
卷积神经网络 通常从训练数据中学习有用的特征。根据任务的不同,第一个卷积层的特征可能是训练数据的基本特征。例如,在图像数据中,学习到的特性可以表示边缘和blob。在网络的后续层中,学习到的特性可以表示更抽象、更高级的实体。
在实践中,网络架构的深度几乎总是比只有几个层的深度要深得多,这使得很难从视觉上解释和分析所学习的特性,因为卷积核的总量很大。
在接下来的实验中,我们将图像处理和计算机视觉中边缘检测的典型方法Sobel边缘 滤波 应用到数据集中,训练我们的模型执行类似的线性映射。我们还试图从内核大小比Sobel过滤情况稍微大一点的数据中学习更任意的线性过滤器。
这个演示希望建立了关于神经网络中卷积层如何对输入数据进行操作的直觉,卷积核如何在训练过程中对进程进行加权,以及神经网络的训练如何被视为一个最小化问题。
首先,我们必须对输入的图像数据X应用线性过滤器,以获得原始图像的经过过滤的Y版本。在形式上,线性滤波操作可以概括为:

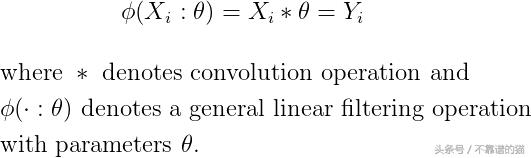
对于我们可以想到的任何参数集(卷积核)或输入数据,线性滤波器是一个定义明确的操作。
我们现在可以构建一个单层,单核,卷积神经网络,它近似于线性滤波操作。毕竟,在两种情况下,在线性滤波器和卷积神经网络中执行的计算与卷积核参数的差异完全相同,我们即将从数据中学习。
我们可以在线性滤波器和卷积神经网络之间建立以下连接:

学习任务现在可以表示为最小化问题,其中线性滤波器的输出和卷积神经网络的输出之间的均方误差被最小化:

应用于图像数据的线性滤波器的参数称为卷积核。我们将通过首先在x方向上然后在y方向上用称为Sobel算子的3×3卷积核过滤图像数据来开始我们的实验。

对于实验,我们将使用在 TensorFlow 上运行的Keras框架。
Sobel 滤波器在x方向上
首先,我们必须为图像预处理定义一些辅助功能。加载数据集,将图像转换为灰度,对图像强度范围进行归一化,并对数据集中的每个图像执行线性滤波。
作为训练和测试数据,我们将利用计算收集的城市和自然场景类别 – 数据集(Oliva, A. & Torralba, A. (2001).Modeling the Shape of the Scene: A Holistic Representation of the Spatial Envelope) 由计算视觉认知实验室收集, 麻省理工学院 。(
原始数据集由八个类别的自然场景彩色图像(分辨率:256 x 256)组成,我们使用三个类别:街道,城市中心和高层建筑。这样,我们获得足够大小的训练和测试集(764个训练样本和192个测试样本),以便训练不会过度拟合,并且训练也可以通过在合理的时间范围内使用更温和的硬件来执行。所选类别代表具有强边缘的自然场景(人类构建结构的大范围),这有助于我们比较结果。
下面,我们可以观察属于数据集的原始图像的 可视化 ,灰度转换和图像的Sobel过滤版本:

原始图像(左),灰度图像(中)和Sobel过滤图像的x方向(右
我们将仅在单通道图像上使用线性滤波器。在实践中,这意味着训练模型以将灰度转换图像映射到Sobel滤波图像。
接下来,我们定义模型:单层,单核,具有线性激活的卷积网络,即激活函数是身份。卷积核大小选择为3 x 3,以符合Sobel滤波器大小。
具有Nesterov momentum 的随机梯度下降优化器用于训练100个时期的模型。在每个时期,保存卷积层权重以进一步可视化。
input_height, input_width = gray_img.shape
def linearcnn_model():
# Returns a convolutional neural network model with a single linear convolution layer
model = Sequential()
model.add(Conv2D(1, (3,3), padding=’same’, input_shape=(input_height, input_width, 1)))
return model
model = linearcnn_model()
sgd = optimizers.SGD(lr=1e-2, decay=1e-6, momentum=0.9, nesterov=True)
model.compile(optimizer=sgd, loss=’mean_squared_error’, metrics=[‘accuracy’])
model.summary()
number_of_epochs = 100
loss = []
val_loss = []
convweights = []
for epoch in range(number_of_epochs):
history_temp = model.fit(grayimages, filteredimages,
batch_size=4,
epochs=1,
validation_split=0.2)
loss.append(history_temp.history[‘loss’][0])
val_loss.append(history_temp.history[‘val_loss’][0])
convweights.append(model.layers[0].get_weights()[0].squeeze())
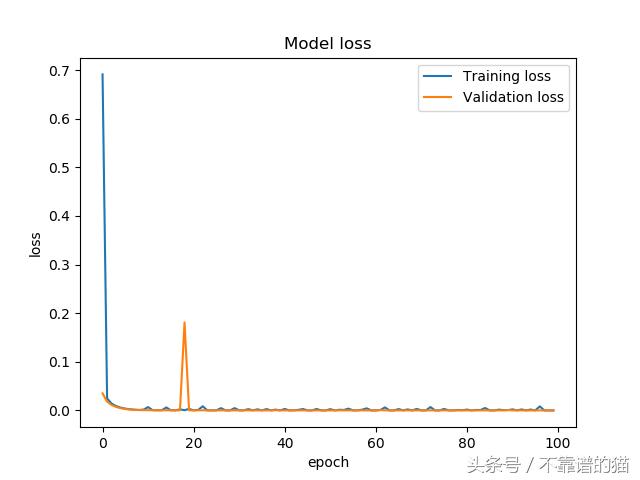
训练结束后,我们可以绘制训练和验证损失,以确定训练是否过度拟合
# Plot the training and validation losses
plt.close(‘all’)
plt.plot(loss)
plt.plot(val_loss)
plt.title(‘Model loss’)
plt.xlabel(‘epoch’)
plt.ylabel(‘loss’)
plt.legend([‘Training loss’, ‘Validation loss’], loc=’upper right’)
plt.show()
plt.savefig(‘trainingvalidationlossgx.png’)
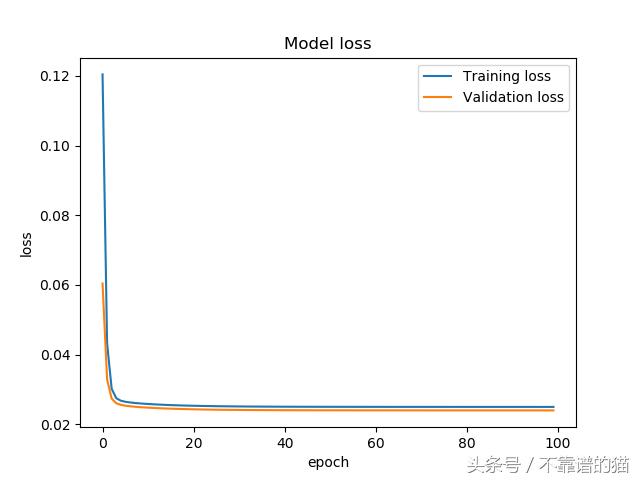
在整个训练过程中,训练和验证的损失是稳定的,并且模型似乎是收敛的。
现在可以将每个epoch 的保存权重可视化为矩阵格式的数值,以及更可视的格式,其中数值表示可视化中的像素强度值。声明用于执行可视化的功能,并且为每个epoch 创建可视化。
def visualize_matrix(M, epoch=1):
“””
Create a visualization of an arbitrary matrix.
