这里的 SPARK SQL是指整合了 Hive 的 spark -sql cli(关于Spark SQL 和Hive的整合,见文章后面的参考阅读).
本质上就是通过Hive访问 HBase 表,具体就是通过hive-hbase-handler .
Hadoop -2.3.0-cdh5.0.0
apache -hive-0.13.1-bin
spark-1.4.0-bin-hadoop2.3
hbase-0.96.1.1-cdh5.0.0 部署情况如下图:
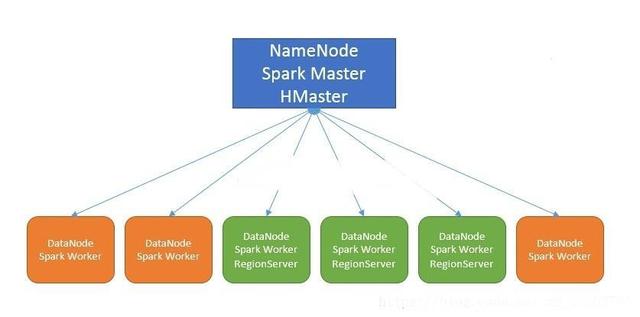
测试集群,将Spark Worker部署在每台DataNode上,是为了最大程度的任务本地化,Spark集群为Standalone模式部署。
其中有三台机器上也部署了RegionServer。
这个部署情况对理解后面提到的任务本地化调度有帮助。
配置篇
1. 拷贝以下HBase的相关jar包到Spark Master和每个Spark Worker节点上的$SPARK_HOME/lib目录下.
(我尝试用–jars的方式添加之后,不work,所以采用这种土办法)
$HBASE_HOME/lib/hbase-client-0.96.1.1-cdh5.0.0.jar
$HBASE_HOME/lib/hbase-common-0.96.1.1-cdh5.0.0.jar
$HBASE_HOME/lib/hbase-protocol-0.96.1.1-cdh5.0.0.jar
$HBASE_HOME/lib/hbase-server-0.96.1.1-cdh5.0.0.jar
$HBASE_HOME/lib/htrace-core-2.01.jar
$HBASE_HOME/lib/protobuf-java-2.5.0.jar
$HBASE_HOME/lib/guava-12.0.1.jar
$HIVE_HOME/lib/hive-hbase-handler-0.13.1.jar 2.配置每个节点上的$SPARK_HOME/conf/spark-env.sh,将上面的jar包添加到SPARK_CLASSPATH
export SPARK_CLASSPATH=$SPARK_HOME/lib/hbase-client-0.96.1.1-cdh5.0.0.jar:
$SPARK_HOME/lib/hbase-common-0.96.1.1-cdh5.0.0.jar:
$SPARK_HOME/lib/hbase-protocol-0.96.1.1-cdh5.0.0.jar:
$SPARK_HOME/lib/hbase-server-0.96.1.1-cdh5.0.0.jar:
$SPARK_HOME/lib/htrace-core-2.01.jar:
$SPARK_HOME/lib/protobuf-java-2.5.0.jar:
$SPARK_HOME/lib/guava-12.0.1.jar:
$SPARK_HOME/lib/hive-hbase-handler-0.13.1.jar:
${SPARK_CLASSPATH} 3.将hbase-site.xml拷贝至HADOOPCONFDIR,由于spark−env.sh中配置了Hadoop配置文件目录HADOOPCONFDIR,由于spark−env.sh中配置了Hadoop配置文件目录{HADOOP_CONF_DIR},因此会将hbase-site.xml加载。
hbase-site.xml中主要是以下几个参数的配置:
hbase.zookeeper.quorum
zkNode1:2181,zkNode2:2181,zkNode3:2181
HBase使用的 zookeeper 节点
hbase.client.scanner.caching
5000
HBase客户端扫描缓存,对查询性能有很大帮助
另外还有一个参数:zookeeper.znode.parent=/hbase
是HBase在zk中的根目录,默认为/hbase,视实际情况进行配置。
4.重启Spark集群。
使用篇
hbase中有表lxw1234,数据如下:
hbase(main):025:0* scan 'lxw1234'
ROW COLUMN+CELL
lxw1234.com column=f1:c1, timestamp=1435624625198, value=name1
lxw1234.com column=f1:c2, timestamp=1435624591717, value=name2
lxw1234.com column=f2:c1, timestamp=1435624608759, value=age1
lxw1234.com column=f2:c2, timestamp=1435624635261, value=age2
lxw1234.com column=f3:c1, timestamp=1435624662282, value=job1
lxw1234.com column=f3:c2, timestamp=1435624697028, value=job2
lxw1234.com column=f3:c3, timestamp=1435624697065, value=job3
1 row(s) in 0.0350 seconds 进入spark-sql,使用如下语句建表:
CREATE EXTERNAL TABLE lxw1234 (
