前言
在项目中,有时客户需要判定两个文本的差异比较,求出差异的内容。今天在浏览技术资料时,发现了一个已有的算法可以做到这一点,这个算法就是simhash
simhash算法原理及实现
simhash是google用来处理海量文本去重的算法,simhash最牛逼的一点就是将一个文档,最后转换成一个64位的字节,暂且称之为特征字,然后判断重复只需要判断他们的特征字的距离是不是<n(根据经验这个n一般取值为3),就可以判断两个文档是否相似。
simhash算法原理
imhash值的生成图解如下
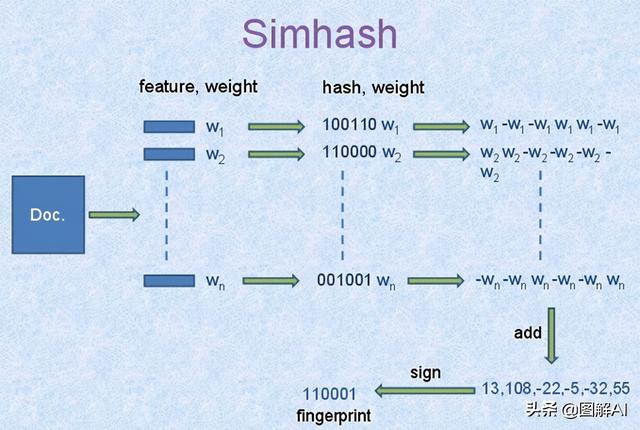
算法过程大概如下:
- 1、将Doc进行关键词抽取(其中包括分词和计算权重),抽取出n个(关键词,权重)对, 即图中的 (feature, weight) 们。 记为 feature_weight_pairs = [fw1, fw2 … fwn] ,其中 fwn = ( feature_n , weight_n`)。
- 2、hash_weight_pairs = [ (hash(feature), weight) for feature, weight in feature_weight_pairs ] 生成图中的 (hash,weight) 们, 此时假设hash生成的位数 bits_count = 6 (如图);
- 3、然后对 hash_weight_pairs 进行位的纵向累加,如果该位是1,则 +weight ,如果是0,则 -weight ,最后生成 bits_count 个数字,如图所示是 [13, 108, -22, -5, -32, 55] , 这里产生的值和hash函数所用的算法相关。
- 4、[13,108,-22,-5,-32,55] -> 110001 这个就很简单啦,正1负0。
simhash值的海明距离计算
二进制串A 和 二进制串B 的海明距离 就是 A xor B 后二进制中1的个数。
举例如下:
A = 100111;
B = 101010;
hamming_distance(A, B) = count_1(A xor B) = count_1(001101) = 3; 当我们算出所有doc的simhash值之后,需要计算doc A和doc B之间是否相似的条件是:
A和B的海明距离是否小于等于n,这个n值根据经验一般取值为3 ,
simhash本质上是 局部敏感性的hash ,和md5之类的不一样。 正因为它的局部敏感性,所以我们可以使用海明距离来衡量simhash值的相似度。
simhash 实现的工程项目
go语言版本实现
安装
go get github.com/yanyiwu/gosimhash
package main
import (
"flag"
"fmt"
"github.com/yanyiwu/gosimhash"
)
var sentence = flag.String("sentence", "我来到北京清华大学", "")
var top_n = flag.Int("top_n", 5, "")
func main() {
flag.Parse()
hasher := gosimhash.New("../dict/jieba.dict.utf8", "../dict/hmm_model.utf8", "../dict/idf.utf8", "../dict/stop_words.utf8")
defer hasher.Free()
fingerprint := hasher.MakeSimhash(*sentence, *top_n)
fmt.Printf("%s simhash: %x\n", *sentence, fingerprint)
} 对比其他算法
『百度的去重算法』
百度的去重算法最简单,就是直接找出此文章的最长的n句话,做一遍hash签名。n一般取3。 工程实现巨简单,据说准确率和召回率都能到达80%以上。
『shingle算法』
shingle原理略复杂,不细说。 shingle算法我认为过于学院派,对于工程实现不够友好,速度太慢,基本上无法处理海量数据。
转载于
simhash算法原理及实现
地址:


