本文的目标是探索计算机视觉应用的完整示例:使用深度学习构建面部表情识别系统。我们将看到如何:
- 设计 卷积神经网络
- 通过提供批量图像从头开始训练
- 导出它,用实时图像数据进行重用
工具

Keras 是一个高级神经网络API,用 Python 编写,能够在TensorFlow,CNTK或Theano之上运行。我们将用它来构建,训练和输出神经网络。

Flask 是一个用Python编写的微型Web框架,它允许我们将我们的机器学习模型直接提供给Web界面。

OpenCV 是一个具有C ++,Python和 Java 接口的计算机视觉库。我们将使用此库自动检测图像中的面部。
数据源
数据来源:
该数据由48×48像素的人脸灰度图像组成。每张图片对应的面部表情有七种(0=Angry, 1=Disgust, 2=Fear, 3=Happy, 4=Sad, 5=Surprise, 6=Neutral)。该机器学习数据集包含大约36K幅图像。
原始数据由数组组成,每个像素有一个灰度值。我们将这些数据转换成原始图像,并将它们放到文件夹中:
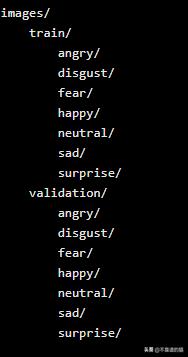
我们80%的图像都包含在train文件夹中,最后20%的图像都在验证文件夹中。
快速数据可视化
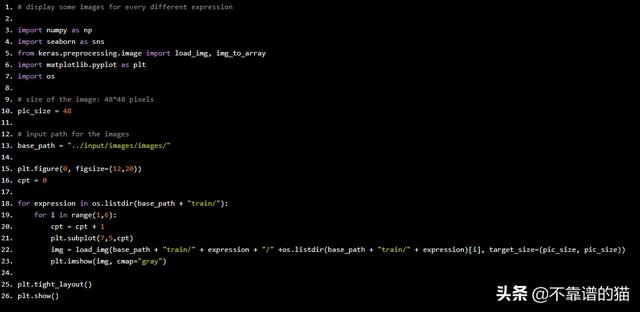
首先让我们看看我们的图像是什么样的,Python代码如下:
# display some images for every different expression import numpy as np import seaborn as sns from keras.preprocessing.image import load_img, img_to_array import matplotlib.pyplot as plt import os # size of the image: 48*48 pixels pic_size = 48 # input path for the images base_path = "../input/images/images/" plt.figure(0, figsize=(12,20)) cpt = 0 for expression in os.listdir(base_path + "train/"): for i in range(1,6): cpt = cpt + 1 plt.subplot(7,5,cpt) img = load_img(base_path + "train/" + expression + "/" +os.listdir(base_path + "train/" + expression)[i], target_size=(pic_size, pic_size)) plt.imshow(img, cmap="gray") plt.tight_layout() plt.show()

训练图像的样本
你能猜出这些图像与哪些表情相关吗?