“””
fig = plt.figure(figsize=(10,5))
ax1 = plt.subplot(1,2,1)
ax2 = plt.subplot(1,2,2)
title = “Epoch {}”.format(epoch)
fig.suptitle(title, fontsize=20)
height, width = M.shape
Mud = np.flipud(M) # Now the i-index complies with matplotlib axes
coordinates = [(i,j) for i in range(height) for j in range(width)]
print(coordinates)
for coordinate in coordinates:
i,j = coordinate
value = np.round(Mud[i,j], decimals=2)
relcoordinate = (j/float(width), i/float(height))
ax1.annotate(value, relcoordinate, ha=’left’, va=’center’,
size=22, alpha=0.7, family=’serif’)
padding = 0.25
wmargin = (width-1)/float(width) + padding
hmargin = (height-1)/float(height) + padding
hcenter = np.median(range(height))/float(height)
print(hcenter)
hcenter = hcenter + 0.015 # Offset due to the character alignment
bracket_d = 0.4
bracket_b = 0.05
bracket_paddingl = 0.05
bracket_paddingr = -0.05
ax1.plot([-bracket_paddingl, -bracket_paddingl],[hcenter-bracket_d, hcenter+bracket_d], ‘k-‘, lw=2, alpha=0.7)
ax1.plot([-bracket_paddingl, -bracket_paddingl+bracket_b], [hcenter-bracket_d, hcenter-bracket_d], ‘k-‘, lw=2, alpha=0.7)