rowkey string,
f1 map,
f2 map,
f3 map
) STORED BY 'org.apache.hadoop.hive.hbase.HBaseStorageHandler'
WITH SERDEPROPERTIES ("hbase.columns.mapping" = ":key,f1:,f2:,f3:")
TBLPROPERTIES ("hbase.table.name" = "lxw1234"); 建好之后,就可以查询了:
spark-sql> select * from lxw1234;
lxw1234.com {"c1":"name1","c2":"name2"} {"c1":"age1","c2":"age2"} {"c1":"job1","c2":"job2","c3":"job3"}
Time taken: 4.726 seconds, Fetched 1 row(s)
spark-sql> select count(1) from lxw1234;
1
Time taken: 2.46 seconds, Fetched 1 row(s)
spark-sql> 大表查询,消耗的时间和通过Hive用 MapReduce 查询差不多。
spark-sql> select count(1) from lxw1234_hbase;
53609638
Time taken: 335.474 seconds, Fetched 1 row(s) 在spark-sql中通过insert插入数据到HBase表时候报错:
INSERT INTO TABLE lxw1234
SELECT 'row1' AS rowkey,
map('c3','name3') AS f1,
map('c3','age3') AS f2,
map('c4','job3') AS f3
FROM lxw1234_a
limit 1;
org.apache.spark.Spark Exception : Job aborted due to stage failure: Task 0 in stage 10.0 failed 4 times,
most recent failure: Lost task 0.3 in stage 10.0 (TID 23, slave013.uniclick.cloud):
java .lang.ClassCastException: org.apache.hadoop.hive.hbase.HiveHBaseTableOutputFormat cannot be cast to org.apache.hadoop.hive.ql.io.HiveOutputFormat
at org.apache.spark.sql.hive.SparkHiveWriterContainer.outputFormat$lzycompute(hiveWriterContainers.scala:74)
at org.apache.spark.sql.hive.SparkHiveWriterContainer.outputFormat(hiveWriterContainers.scala:73)
at org.apache.spark.sql.hive.SparkHiveWriterContainer.getOutputName(hiveWriterContainers.scala:93)
at org.apache.spark.sql.hive.SparkHiveWriterContainer.initWriters(hiveWriterContainers.scala:117)
at org.apache.spark.sql.hive.SparkHiveWriterContainer.executorSideSetup(hiveWriterContainers.scala:86)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable.orgapacheapachesparksqlsqlhiveexecutionexecutionInsertIntoHiveTable$$writeToFile$1(InsertIntoHiveTable.scala:99)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfunsaveAsHiveFilesaveAsHiveFile3.apply(InsertIntoHiveTable.scala:83)
at org.apache.spark.sql.hive.execution.InsertIntoHiveTable$$anonfunsaveAsHiveFilesaveAsHiveFile3.apply(InsertIntoHiveTable.scala:83)
at org.apache.spark.scheduler.ResultTask.runTask(ResultTask.scala:63)
at org.apache.spark.scheduler.Task.run(Task.scala:70)
at org.apache.spark.executor.Executor$TaskRunner.run(Executor.scala:213)