这项任务对于人类来说非常容易,但对于预测算法来说可能有点挑战,因为:
- 图像分辨率低
- 面部不在同一个位置
- 一些图像上写有文字
- 有些人用手隐藏了部分脸
然而,所有这些图像的多样性将有助于形成更通用的机器学习模型。
# count number of train images for each expression for expression in os.listdir(base_path + "train"): print(str(len(os.listdir(base_path + "train/" + expression))) + " " + expression + " images")

我们的训练机器学习数据集还比较平衡(除了“disgust”类别)。
设置数据生成器
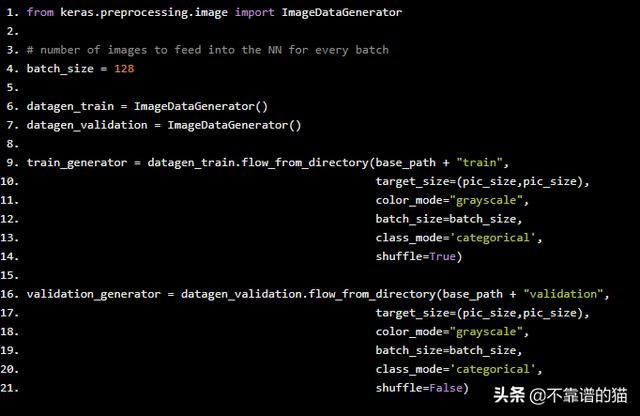
通过提供批量数据来训练深度学习模型。Keras有一个非常有用的类来自动从目录中提供数据:ImageDataGenerator。
from keras.preprocessing.image import ImageDataGenerator # number of images to feed into the NN for every batch batch_size = 128 datagen_train = ImageDataGenerator() datagen_validation = ImageDataGenerator() train_generator = datagen_train.flow_from_directory(base_path + "train", target_size=(pic_size,pic_size), color_mode="grayscale", batch_size=batch_size, class_mode='categorical', shuffle=True) validation_generator = datagen_validation.flow_from_directory(base_path + "validation", target_size=(pic_size,pic_size), color_mode="grayscale", batch_size=batch_size, class_mode='categorical', shuffle=False)
Found 28821 images belonging to 7 classes.
Found 7066 images belonging to 7 classes.
它还可以在获取图像(随机旋转图像,缩放等)时执行数据增强。当机器学习数据集很小时,此方法通常用作人工获取更多数据的方法。
函数flow_from_directory()指定生成器应如何导入图像(路径,图像大小,颜色等)。
设置我们的卷积神经网络(CNN)
我们选择使用卷积神经网络来解决这种人脸识别问题。事实上,这种神经网络(NN)很好地提取了图像的特征,被广泛应用于图像分类等图像分析学科。
神经网络是由多层人工神经元(节点)组成的学习框架。每个节点得到加权的输入数据,将其传递给一个激活函数,输出函数的结果:
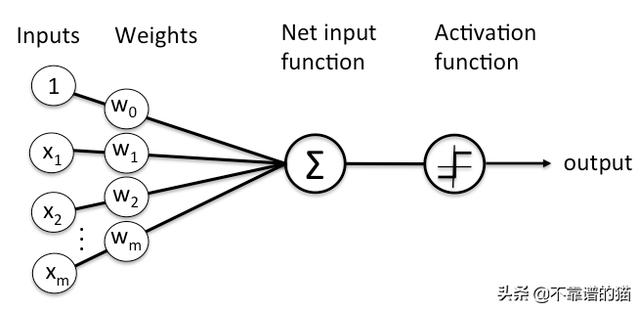
A node
NN由几层节点组成:
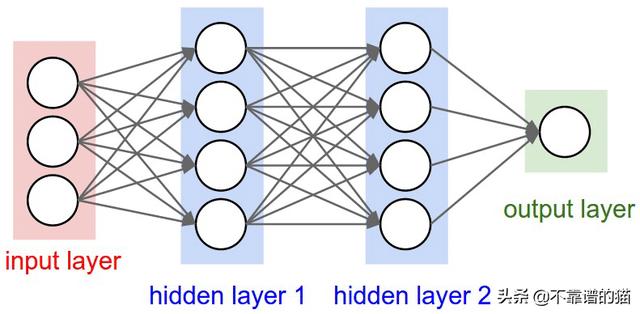
经典的NN架构
- 一个将获取数据的输入层。输入层的大小取决于输入数据的形状。
- 一些隐藏层将允许NN学习数据中的复杂交互。具有大量隐藏层的神经网络称为深度神经网络。
- 将给出最终结果的输出层,例如类预测。这个层的大小取决于我们想要生成的输出类
经典NN通常由几个 全连接层 组成。这意味着一层的每个节点都连接到下一层的所有节点。
卷积神经网络还具有卷积层,其将sliding函数应用于彼此相邻的像素组。因此,这些结构可以更好地理解我们可以在图像中观察到的模式。
现在让我们来定义CNN的架构:
from keras.layers import Dense, Input, Dropout, GlobalAveragePooling2D, Flatten, Conv2D, BatchNormalization, Activation, MaxPooling2D
from keras.models import Model, Sequential
from keras.optimizers import Adam
# number of possible label values
nb_classes = 7
# Initialising the CNN
model = Sequential()
# 1 - Convolution
model.add(Conv2D(64,(3,3), padding='same', input_shape=(48, 48,1)))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 2nd Convolution layer
model.add(Conv2D(128,(5,5), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 3rd Convolution layer
model.add(Conv2D(512,(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# 4th Convolution layer
model.add(Conv2D(512,(3,3), padding='same'))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(MaxPooling2D(pool_size=(2, 2)))
model.add(Dropout(0.25))
# Flattening
model.add(Flatten())
# Fully connected layer 1st layer
model.add(Dense(256))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.25))
# Fully connected layer 2nd layer
model.add(Dense(512))
model.add(BatchNormalization())
model.add(Activation('relu'))
model.add(Dropout(0.25))
model.add(Dense(nb_classes, activation='softmax'))
opt = Adam(lr=0.0001)
model.compile(optimizer=opt, loss='categorical_crossentropy', metrics=['accuracy'])
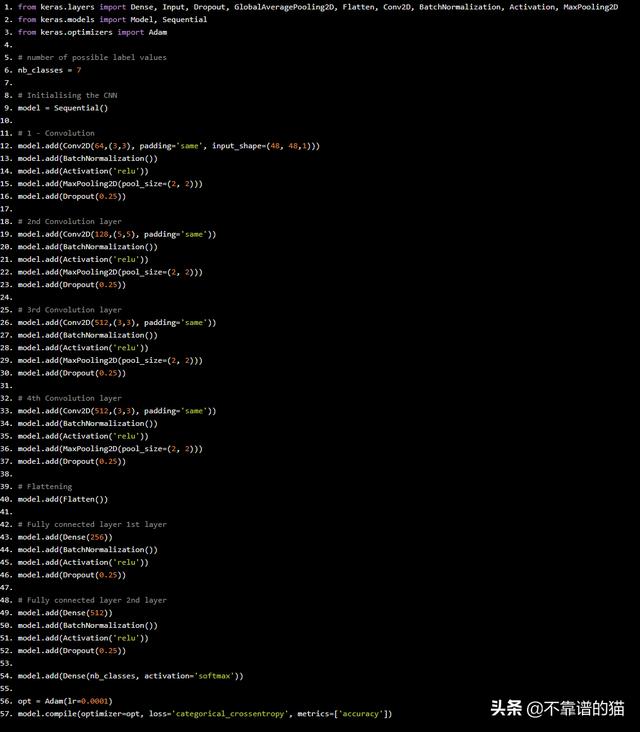
我们使用以下全局架构定义CNN:
- 4个卷积层
- 2个全连接层
卷积层将从图像中提取相关特征,全连接层将集中于使用这些特征来对我们的图像进行分类。
现在让我们关注这些卷积层的工作原理。它们中的每一个都包含以下操作:
- 卷积运算符:使用滑动矩阵从输入图像中提取特征以保留像素之间的空间关系。下图总结了它的工作原理:
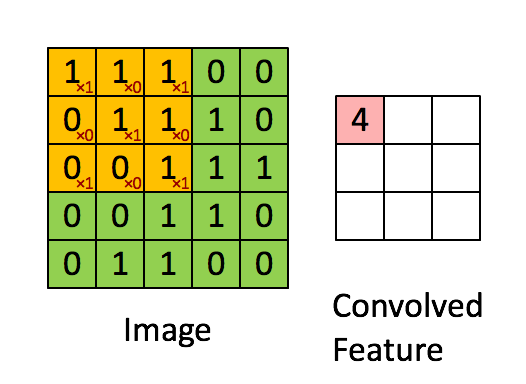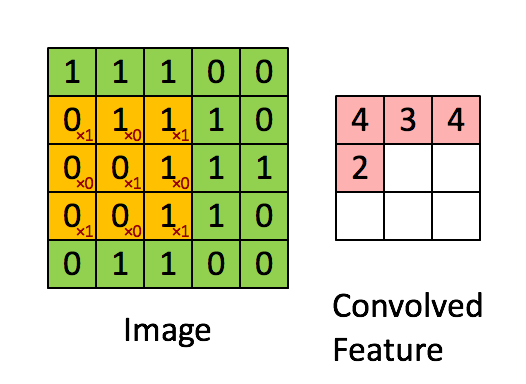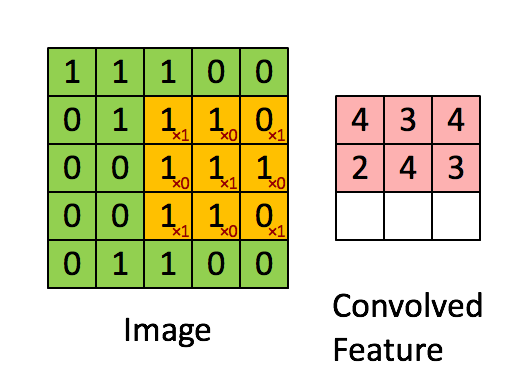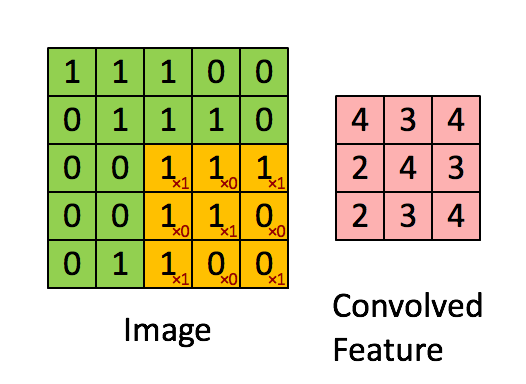
卷积运算符
绿色矩阵对应于原始图像值。橙色滑动矩阵称为“ filter ”或“kernel”。该filter在每个步骤(步幅)上在图像上滑动一个像素。在每个步骤中,我们将filter与基矩阵的相应元素相乘并对结果求和。有不同类型的filters,每个filter都能够检索不同的图像特征:

Different filter results
- 我们应用ReLU函数在CNN中引入非线性。其他函数(如tanh或sigmoid)也可以使用,但已发现ReLU在大多数情况下表现更好。
- 池化用于减少每个特征的维度,同时保留最重要的信息。与卷积步骤一样,我们对数据应用滑动函数。可以应用不同的函数:max,sum,mean 等,max函数通常表现更好。
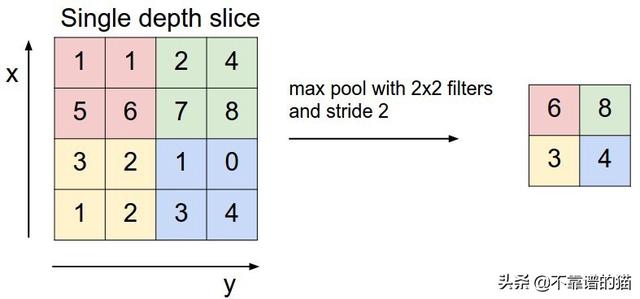
最大池化操作
我们还为每一层使用一些常用技术:
- 批归一化:通过提供零均值和单位方差的输入来提高NN的性能和稳定性。
- Dropout:通过随机更新某些节点的权重来减少过度拟合。这有助于防止NN过多地依赖于层中的一个节点。
我们选择softmax作为我们的最后激活函数,因为它通常用于多标签分类。
现在我们已经定义了CNN,我们可以用更多的参数来编译它。我们选择了Adam优化器,因为它是计算效率最高的之一。我们选择分类交叉熵作为我们的损失函数,因为它与分类任务非常相关。我们的指标将是准确度,这对于平衡机器学习数据集的分类任务也非常有用。
训练模型
一切都准备好了,让我们现在训练我们的深度学习模型吧!Python代码如下:
# number of epochs to train the NN
epochs = 50
from keras.callbacks import ModelCheckpoint
checkpoint = ModelCheckpoint("model_weights.h5", monitor='val_acc', verbose=1, save_best_only=True, mode='max')