ax1.plot([-bracket_paddingl, -bracket_paddingl+bracket_b], [hcenter+bracket_d, hcenter+bracket_d], ‘k-‘, lw=2, alpha=0.7)
ax1.plot([wmargin-bracket_paddingr, wmargin-bracket_paddingr],[hcenter-bracket_d, hcenter+bracket_d], ‘k-‘, lw=2, alpha=0.7)
ax1.plot([wmargin-bracket_paddingr-bracket_b, wmargin-bracket_paddingr], [hcenter-bracket_d, hcenter-bracket_d], ‘k-‘, lw=2, alpha=0.7)
ax1.plot([wmargin-bracket_paddingr-bracket_b, wmargin-bracket_paddingr], [hcenter+bracket_d, hcenter+bracket_d], ‘k-‘, lw=2, alpha=0.7)
ax1.set_xlim([-padding, wmargin+0.06])
ax1.set_ylim([-padding, hmargin])
ax1.get_xaxis().set_visible(False)
ax1.get_yaxis().set_visible(False)
ax1.axis(‘off’)
matshowplt = ax2.matshow(M, cmap=’gray’, vmin=-2, vmax=2)
cbar = plt.colorbar(matshowplt, ax=ax2, fraction=0.046, pad=0.04)
cbar.ax.tick_params(labelsize=18)
cbar.ax.get_yaxis().labelpad = 20
cbar.ax.set_ylabel(‘Weight value’, rotation=270, fontsize=20)
ax2.get_xaxis().set_visible(False)
ax2.get_yaxis().set_visible(False)
plt.tight_layout()
plt.subplots_adjust(wspace=0.5)
return fig
savefolder = ‘images/’
for i in range(len(convweights)):
savepath = savefolder+’weightfigure’+str(i)+’.png’
print(savepath)
M = convweights[i]
fig = visualize_matrix(M, epoch=i+1)
fig.savefig(savepath)
plt.close(fig)
现在我们已经为每个epoch创建了可视化,我们可以从中创建一个gif,看看权重如何进展。
import imageio
from natsort import natsorted
# Get the paths to the convolution weight visualization images
image_dir = ‘images/’
imagepaths = [os.path.join(image_dir, fname) for fname in os.listdir(image_dir) if fname.endswith(‘.png’)]
imagepaths = natsorted(imagepaths)
with imageio.get_writer(‘weightmoviegx.gif’, mode=’I’) as writer:
for impath in imagepaths:
image = imageio.imread(impath)
writer.append_data(image)
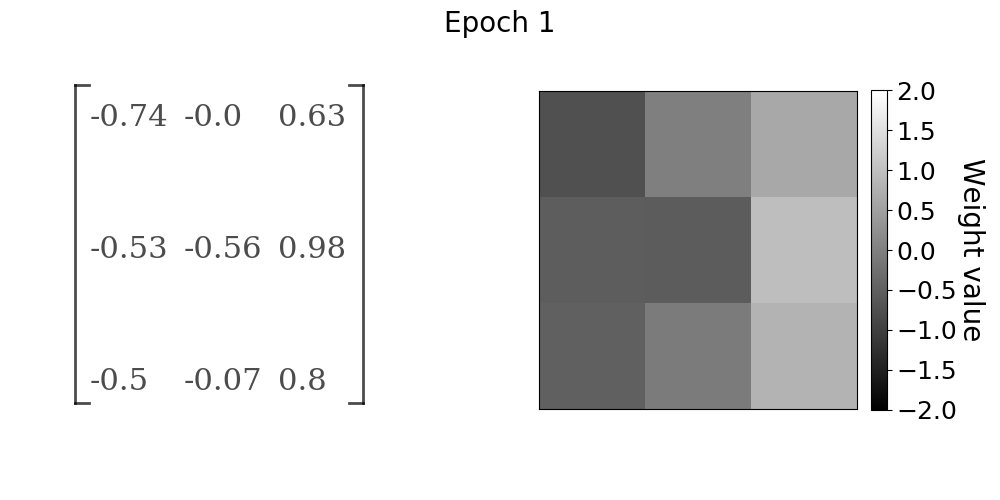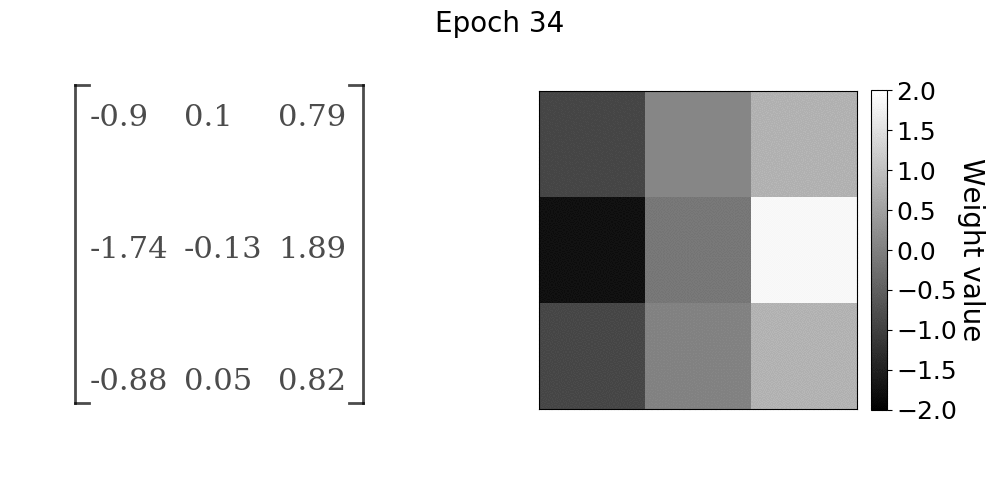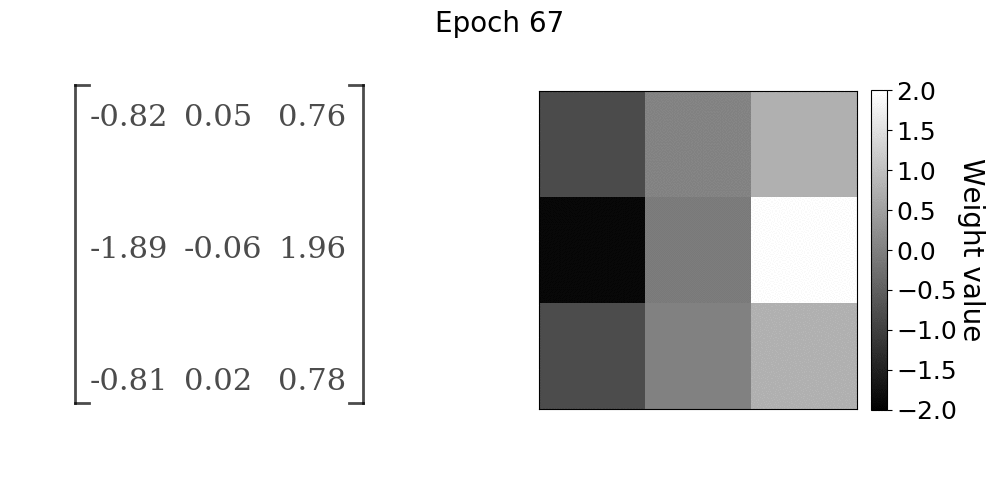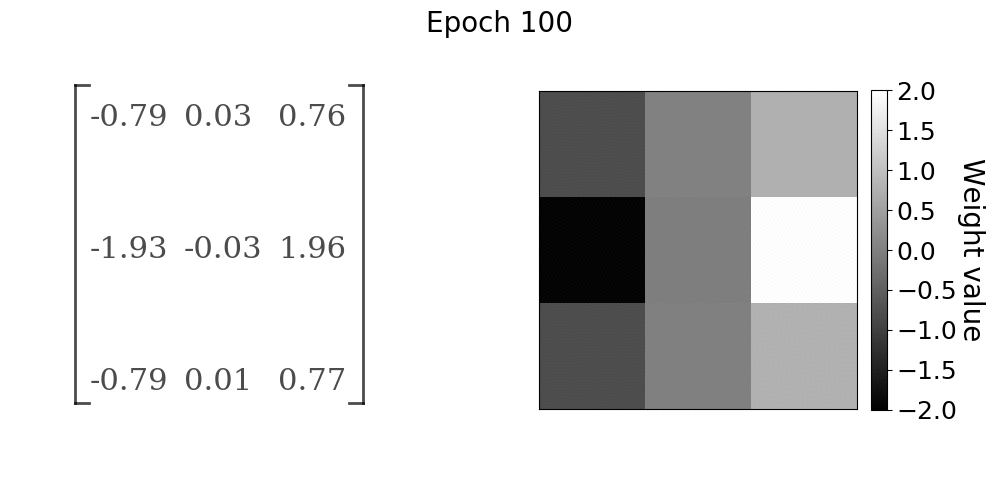
随着模型的训练,卷积层权重的进展。权重值在x方向上接近Sobel算子
在gif中,随着学习的进展,卷积核权重如何向Sobel x方向滤波器收敛是非常明显的。前10到15个epochs的收敛速度很快,之后收敛率明显下降。如果学习任务比我们在本实验中使用的简单线性过滤操作更复杂,我们仍然会看到类似的行为。卷积核值将收敛到某种最佳配置,从数据中提取有用的特征。在该实验中,有用的特征是由Sobel算子给出的图像x方向上的边缘。我们能够找到几乎精确的卷积核参数,这些参数在第一手资料中产生了训练数据,主要是因为我们的问题陈述非常简单。然而,
为了测试模型,我们可以看到模型的预测与x方向上的Sobel滤波相比如何。
predicted_img = model.predict(np.array([np.expand_dims(gray_img, -1)]))
predicted_img = predicted_img.squeeze()
margin_img = np.ones(shape=(256, 10, 3))
combined_image = np.hstack((np.dstack((normalize_image(predicted_img),)*3), margin_img, np.dstack((normalize_image(filtered_img),)*3)))
cv2.imwrite(‘PredictedFiltered_sobelx.png’, (255.0*combined_image).astype(np.uint8))

模型的输出(左)和使用Sobel算子在x方向(右)过滤的相同图像
在图中(顶部),我们可以观察模型的输出和Sobel滤波在x方向上的并排结果。视觉检查,两个图像看起来相似。事实上,在强度值中,当学习的卷积核收敛到接近原始Sobel算子的值时,应该只发现图像之间的微小差异。
Sobel 滤波器在y方向上
同样可以使用相同的代码对Sobel算子在y方向进行线性滤波。我们所要做的就是改变图像滤波函数,使其在y方向而不是x方向上进行滤波,再次加载和过滤训练数据,并用新的数据对模型进行训练
def filter_image(img):
# Perform filtering to the input image
sobely = cv2.Sobel(img, cv2.CV_32F, 0, 1, ksize=3)
return sobely
在下面的图中,我们可以观察到Sobel过滤器现在如何强调垂直方向(y方向)的图像强度边缘。

原始图像(左),灰度图像(中)和Sobel过滤后的y方向图像(右)
再一次,我们可以观察当网络从训练数据中学习时,卷积核如何在y方向上对Sobel滤波器进行加权。收敛行为与Sobel算子在x方向上的前一种情况非常相似
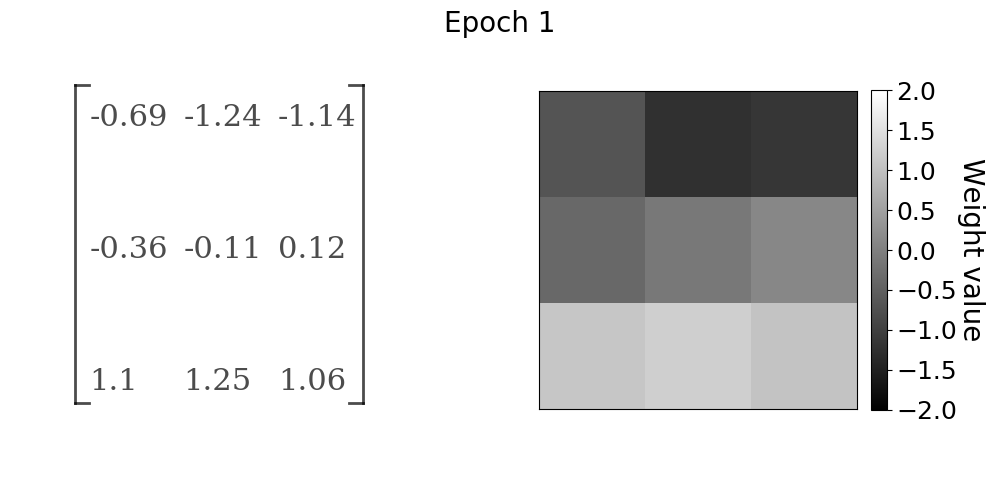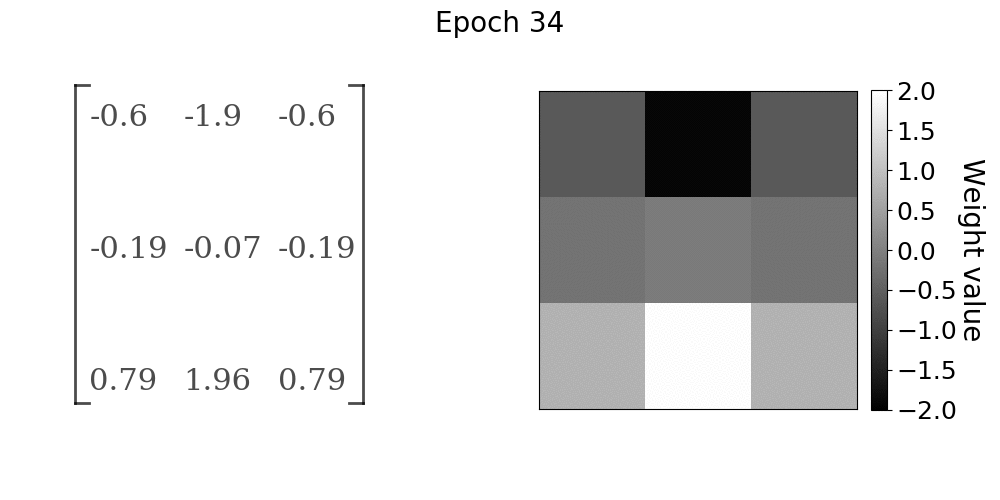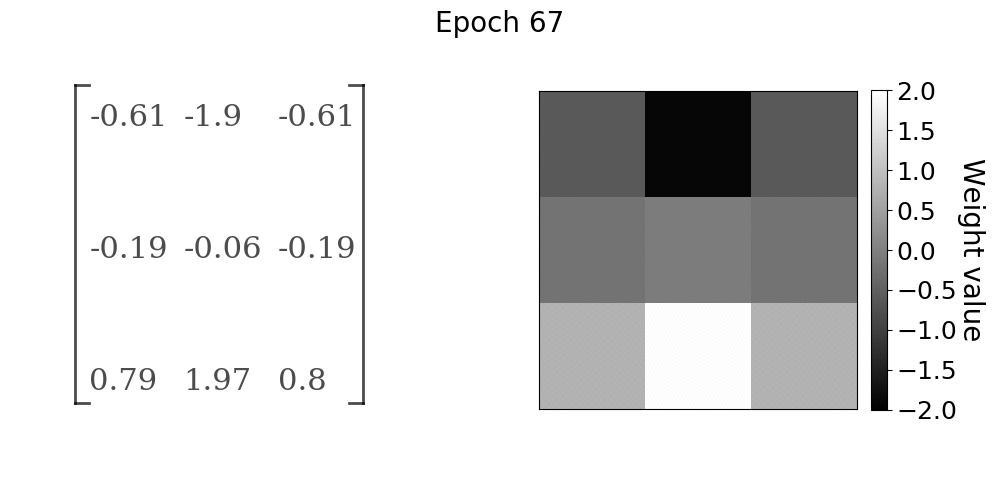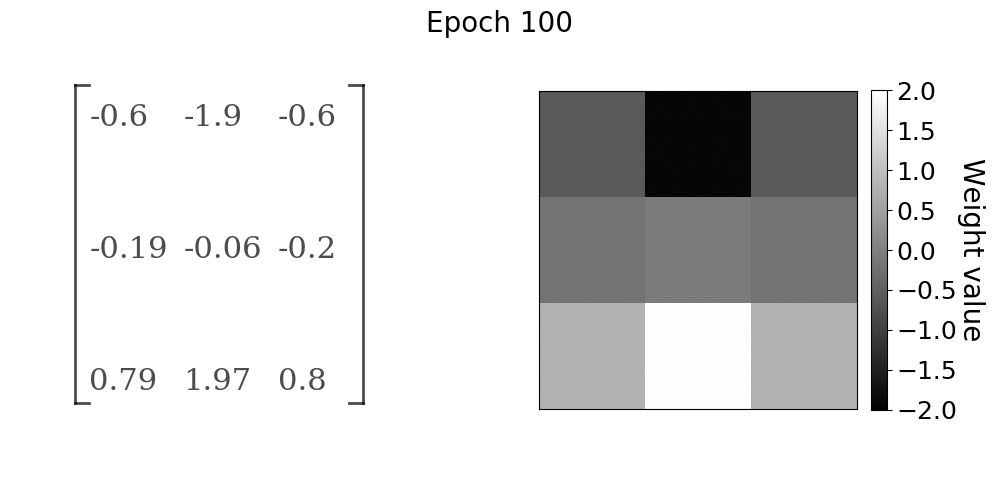
随着模型的训练,卷积层权重的进展。权重值在y方向上接近Sobel算子
同样,模型的输出和相同测试图像的Sobel滤波版本(如下图所示)具有相似的外观。对于人眼来说,不可能分辨出两幅图像之间的区别

模型的输出(左)和使用Sobel算子在y方向(右)过滤的相同图像
笑脸过滤器
之前学到的Sobel滤波器非常简单,只需要学习少量参数。让我们看看,如果我们可以学习具有更大内核的线性滤波器。
我们将在下面的实验中使用的滤镜内核是一个32 x 32像素的笑脸。加载滤波器内核并通过使用笑脸内核过滤灰度图像来创建训练数据。由于内核大,内核基本上延伸到图像边界之外。图像边界用零填充以抵消由于卷积而导致的图像分辨率的缩小。
