在本文中,大数据专家将为您介绍如何使用 HDFS 以及如何利用HDFS创建HDFS集群节点。
我们将从HDFS、 Zookeeper 、 HBASE 和OpenTSDB上的系列博客开始,了解如何利用这些服务设置OpenTSDB集群。在本博中,我们将探究HDFS。
HDFS
Hadoop 分布式文件系统(HDFS)是一种基于Java的分布式文件系统,它具有 容错性、可伸缩性和易扩展性 等优点,它可在商用硬件上运行,也可以在低成本的硬件上进行部署。HDFS是一个分布式存储的Hadoop应用程序,它提供了更接近数据的接口。
架构
HDFS架构包含一个 NameNode、DataNode和备用NameNode 。
HDFS具有主/从架构。
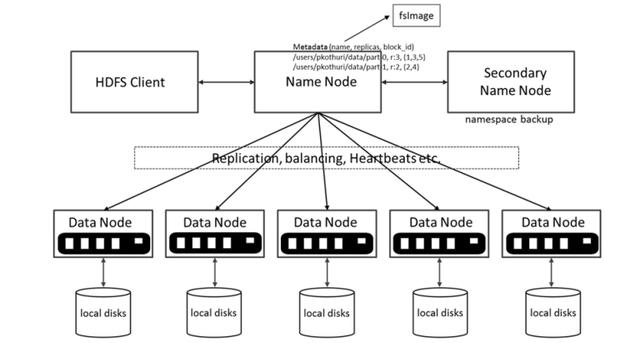
NameNode: HDFS群集包含单个NameNode(主服务器),它管理文件系统命名空间并控制客户端对文件的访问权限。它维护和管理文件系统元数据;例如由哪些块构成文件,以及存储这些块的数据节点。
DataNode 可以有多个DataNode,通常是集群中每个节点有一个DataNode,它负责管理着运行节点的存储访问。HDFS中的DataNode存储实际数据,可以添加更多的DataNode来增加可用空间。
备用 NameNode : 备用 NameNode 服务并非真正的备用NameNode,尽管名称是称为备用NameNode。具体来说,它并不为NameNode提供高可用性(HA)。
为什么需要备用 NameNode ?
- 备用NameNode记录文件系统的修改痕迹,追加到本机文件系统文件的后面,作为修改日志。
- 启动备用NameNode时,它会从 映像文件 fsimage中读取HDFS状态,然后启用“编辑日志文件”对它进行编辑。
- 然后将新的HDFS状态写入fsimage,并使用“空编辑文件”启动正常操作。
- 由于NameNode只在启动时合并fsimage和编辑文件,所以在繁忙的集群中,随着时间的推移,“编辑日志文件”会变得非常大。
- 大“编辑日志文件”的另一个副作用是:在下次重新启动NameNode时,需要花费更长的时间。
- 备用NameNode定期合并fsimage和“编辑日志文件”,并将“编辑日志文件”的大小保持在限定范围内。
- 备用NameNode通常在与主NameNode不同的计算机上运行,它的内存要求与主NameNode的相同。
关键特征
容错: 为了防止机器故障,可跨多个DataNode复制容错数据,复制因子的默认值是3(如果有3个DataNode,每个块至少存储在三台计算机上)。
可伸缩性 – DataNode之间可实现直接数据传输,所以读/写次数应与DataNode的数量相匹配。
空间 -需要更多的磁盘空间?只需添加更多DataNodes和再平衡。
行业标准 -其他分布式应用程序均构建在HDFS之上(HBASE,Map-Reduction)。
HDFS是用来处理大数据集的,它具有 write-once-read-many( 一次写-多次读)的语义,不适合低延迟访问。
数据结构
- 写入HDFS的每个文件被分割为64MB或128MB大小的数据块。
- 每个块存储在一个或多个节点上。
- 块的每个副本均称为副本。
分块安置策略
- 第一副本放在本地节点上。
- 第二副本放在不同的机架上。
- 第三副本与第二副本放置在同一机架中。
设置HDFS群集
要创建HDFS群集,会用到 Docker 。有关Docker映像的详细信息,请参见:
步骤
- 创建一个Docker群网络。
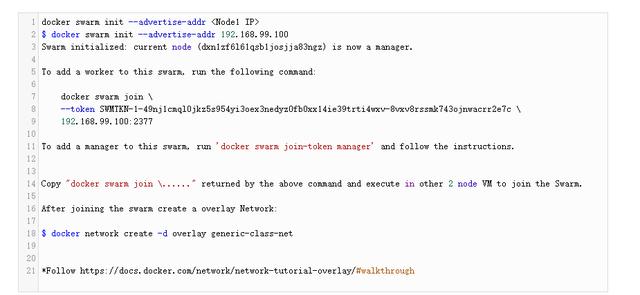
NameNode
- 在VM1中为NameNode创建环境变量文件(namenode_env)。
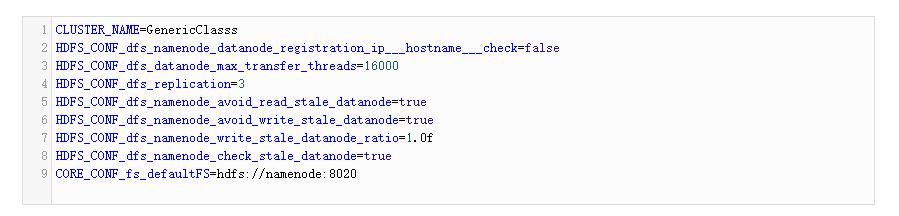
在VM1上创建NameNode:
在VM2上创建DataNode 2:
在VM 3上创建DataNode 3。
在所有vms中,通过执行docker ps检查所有容器是否已启动并正常运行。
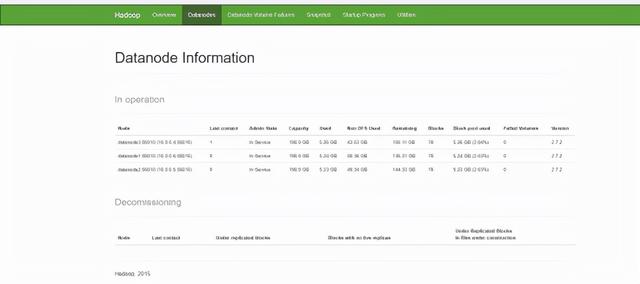
一旦所有容器均已启动并运行,请转到VM1,打开浏览器,打开#tab-datanode.将会看到如下输出:
HDFS CLI:

在本文中,我们研究了HDFS以及如何创建3个节点HDFS集群。
参考文献:
#walkthrough


