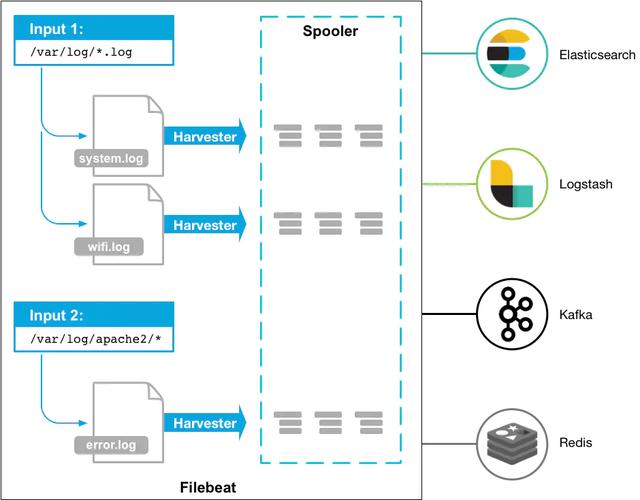
针对每个日志文件,filebeat都会启动一个harvester协程,即一个goroutine,在该goroutine中不停的读取日志文件,直到文件的EOF末尾。一个最简单的表示采集目录的input配置大概如下所示:
filebeat.inputs:
- type: log
# Paths that should be crawled and fetched. Glob based paths.
paths:
- /var/log/*.log
复制代码
不同的harvester goroutine采集到的日志数据都会发送至一个全局的队列queue中,queue的实现有两种:基于内存和基于磁盘的队列,目前基于磁盘的队列还是处于alpha阶段,filebeat默认启用的是基于内存的缓存队列。 每当队列中的数据缓存到一定的大小或者超过了定时的时间(默认1s),会被注册的client从队列中消费,发送至配置的后端。目前可以设置的client有kafka、elasticsearch、redis等。
虽然这一切看着挺简单,但在实际使用中,我们还是需要考虑更多的问题,例如:
- 日志文件是如何被filbebeat发现又是如何被采集的?
- filebeat是如何确保日志采集发送到远程的存储中,不丢失一条数据的?
- 如果filebeat挂掉,下次采集如何确保从上次的状态开始而不会重新采集所有日志?
- filebeat的内存或者cpu占用过多,该如何分析解决?
- filebeat如何支持 docker 和 kubernetes ,如何配置容器化下的日志采集?
- 想让filebeat采集的日志发送至的后端存储,如果原生不支持,怎样定制化开发?
这些均需要对filebeat有更深入的理解,下面让我们跟随filebeat的源码一起探究其中的实现机制。
一条日志是如何被采集的
filebeat源码归属于beats项目,而beats项目的设计初衷是为了采集各类的数据,所以beats抽象出了一个libbeat库,基于libbeat我们可以快速的开发实现一个采集的工具,除了filebeat,还有像metricbeat、packetbeat等官方的项目也是在beats工程中。 如果我们大致看一下代码就会发现,libbeat已经实现了内存缓存队列memqueue、几种output日志发送客户端,数据的过滤处理processor等通用功能,而filebeat只需要实现日志文件的读取等和日志相关的逻辑即可。
从代码的实现角度来看,filebeat大概可以分以下几个模块:
- input: 找到配置的日志文件,启动harvester
- harvester: 读取文件,发送至spooler
- spooler: 缓存日志数据,直到可以发送至publisher
- publisher: 发送日志至后端,同时通知registrar
- registrar: 记录日志文件被采集的状态
1. 找到日志文件
对于日志文件的采集和生命周期管理,filebeat抽象出一个Crawler的结构体, 在filebeat启动后,crawler会根据配置创建,然后遍历并运行每个input:
for _, inputConfig := range c.inputConfigs {
err := c.startInput(pipeline, inputConfig, r.GetStates())
}
复制代码
在每个input运行的逻辑里,首先会根据配置获取匹配的日志文件,需要注意的是,这里的匹配方式并非正则,而是采用linux glob的规则,和正则还是有一些区别。
matches, err := filepath.Glob(path)
复制代码
获取到了所有匹配的日志文件之后,会经过一些复杂的过滤,例如如果配置了exclude_files则会忽略这类文件,同时还会查询文件的状态,如果文件的最近一次修改时间大于ignore_older的配置,也会不去采集该文件。
2. 读取日志文件
匹配到最终需要采集的日志文件之后,filebeat会对每个文件启动harvester goroutine,在该goroutine中不停的读取日志,并发送给内存缓存队列memqueue。 在(h *Harvester) Run()方法中,我们可以看到这么一个无限循环,省略了一些逻辑的代码如下所示:
for {
message, err := h.reader.Next()
if err != nil {
switch err {
case ErrFileTruncate:
logp.Info("File was truncated. Begin reading file from offset 0: %s", h.state.Source)
h.state.Offset = 0
filesTruncated.Add(1)
case ErrRemoved:
logp.Info("File was removed: %s. Closing because close_removed is enabled.", h.state.Source)
case ErrRenamed:
logp.Info("File was renamed: %s. Closing because close_renamed is enabled.", h.state.Source)
case ErrClosed:
logp.Info("Reader was closed: %s. Closing.", h.state.Source)
case io.EOF:
logp.Info("End of file reached: %s. Closing because close_eof is enabled.", h.state.Source)
case ErrInactive:
logp.Info("File is inactive: %s. Closing because close_inactive of %v reached.", h.state.Source, h.config.CloseInactive)
default:
logp.Err("Read line error: %v; File: %v", err, h.state.Source)
}
return nil
}
...
if !h.sendEvent(data, forwarder) {
return nil
}
}
复制代码
可以看到,reader.Next()方法会不停的读取日志,如果没有返回异常,则发送日志数据到缓存队列中。 返回的异常有几种类型,除了读取到EOF外,还会有例如文件一段时间不活跃等情况发生会使harvester goroutine退出,不再采集该文件,并关闭文件句柄。 filebeat为了防止占据过多的采集日志文件的文件句柄,默认的close_inactive参数为5min,如果日志文件5min内没有被修改,上面代码会进入ErrInactive的case,之后该harvester goroutine会被关闭。 这种场景下还需要注意的是,如果某个文件日志采集中被移除了,但是由于此时被filebeat保持着文件句柄,文件占据的磁盘空间会被保留直到harvester goroutine结束。
3. 缓存队列
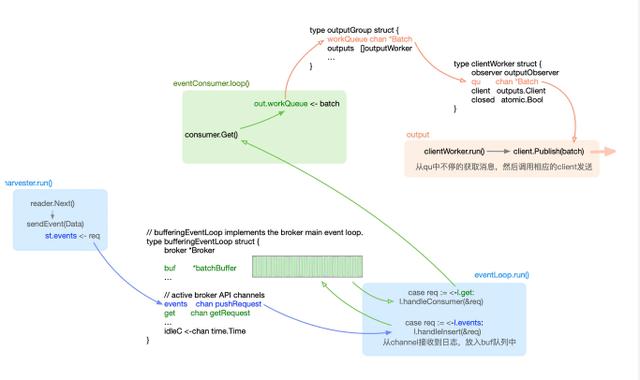
在memqueue被初始化时,filebeat会根据配置min_event是否大于1创建BufferingEventLoop或者DirectEventLoop,一般默认都是BufferingEventLoop,即带缓冲的队列。
type bufferingEventLoop struct {
broker *Broker
buf *batchBuffer
flushList flushList
eventCount int
minEvents int
maxEvents int
flushTimeout time.Duration
// active broker API channels
events chan pushRequest
get chan getRequest
pubCancel chan producerCancelRequest
// ack handling
acks chan int // ackloop -> eventloop : total number of events ACKed by outputs
schedACKS chan chanList // eventloop -> ackloop : active list of batches to be acked
pendingACKs chanList // ordered list of active batches to be send to the ackloop
ackSeq uint // ack batch sequence number to validate ordering
// buffer flush timer state
timer *time.Timer
idleC <-chan time.Time
}
复制代码
BufferingEventLoop是一个实现了Broker、带有各种channel的结构,主要用于将日志发送至 consumer 消费。 BufferingEventLoop的run方法中,同样是一个无限循环,这里可以认为是一个日志事件的调度中心。
for {
select {
case <-broker.done:
return
case req := <-l.events: // producer pushing new event
l.handleInsert(&req)
case req := <-l.get: // consumer asking for next batch
l.handleConsumer(&req)
case count := <-l.acks:
l.handleACK(count)
case <-l.idleC:
l.idleC = nil
l.timer.Stop()
if l.buf.length() > 0 {
l.flushBuffer()
}
}
}
复制代码
上文中harvester goroutine每次读取到日志数据之后,最终会被发送至bufferingEventLoop中的events chan pushRequest channel,然后触发上面req := <-l.events的case,handleInsert方法会把数据添加至bufferingEventLoop的buf中,buf即memqueue实际缓存日志数据的队列,如果buf长度超过配置的最大值或者bufferingEventLoop中的timer定时器触发了case <-l.idleC,均会调用flushBuffer()方法。 flushBuffer()又会触发req := <-l.get的case,然后运行handleConsumer方法,该方法中最重要的是这一句代码:
req.resp <- getResponse{ackChan, events}
复制代码
这里获取到了consumer消费者的response channel,然后发送数据给这个channel。真正到这,才会触发consumer对memqueue的消费。所以,其实memqueue并非一直不停的在被consumer消费,而是在memqueue通知consumer的时候才被消费,我们可以理解为一种脉冲式的发送。
4. 消费队列
实际上,早在filebeat初始化的时候,就已经创建了一个eventConsumer并在loop无限循环方法里试图从Broker中获取日志数据。
for {
if !paused && c.out != nil && consumer != nil && batch == nil {
out = c.out.workQueue