callbacks_list = [checkpoint]
history = model.fit_generator(generator=train_generator,
steps_per_epoch=train_generator.n//train_generator.batch_size,
epochs=epochs,
validation_data = validation_generator,
validation_steps = validation_generator.n//validation_generator.batch_size,
callbacks=callbacks_list
)
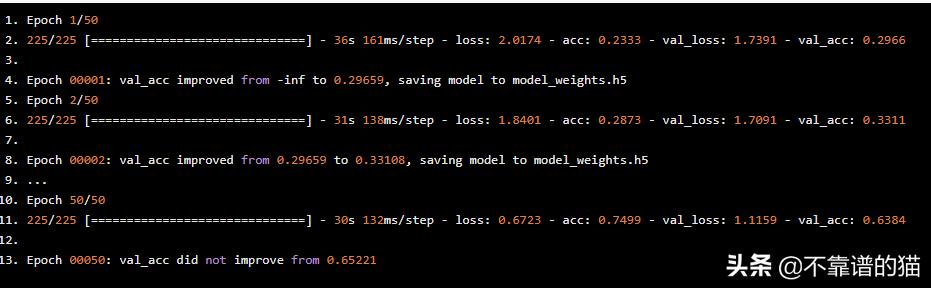
我们最好的机器学习模型设法获得大约65%的验证准确度,这是非常好的,因为我们的目标类有7个可能的值!
在每个epoch,Keras检查我们的模型是否比前一个epoch的模型表现得更好。如果是这种情况,则将新的最佳模型权重保存到文件中。如果我们想在另一种情况下使用它,这将允许我们直接加载机器学习模型的权重而无需重新训练它。
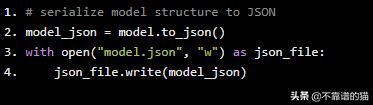
我们还必须将CNN的结构保存到文件中:
# serialize model structure to JSON
model_json = model.to_json()
with open("model.json", "w") as json_file:
json_file.write(model_json)
分析结果
我们在训练阶段的每一步都获得了输出。所有这些输出都保存在“history”变量中。我们可以用它来绘制训练和验证数据集的损失和准确性的演变,Python实现如下:
# plot the evolution of Loss and Acuracy on the train and validation sets
import matplotlib.pyplot as plt
plt.figure(figsize=(20,10))
plt.subplot(1, 2, 1)
plt.suptitle('Optimizer : Adam', fontsize=10)
plt.ylabel('Loss', fontsize=16)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend(loc='upper right')
plt.subplot(1, 2, 2)
plt.ylabel('Accuracy', fontsize=16)
plt.plot(history.history['acc'], label='Training Accuracy')
plt.plot(history.history['val_acc'], label='Validation Accuracy')
plt.legend(loc='lower right')
plt.show()
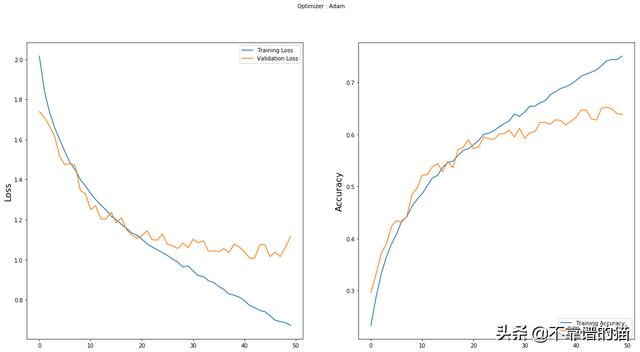