at java.util.concurrent.ThreadPoolExecutor.runWorker(ThreadPoolExecutor.java:1145)
at java.util.concurrent.ThreadPool Executor $Worker.run(ThreadPoolExecutor.java:615)
at java.lang.Thread.run(Thread.java:744)
Driver stacktrace:
at org.apache.spark.scheduler.DAGScheduler.orgapacheapachesparkschedulerschedulerDAGScheduler$$failJobAndIndependentStages(DAGScheduler.scala:1266)
at org.apache.spark.scheduler.DAGScheduler$$anonfunabortStageabortStage1.apply(DAGScheduler.scala:1257)
at org.apache.spark.scheduler.DAGScheduler$$anonfunabortStageabortStage1.apply(DAGScheduler.scala:1256)
at scala.collection.mutable.ResizableArray$class.foreach(ResizableArray.scala:59)
at scala.collection.mutable.ArrayBuffer.foreach(ArrayBuffer.scala:47)
at org.apache.spark.scheduler.DAGScheduler.abortStage(DAGScheduler.scala:1256)
at org.apache.spark.scheduler.DAGScheduler$$anonfunhandleTaskSetFailedhandleTaskSetFailed1.apply(DAGScheduler.scala:730)
at org.apache.spark.scheduler.DAGScheduler$$anonfunhandleTaskSetFailedhandleTaskSetFailed1.apply(DAGScheduler.scala:730)
at scala .Option.foreach(Option.scala:236)
at org.apache.spark.scheduler.DAGScheduler.handleTaskSetFailed(DAGScheduler.scala:730)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1450)
at org.apache.spark.scheduler.DAGSchedulerEventProcessLoop.onReceive(DAGScheduler.scala:1411)
at org.apache.spark.util.EventLoop$$anon$1.run(EventLoop.scala:48) 这个还有待分析。
先看这张图,该图为运行select * from lxw1234_hbase;这张大表查询时候的任务运行图。
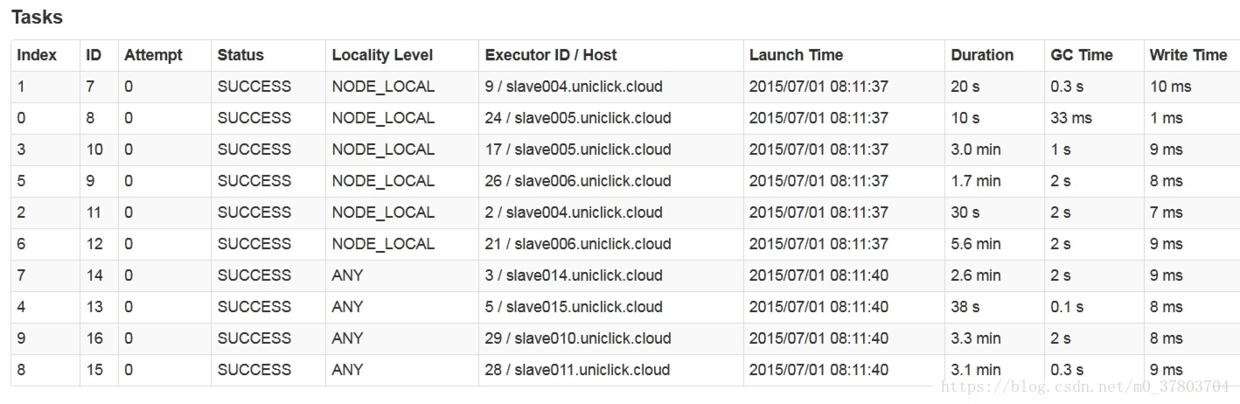
Spark和Hadoop MapReduce一样,在任务调度时候都会考虑数据本地化,即”任务向数据靠拢”,尽量将任务分配到数据所在的节点上运行。
基于这点,lxw1234_hbase为HBase中的外部表,Spark在解析时候,通过org.apache.hadoop.hive.hbase.HBaseStorageHandler获取到表lxw1234_hbase在HBase中的region所在的RegionServer,即:slave004、slave005、slave006 (上面的部署图中提到了,总共只有三台RegionServer,就是这三台),所以,在调度任务时候,首先考虑要往这三台节点上分配任务。
表lxw1234_hbase共有10个region,因此需要10个map task来运行。
再看一张图,这是spark-sql cli指定的Executor配置:

每台机器上Worker的实例为2个,每个Worker实例中运行的Executor为1个,因此,每台机器上运行两个Executor.
那么salve004、slave005、slave006上各运行2个Executor,总共6个,很好,Spark已经第一时间将这6个Task交给这6个Executor去执行了(NODE_LOCAL Tasks)。
剩下4个Task,没办法,想NODE_LOCAL运行,但那三台机器上没有剩余的Executor了,只能分配给其他Worker上的Executor,这4个Task为ANY Tasks。
正如那张任务运行图中所示。
写在后面
通过Hive和spark-sql去访问HBase表,只是为统计分析提供了一定的便捷性,个人觉得性能上的优势并不明显。

可能Spark通过API去读取HBase数据,性能更好些吧,以后再试。
另外,spark-sql有一点好处,就是可以先把HBase中的数据cache到一张内存表中,然后在这张内存表中,
通过SQL去统计分析,那就爽多了。