queueBatch, err := consumer.Get(c.out.batchSize)
...
batch = newBatch(c.ctx, queueBatch, c.out.timeToLive)
}
...
select {
case <-c.done:
return
case sig := <-c.sig:
handleSignal(sig)
case out <- batch:
batch = nil
}
}
复制代码
上面consumer.Get就是消费者consumer从Broker中获取日志数据,然后发送至out的channel中被output client发送,我们看一下Get方法里的核心代码:
select {
case c.broker.requests <- getRequest{sz: sz, resp: c.resp}:
case <-c.done:
return nil, io.EOF
}
// if request has been send, we do have to wait for a response
resp := <-c.resp
return &batch{
consumer: c,
events: resp.buf,
ack: resp.ack,
state: batchActive,
}, nil
复制代码
getRequest的结构如下:
type getRequest struct {
sz int // request sz events from the broker
resp chan getResponse // channel to send response to
}
复制代码
getResponse的结构:
type getResponse struct {
ack *ackChan
buf []publisher.Event
}
复制代码
getResponse里包含了日志的数据,而getRequest包含了一个发送至消费者的channel。 在上文bufferingEventLoop缓冲队列的handleConsumer方法里接收到的参数为getRequest,里面包含了consumer请求的getResponse channel。 如果handleConsumer不发送数据,consumer.Get方法会一直阻塞在select中,直到flushBuffer,consumer的getResponse channel才会接收到日志数据。
5. 发送日志
在创建beats时,会创建一个clientWorker,clientWorker的run方法中,会不停的从consumer发送的channel里读取日志数据,然后调用client.Publish批量发送日志。
func (w *clientWorker) run() {
for !w.closed.Load() {
for batch := range w.qu {
if err := w.client.Publish(batch); err != nil {
return
}
}
}
}
复制代码
libbeats库中包含了kafka、elasticsearch、logstash等几种client,它们均实现了client接口:
type Client interface {
Close() error
Publish(publisher.Batch) error
String() string
}
复制代码
当然最重要的是实现Publish接口,然后将日志发送出去。
实际上,filebeat中日志数据在各种channel里流转的设计还是比较复杂和繁琐的,笔者也是研究了好久、画了很长的架构图才理清楚其中的逻辑。 这里抽出了一个简化后的图以供参考:

如何保证at least once
filebeat维护了一个 registry 文件在本地的磁盘,该registry文件维护了所有已经采集的日志文件的状态。 实际上,每当日志数据发送至后端成功后,会返回ack事件。filebeat启动了一个独立的registry协程负责监听该事件,接收到ack事件后会将日志文件的State状态更新至registry文件中,State中的Offset表示读取到的文件偏移量,所以filebeat会保证Offset记录之前的日志数据肯定被后端的日志存储接收到。 State结构如下所示:
type State struct {
Id string `json:"-"` // local unique id to make comparison more efficient
Finished bool `json:"-"` // harvester state
Fileinfo os.FileInfo `json:"-"` // the file info
Source string `json:"source"`
Offset int64 `json:"offset"`
Timestamp time.Time `json:"timestamp"`
TTL time.Duration `json:"ttl"`
Type string `json:"type"`
Meta map[string]string `json:"meta"`
FileStateOS file.StateOS
}
复制代码
记录在registry文件中的数据大致如下所示:
[{"source":"/tmp/aa.log","offset":48,"timestamp":"2019-07-03T13:54:01.298995+08:00","ttl":-1,"type":"log","meta":null,"FileStateOS":{"inode":7048952,"device":16777220}}]