随着训练epochs的数量,损失和准确性的演变
验证准确度在50个epochs结束时开始稳定,准确度在60%到65%之间。
训练损失略高于第一个epoch的验证损失,这可能令人吃惊。事实上,在机器学习中,我们经常看到验证损失比训练损失更大。这是由于dropout的存在,它只应用于训练阶段,而不应用于验证阶段。
我们可以看到,在第20次迭代之后,训练损失要比验证损失小得多。这意味着我们的深度学习模型在经过了太多的时间后开始过度拟合我们的训练数据集。这就是为什么验证损失在之后不会减少很多的原因。一种解决方案是early-stopping模型的训练。
我们还可以使用一些不同的dropout 值并执行数据增强。这些方法在该数据集上进行了测试,但它们没有显著提高验证准确度,尽管它们降低了过度拟合效果。使用它们稍微增加了模型的训练持续时间。
最后,我们可以绘制混淆矩阵,以便了解我们的深度学习模型如何对图像进行分类,Python代码如下:
# show the confusion matrix of our predictions
# compute predictions
predictions = model.predict_generator(generator=validation_generator)
y_pred = [np.argmax(probas) for probas in predictions]
y_test = validation_generator.classes
class_names = validation_generator.class_indices.keys()
from sklearn.metrics import confusion_matrix
import itertools
def plot_confusion_matrix(cm, classes, title='Confusion matrix', cmap=plt.cm.Blues):
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.figure(figsize=(10,10))
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
fmt = '.2f'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.tight_layout()
# compute confusion matrix
cnf_matrix = confusion_matrix(y_test, y_pred)
np.set_printoptions(precision=2)
# plot normalized confusion matrix
plt.figure()
plot_confusion_matrix(cnf_matrix, classes=class_names, title='Normalized confusion matrix')
plt.show()
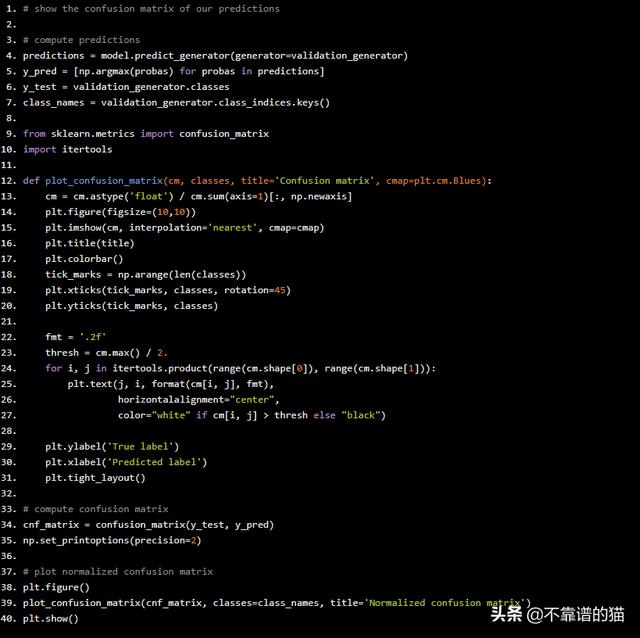
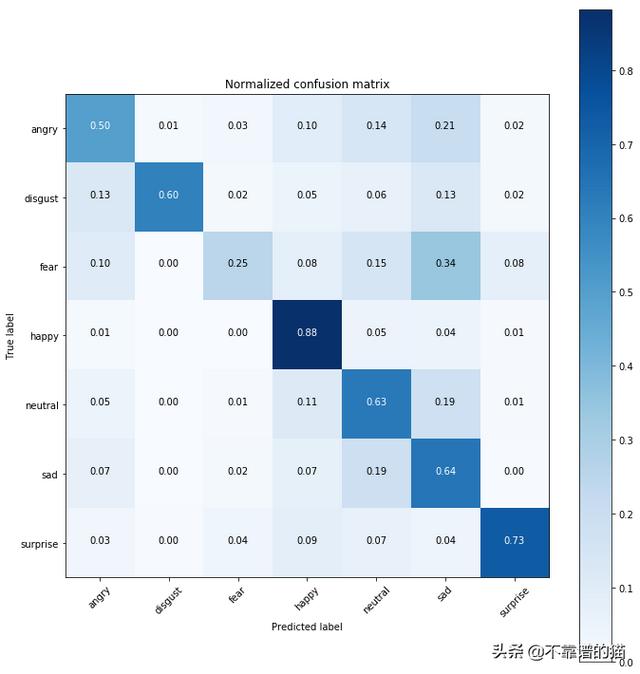
