这次终于要说一下协程了,说之前先说一下并发和并行的区别,下面是引用别人写的一段描述
Go不支持创建系统线程,所以协程是一个Go程序内部唯一的并发实现方式,下面我们看一段协程的使用代码。
// wg 用来等待程序完成
// 计数加 2,表示要等待两个 goroutine
var wg sync.WaitGroup
wg.Add(2)
// 声明一个匿名函数,并创建一个 goroutine
go func() {
// 在函数退出时调用 Done 来通知 main 函数工作已经完成
defer wg.Done()
// 等待 goroutine 结束
fmt.Println("Waiting To Finish")
wg.Wait()
}()
WaitGroup就相当于Java中的CountDownLatch,用法也是类似的,先初始化一个计数,调用一下Done()就会计数减一,调用Wait()方法的地方会一直阻塞,直到计数变为0便可以继续向下执行。
启动一个协程只需要调用的方法前加个go关键字就可以了,相当于java起了个线程去执行这个函数,上面示例中调用的是一个匿名函数。还有一个defer的关键字说明一下,defer后面的函数调用也叫延迟函数调用。简单地说,defer后面的函数调用并不会马上执行,而是等待整个协程执行完以后,最后再去调用defer修饰的函数。
当一个函数调用被延迟后,它不会立即被执行。它将被推入由当前协程维护的一个延迟调用堆栈。 当 一个函数调用(可能是也可能不是一个延迟调用)返回并进入它的退出阶段后,所有在此函 数调用中已经被推入的延迟调用将被按照它们被推入堆栈的顺序逆序执行。
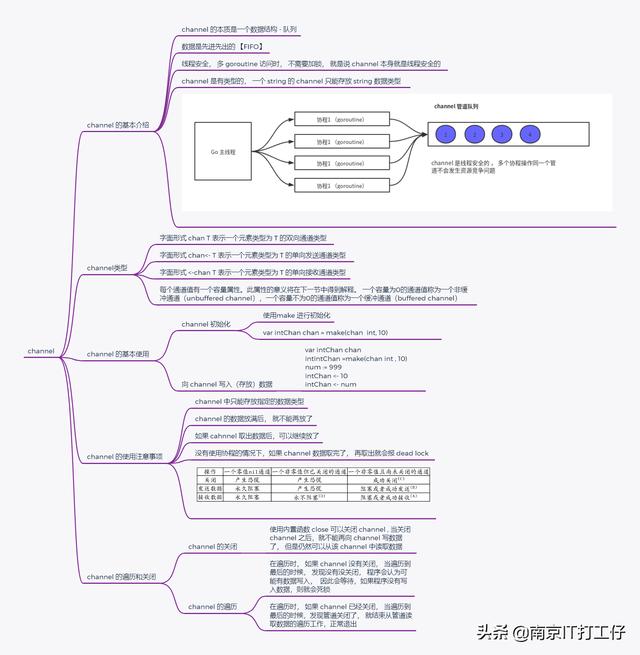
如何协程和java中的线程使用上就是这点区别,那感觉和java多线程使用上区别不大了,只是通过一个go关键字去启动一个协程,java需要Thread的start去启动一个线程,线程和协程也只是虚拟机层面的实现方式不同,go也有类似java中的一些同步函数控制多协程并发的问题。那这样的话,从使用操作层面好像区别就不大了,其实不是这样的,go中的多协程同步更多的是使用了通道,而不是类似上面示例中的类似同步锁的实现。
通道有点类似于java中的队列,一个协程往通道里放数据,一个协程从通道里取数据,通过通道实现多协程之间的数据传递。下面看一个生产消费的例子
package main
import (
“fmt”
“math/rand”
)
func Consumer(ch <-chan int, result chan<- int) {
sum := 0
for i := 0; i < 5; i++ {
//接收数据,会阻塞一直等待通道里有数据
sum += <-ch
}
result <- sum
}
func Producer(ch chan<- int) {
var num int
for i := 0; i < 5; i++ {
rand.Seed(20)
num = rand.Intn(100)
//发送数据,会阻塞等待通道里的数据被消费
ch <- num
}
}
func main() {
//定义一个int类型的无缓冲通道
ch := make(chan int)
result := make(chan int)
go Producer(ch)
go Consumer(ch, result)
fmt.Printf(“result: %d\n”, <-result)
}
声明通道的关键字是chan,创建一个通道需要通过make,声明通道的数据类型,以及通道的容量大小,上面省略了容量的参数,就是一个无缓冲通道,就相当于java中的SynchronizedQueue,这种类型的通 道要求发送 goroutine 和接收 goroutine 同时准备好,才能完成发送和接收操作。通过 ch <- (发送数据) 、<-ch (接收数据) ,