Hive 介绍
最初 Hive 是由 Facebook 开发的,主要用于查询 Hadoop 集群当中的数据。后来 Apache 软件基金会接受了它,并以 Apache hive 的名义将其进一步开发为开源,被大家所熟悉和使用,作为一个数据仓库基础设施工具。
因为,从Hadoop教程中,我们了解到想在Hadoop集群上简单的获取数据,都需要利用Hadoop api编写一段程序,才能够获取到想要的数据。这是需要一个有经验的 java 开发人员,因此引入Hive的目的就是想像操作关系型数据库一样,通过简单SQL语句来获取数据结果。
Hive不仅提供了一个熟悉SQL的用户所能熟悉的编程模型, 还消除了大量的通用代码,甚至是那些有时是不得不使用 Java 编写的令人棘手的代码。 这就是为什么Hive对于Hadoop是如此重要的原因,无论用户是 DBA 还是Java开发 工程师。Hive可以让你花费相当少的精力就可以完成大量的工作。
Hive的特点
- 它将模式存储在数据库中并将处理后的数据存储到 HDFS 中。
- 它是为 OLAP 设计的。
- 它提供用于查询的 SQL 类型语言,称为 HiveQL 或 HQL。
- 它熟悉、快速、可扩展和可扩展。
Hive体系结构:
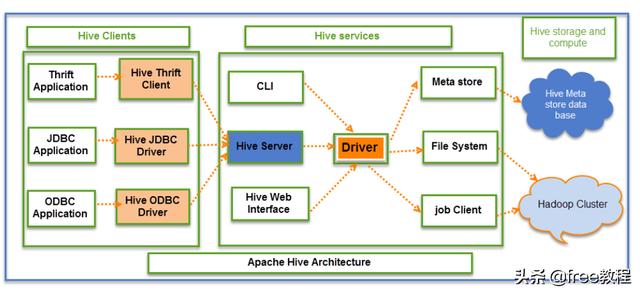
从上图可以看出HIve主要有3个核心部分组成:
- 1、hive客户端(hive clients)
- 2、hive服务(hive services)
- 3、hive存储和计算(hive storage and compute)
hive客户端:
hive客户端是提供hive服务与外界交互的驱动程序,外界想和hive进行交互,都得通过hive客户端。比如:
- 对于基于 Thrift 的应用程序,它将提供 Thrift 客户端进行通信。
- 对于Java相关的应用程序,它提供了 JDBC 驱动程序。
- 对于其它应用程序,还提供了 ODBC 的驱动程序。
- 这些客户端和驱动程序又在 Hive 服务中再次与 Hive 服务器进行通信。
hive服务:
客户端与 Hive 的交互可以通过 Hive 服务执行。如果客户端想要在 Hive 中执行任何与查询相关的操作,它必须通过 Hive 服务进行通信。
所有驱动程序都与 Hive 服务器和 Hive 服务中的主驱动程序通信,如上图所示。
Hive 服务中的驱动程序代表主驱动程序,它与所有类型的 JDBC、ODBC 和其他客户端特定应用程序进行通信。驱动程序将处理来自不同应用程序到元存储和Hadoop集群的请求。
hive存储和计算:
Meta 存储、文件系统、Job Client 等 Hive 服务依次与 Hive 存储通信并执行以下操作
- 在 Hive 中创建的表的元数据信息是存储在 Hive元存储数据库当中中。
- 查询结果和加载到表中的数据将存储在Hadoop分布式集群上。
Hive查询的执行流程
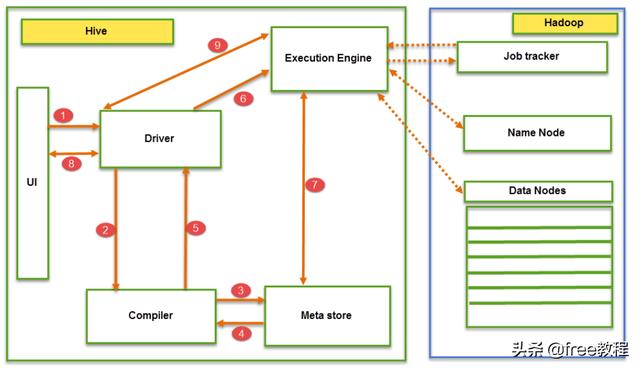
从上图,我们详细讲解以下Hive中一个查询操作的数据流程:
- 1、用户执行hive查询,从用户界面。
- 2、驱动程序(driver)与编译器(Compiler )进行交互,根据用户查询语句获取执行计划,以及流程当中需要的相关元数据信息。
- 3、然后,编译器为要执行的计划,从元数据存储(meta store)那里获取元数据请求。
- 4、元数据存储返回信息给编译器。
- 5、编译器和驱动程序通信,返回执行查询的计划。
- 6、驱动程序把执行计划发送到执行引擎进行执行。
- 7、执行引擎( execution engine)根据执行计划,从Hadoop集群获取数据。这里元数据再次充当了Hive表和Hadoop之间的桥梁。让Hadoop知道从哪里获取数据。
- 8、从驱动程序获取结果。
- 9、一旦从数据节点获取结果到执行引擎,它就会将结果发送回驱动程序和 UI(前端)。