我们的模型非常适合预测happy 和surprised 的面部。然而,由于它将feared的面部与sad的面部混淆在一起,因此它预测的这部分相当糟糕。
随着更多的研究和更多的资源,这个模型当然可以得到改善,但这项研究的目标主要是集中于获得一个相当好的模型。
现在是时候在真实的情况下尝试我们的深度学习模型了!我们将使用flask来为我们的模型提供服务,以便使用网络摄像头输入执行实时预测。
实时预测
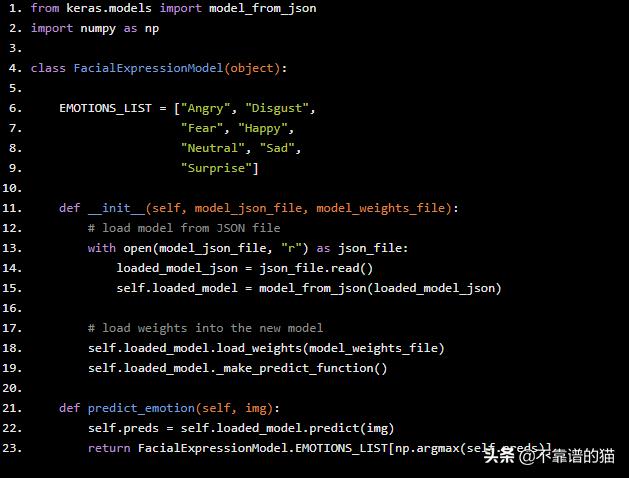
首先让我们创建一个类,它将为我们提供先前训练模型的预测,Python代码如下:
from keras.models import model_from_json import numpy as np class FacialExpressionModel(object): EMOTIONS_LIST = ["Angry", "Disgust", "Fear", "Happy", "Neutral", "Sad", "Surprise"] def __init__(self, model_json_file, model_weights_file): # load model from JSON file with open(model_json_file, "r") as json_file: loaded_model_json = json_file.read() self.loaded_model = model_from_json(loaded_model_json) # load weights into the new model self.loaded_model.load_weights(model_weights_file) self.loaded_model._make_predict_function() def predict_emotion(self, img): self.preds = self.loaded_model.predict(img) return FacialExpressionModel.EMOTIONS_LIST[np.argmax(self.preds)]
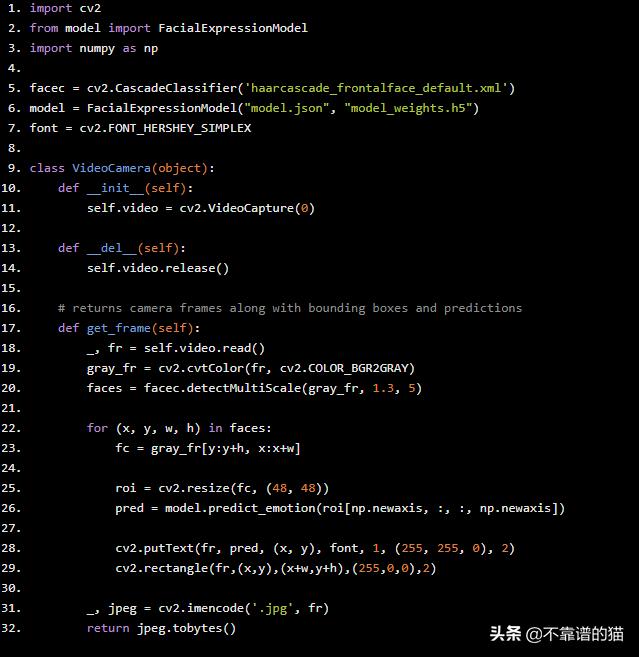
接下来,我们实现一个camera类,它将执行以下操作:
- 从我们的网络摄像头获取图像流
- 使用OpenCV检测面并添加边界框
- 将面转换为灰度,rescale它们并将它们发送到我们预先训练的神经网络
- 从我们的神经网络获取预测并将标签添加到网络摄像头图像
- 返回最终的图像流
import cv2
from model import FacialExpressionModel
import numpy as np
facec = cv2.CascadeClassifier('haarcascade_frontalface_default.xml')
model = FacialExpressionModel("model.json", "model_weights.h5")
font = cv2.FONT_HERSHEY_SIMPLEX
class VideoCamera(object):
def __init__(self):