def load_kernel(path=’kernels/smiley_32.png’):
# Load a kernel image into numpy array
kernel = cv2.imread(path, 0)
kernel = cv2.bitwise_not(kernel).astype(np.float32)
# Normalize according to the L2-norm
kernel = kernel/np.linalg.norm(kernel)
return kernel
def filter_image(img, kernel):
# Perform filtering to the input image
convolved = cv2.filter2D(img, cv2.CV_32F, kernel, borderType=cv2.BORDER_CONSTANT)
return convolved

The normalized smiley face filter kernel
在下面的图中,我们可以看到笑脸过滤后的图像与原始的和灰度转换后的图像相比是什么样子

原始图像(左),灰度图像(中)和笑脸过滤图像(右)
我们的模型再次是一个简单的单层,单核,卷积神经网络,其中激活函数是同一性的。这次,我们根据笑脸内核的大小将内核大小设置为32 x 32。作为对先前实验的增强,我们将基本随机梯度下降优化器更改为更强大的Adam优化器。
input_height, input_width = gray_img.shape
def linearcnn_model():
# Returns a convolutional neural network model with a single linear convolution layer
model = Sequential()
model.add(Conv2D(1, (32,32), padding=’same’, input_shape=(input_height, input_width, 1)))
return model
model = linearcnn_model()
adam = optimizers.Adam(lr=1e-3)
model.compile(optimizer=adam, loss=’mean_squared_error’, metrics=[‘accuracy’])
model.summary()
number_of_epochs = 100
loss = []
val_loss = []