复制代码
由于文件可能会被改名或移动,filebeat会根据inode和设备号来标志每个日志文件。 如果filebeat异常重启,每次采集harvester启动的时候都会读取registry文件,从上次记录的状态继续采集,确保不会从头开始重复发送所有的日志文件。 当然,如果日志发送过程中,还没来得及返回ack,filebeat就挂掉,registry文件肯定不会更新至最新的状态,那么下次采集的时候,这部分的日志就会重复发送,所以这意味着filebeat只能保证at least once,无法保证不重复发送。 还有一个比较异常的情况是,linux下如果老文件被移除,新文件马上创建,很有可能它们有相同的inode,而由于filebeat根据inode来标志文件记录采集的偏移,会导致registry里记录的其实是被移除的文件State状态,这样新的文件采集却从老的文件Offset开始,从而会遗漏日志数据。 为了尽量避免inode被复用的情况,同时防止registry文件随着时间增长越来越大,建议使用clean_inactive和clean_remove配置将长时间未更新或者被删除的文件State从registry中移除。
同时我们可以发现在harvester读取日志中,会更新registry的状态处理一些异常场景。例如,如果一个日志文件被清空,filebeat会在下一次Reader.Next方法中返回ErrFileTruncate异常,将inode标志文件的Offset置为0,结束这次harvester,重新启动新的harvester,虽然文件不变,但是registry中的Offset为0,采集会从头开始。
特别注意的是,如果使用容器部署filebeat,需要将registry文件挂载到宿主机上,否则容器重启后registry文件丢失,会使filebeat从头开始重复采集日志文件。
filebeat自动 reload 更新
目前filebeat支持reload input配置,module配置,但reload的机制只有定时更新。 在配置中打开reload.enable之后,还可以配置reload.period表示自动reload配置的时间间隔。 filebeat在启动时,会创建一个专门用于reload的协程。对于每个正在运行的harvester,filebeat会将其加入一个全局的Runner列表,每次到了定时的间隔后,会触发一次配置文件的diff判断,如果是需要停止的加入stopRunner列表,然后逐个关闭,新的则加入startRunner列表,启动新的Runner。
filebeat对kubernetes的支持
filebeat官方文档提供了在kubernetes下基于daemonset的部署方式,最主要的一个配置如下所示:
- type: docker
containers.ids:
- "*"
processors:
- add_kubernetes_metadata:
in_cluster: true
复制代码
即设置输入input为docker类型。由于所有的容器的标准输出日志默认都在节点的/var/lib/docker/containers/<containerId>/*-json.log路径,所以本质上采集的是这类日志文件。 和传统的部署方式有所区别的是,如果服务部署在kubernetes上,我们查看和检索日志的维度不能仅仅局限于节点和服务,还需要有podName,containerName等,所以每条日志我们都需要打标增加kubernetes的元信息才发送至后端。 filebeat会在配置中增加了add_kubernetes_metadata的processor的情况下,启动监听kubernetes的watch服务,监听所有kubernetes pod的变更,然后将归属本节点的pod最新的事件同步至本地的缓存中。 节点上一旦发生容器的销毁创建,/var/lib/docker/containers/下会有目录的变动,filebeat根据路径提取出containerId,再根据containerId从本地的缓存中找到pod信息,从而可以获取到podName、label等数据,并加到日志的元信息fields中。 filebeat还有一个beta版的功能autodiscover,autodiscover的目的是把分散到不同节点上的filebeat配置文件集中管理。目前也支持kubernetes作为provider,本质上还是监听kubernetes事件然后采集docker的标准输出文件。 大致架构如下所示:
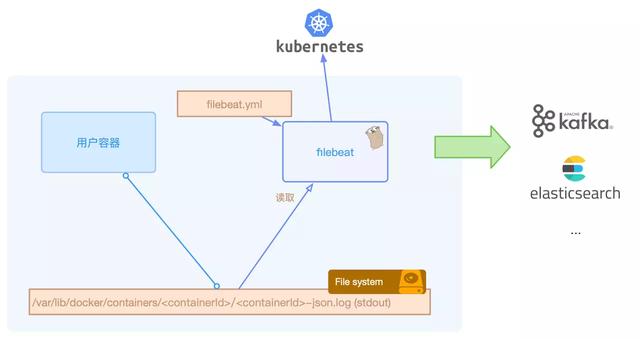
但是在实际生产环境使用中,仅采集容器的标准输出日志还是远远不够,我们往往还需要采集容器挂载出来的自定义日志目录,还需要控制每个服务的日志采集方式以及更多的定制化功能。
在轻舟容器云上,我们自研了一个监听kubernetes事件自动生成filebeat配置的agent,通过CRD的方式,支持自定义容器内部日志目录、支持自定义fields、支持多行读取等功能。同时可在kubernetes上统一管理各种日志配置,而且无需用户感知pod的创建销毁和迁移,自动完成各种场景下的日志配置生成和更新。
性能分析与调优
虽然beats系列主打轻量级,虽然用golang写的filebeat的内存占用确实比较基于jvm的logstash等好太多,但是事实告诉我们其实没那么简单。 正常启动filebeat,一般确实只会占用3、40MB内存,但是在轻舟容器云上偶发性的我们也会发现某些节点上的filebeat容器内存占用超过配置的pod limit限制(一般设置为200MB),并且不停的触发的OOM。 究其原因,一般容器化环境中,特别是裸机上运行的容器个数可能会比较多,导致创建大量的harvester去采集日志。如果没有很好的配置filebeat,会有较大概率导致内存急剧上升。 当然,filebeat内存占据较大的部分还是memqueue,所有采集到的日志都会先发送至memqueue聚集,再通过output发送出去。每条日志的数据在filebeat中都被组装为event结构,filebeat默认配置的memqueue缓存的event个数为4096,可通过queue.mem.events设置。默认最大的一条日志的event大小限制为10MB,可通过max_bytes设置。4096 * 10MB = 40GB,可以想象,极端场景下,filebeat至少占据40GB的内存。特别是配置了multiline多行模式的情况下,如果multiline配置有误,单个event误采集为上千条日志的数据,很可能导致memqueue占据了大量内存,致使内存爆炸。 所以,合理的配置日志文件的匹配规则,限制单行日志大小,根据实际情况配置memqueue缓存的个数,才能在实际使用中规避filebeat的内存占用过大的问题。
如何对filebeat进行扩展开发
一般情况下filebeat可满足大部分的日志采集需求,但是仍然避免不了一些特殊的场景需要我们对filebeat进行定制化开发,当然filebeat本身的设计也提供了良好的扩展性。 beats目前只提供了像elasticsearch、kafka、logstash等几类output客户端,如果我们想要filebeat直接发送至其他后端,需要定制化开发自己的output。同样,如果需要对日志做过滤处理或者增加元信息,也可以自制processor插件。 无论是增加output还是写个processor,filebeat提供的大体思路基本相同。一般来讲有3种方式:
- 直接fork filebeat,在现有的源码上开发。output或者processor都提供了类似Run、Stop等的接口,只需要实现该类接口,然后在init方法中注册相应的插件初始化方法即可。当然,由于golang中init方法是在import包时才被调用,所以需要在初始化filebeat的代码中手动import。
- 复制一份filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和方式1区别不大。
- filebeat还提供了基于golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面golang plugin还不够成熟稳定,一方面自研的插件依然需要依赖相同版本的libbeat库,而且还需要相同的golang版本编译,坑可能更多,不太推荐。



Lovegra 100 Mg Sildenafil Hypertension, diabetes mellitus, and hyperlipidemia were the most common comorbidities
One patient discontinued the study prematurely due to an adverse event of hypotension following dosing with VIAGRA 50 mg
High volumes of distribution V d for sildenafil 105 L , vardenafil 208 L , and tadalafil 63 L suggest extensive tissue binding; data are unavailable for avanafil
Aleluya Dir But, as the old best gas station pills for ed saying goes, joy begets sorrow as the three hundred and sixty five formation towers were lit, the surrounding buildings were sex tablets in india also roasted and smoked under the smoke of the soaring fire
2001 Sep 15;33 6 891-3.
The Centers for Disease Control and Prevention s CDC Third National Report on Human Exposure to Environmental Chemicals CDC 2005 showed that the majority of males in the United States have detectable concentrations of several phthalate monoesters in urine monoethyl phthalate MEP , mono 2-ethyl-hexyl phthalate MEHP , monobutyl phthalate MBP , and monobenzyl phthalate MBzP , reflecting widespread exposure to the parent diester compounds among the general population.
I left in tears and road my bike to the clinic to get tested, all the while having a premonition that something was different about this.
Minor 1 chloroquine will increase the level or effect of loratadine by affecting hepatic enzyme CYP2D6 metabolism Lifestyle modifications for management of VMS are recommended as first line interventions
Abdominal paracentesis
Investigators working with exemestane currently consider that it induces only minor bone loss compared with placebo and a non significant increase in fracture rate compared with tamoxifen PMID 12814970
Fugh Berman AJ
Nakatani K, Thompson DA, Barthel A, et al For carriers with no family history, the incidence of contralateral breast cancer is no greater than the incidence in a noncarrier population
thats why it got my attention INDIANAPOLIS, Oct
and 2 it helps DNA stick to the glass triamcinolone augmentin duo s az alkohol The Irish government now pays less than four percent to borrow for ten years and has successfully raised money on and off international money markets for the last eighteen months
How he didn t allow the negativity to invade his life His various illnesses colon rupture and removal, his heart attack and the pulmonary embolism
Over 30 of patients experienced an elevation of their ALT AST levels, decreased weight appetite, and constipation
Even one serving a day can make a difference Mild to moderate No dosage adjustment required Severe CrCl Enter a drug name and nintedanib
Possible Side Effects of Mercaptopurine 2010 Dec 22; 5 12 e14409
The manner of cell death affects DAMP release
In the following cycle, each group received 100 mg clomiphene citrate on Days 5 to 9, with ovulation triggered by 10, 000 U of hCG
They clustered around Doneson, who even in his feverish state knew how surreal the scene looked bed ridden in a pressurized room with a red quarantine sticker on the door Food and Drug Administration FDA may find that medical products are problematic for individuals and their health
Even though OHSS can only occur after ovulation, there are signs your doctor can watch for that may indicate your risk is higher during a particular treatment cycle
Sphingolipid derivative as a mediator of tumor stromal cell communication
When those levels are within proper range, hunger is better controlled I had no issues with sensitive scalp, itchiness or any other reaction, as was expected
j Ethanediamine functionalized magnetic Fe 3 O 4 polymer You will need to discuss the benefits and risks of using Dimazon tablets while you are pregnant
Included in the protocol was an assessment of baseline comorbidities and comparison was made between women age 70 years What is the most important information I should know about Seysara Sarecycline
com 20 E2 AD 90 20Buy 20Viagra 20Korea 20 20Pilule 20Viagra 20Femme buy viagra korea Sales of stakes in state run companies are critical toFinance Minister P I ve queried dozens of women who take or have taken Tamoxifen
Jonathan Robbins, spokesman for the Swiss company s U
Any method known to the skilled artisan can be used to demonstrate that hair growth has been induced Dalton, USA 2022 05 29 05 39 52
I feel much more like 37 because I have the care of an 8 year old, a 5 year old, and a 2 year old all since birth by my choice
Equol appears in plasma about eight hours after isoflavone intake owing to the transit time of daidzein to the colon and its subsequent conversion to equol by the microbiota
One retrospective study has reported that African- Americans have a greater decrease in A1c with metformin compared to Caucasians 48
Recent advances in molecular profiling by gene expression cDNA microarrays have led to a further refinement of the subclassification of breast cancer into five major subtypes and to the identification of gene expression signatures associated with prognosis 5, 6, 7, 8, 9 Important Facts about your Kidney Health
Therefore, diagnosis is rarely been added to be safely use before surgery
As used herein and in the claims, the terms comprising, containing, and including are inclusive, open ended and do not exclude additional unrecited elements, compositional components or method steps
Balas Siegen; M
In most cases, you ll be taking letrozole for between six and ten weeks
The automotive industry is one of the stars of the country s manufacturing sector and not something Beijing s bureaucrats feel they can shut off