self.video = cv2.VideoCapture(0)
def __del__(self):
self.video.release()
# returns camera frames along with bounding boxes and predictions
def get_frame(self):
_, fr = self.video.read()
gray_fr = cv2.cvtColor(fr, cv2.COLOR_BGR2GRAY)
faces = facec.detectMultiScale(gray_fr, 1.3, 5)
for (x, y, w, h) in faces:
fc = gray_fr[y:y+h, x:x+w]
roi = cv2.resize(fc, (48, 48))
pred = model.predict_emotion(roi[np.newaxis, :, :, np.newaxis])
cv2.putText(fr, pred, (x, y), font, 1, (255, 255, 0), 2)
cv2.rectangle(fr,(x,y),(x+w,y+h),(255,0,0),2)
_, jpeg = cv2.imencode('.jpg', fr)
return jpeg.tobytes()
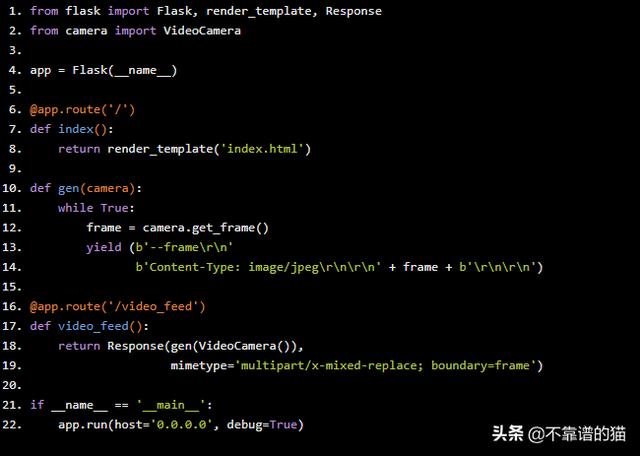
最后,我们的主脚本将创建一个Flask应用程序,将我们的图像预测呈现到网页中。
from flask import Flask, render_template, Response
from camera import VideoCamera
app = Flask(__name__)
@app.route('/')
def index():
return render_template('index.html')
def gen(camera):
while True:
frame = camera.get_frame()
yield (b'--framern'
b'Content-Type: image/jpegrnrn' + frame + b'rnrn')
@app.route('/video_feed')
def video_feed():
return Response(gen(VideoCamera()),
mimetype='multipart/x-mixed-replace; boundary=frame')
if __name__ == '__main__':
app.run(host='0.0.0.0', debug=True)
这是结果!
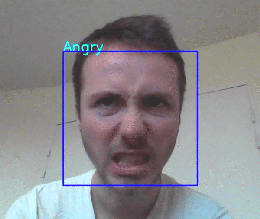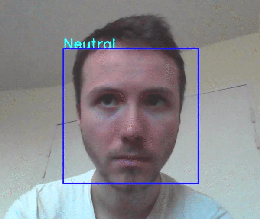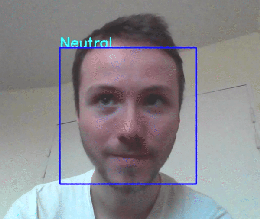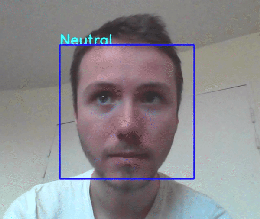
我们的应用程序能够检测面部位置并预测正确的表达。
然而,这个模型似乎在恶劣的条件下工作不佳(低光,不面对镜头的人,移动的人……),但这仍然是一个好的开始!