convweights = []
for epoch in range(number_of_epochs):
history_temp = model.fit(grayimages, filteredimages,
batch_size=1,
epochs=1,
validation_split=0.2)
loss.append(history_temp.history[‘loss’][0])
val_loss.append(history_temp.history[‘val_loss’][0])
convweights.append(model.layers[0].get_weights()[0].squeeze())
该模型被训练100个epochs,并且在每个时期存储卷积核权重。训练和验证损失在大约10个epochs内快速收敛,之后在两个损失值中都可以看到小的波动
现在可以将存储的卷积核权重值可视化并组合成gif。结果很有启发性:该模型似乎很好地学习了原始的笑脸过滤内核,这可以在下面的gif中观察到。卷积核权重相对较早地采用笑脸的形状,大约在十个epochs之后,但是权重仍包含大量噪声。随着训练的进行,噪声逐渐消失,相邻的权重值相对于彼此变得更加恒定。
通过分析验证损失和卷积核权重的进展,可以进行重要的观察。即使在第十个epoch之后验证损失看起来平缓,卷积核权重仍然朝向原始的笑脸内核产生足够的量。训练和验证损失曲线的线性标度可能会不时产生误导,因为初始损失值可能在损失测量的后期改进中主导损失可视化。
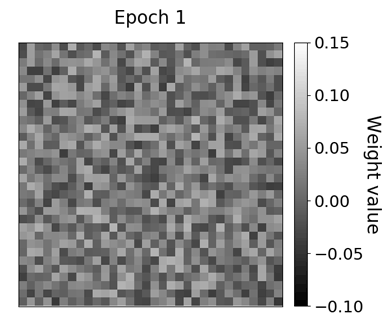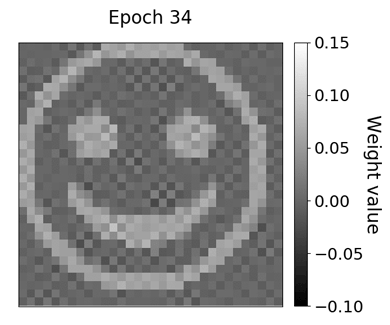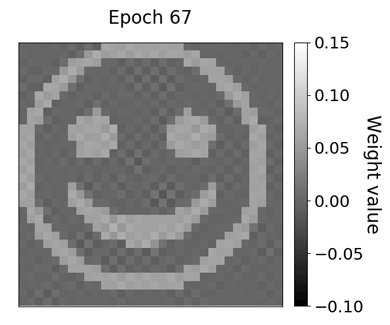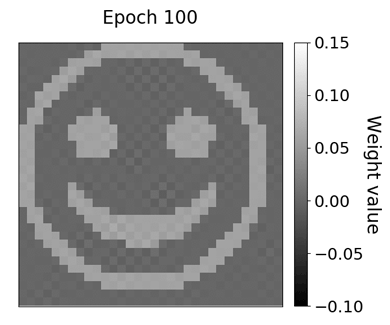
随着模型的训练,卷积层权重的进展。权重值收敛于笑脸过滤器附近。
现在我们有一个训练有素的模型,我们可以可视化和比较模型的输出和笑脸过滤测试图像的结果。在下图中,我们可以观察模型和笑脸过滤器内核如何产生与测试图像类似的外观。类似于Sobel滤波图像,以及由数据学习Sobel滤波器的模型产生的图像,很难将笑脸滤波图像与模型的输出区分开。

模型的输出(左)和用笑脸内核(右)过滤的相同图像
最后的话
我希望线性滤波器的三个实验能充分地说明,当网络从数据中学习时,卷积核的权值是如何发展的。此外,我希望您能够了解一些知识,以便理解卷积层对输入数据的操作方式。这些实验的结果并没有直接推广到卷积神经网络在图像分类中使用的情况,而是为理解卷积层背后的现象和学习作为一个优化问题提供了基础。


