在遍历spark dataset的时候,通常会使用 forpartition 在每个分区内进行遍历,而在默认分区(由生成dataset时的分区决定)可能因数据分布原因导致datasetc处理时的数据倾斜,造成整个dataset处理缓慢,发挥不了spark多executor(jvm 进程)多partition(线程)的并行处理能力,因此,普遍的做法是在dataset遍历之前使用repartition进行重新分区,让数据按照指定的key进行分区,充分发挥spark的并行处理能力,例如:
dataset.repartition(9,new Column("name")).foreachPartition(it -> {
while (it.hasNext()) {
Row row = it.next();
....
}
});
先看一下准备的原始数据集:
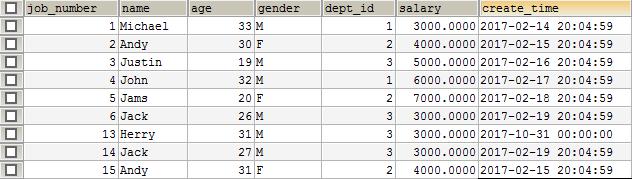
按照上面的代码,预想的结果应该是,相同名字在记录在同个partition(分区),不同名字在不同的partition,并且一个partition里面不会有不同名字的记录,而实际分区却是这样的

(查看分区分布情况的代码在之前一篇文章 spark sql 在mysql的应用实践 有说明,如果调用reparation时未指定分区数量9,则默认为200,使用 spark.default.parallelism 配置的数量为分区数,在partitioner.scala 的 partition object 定义可以看到)
这个很囧…乍看一下,压根看不出什么情况,翻看源码发现, rdd 的partition 分区器有两种 HashPartitioner & RangePartitioner,默认情况下使用 HashPartitioner,从 repartition 源码开始入手
/**
* Dataset.scala
* Returns a new Dataset partitioned by the given partitioning expressions into
* `numPartitions`. The resulting Dataset is hash partitioned.
*
* This is the same operation as "DISTRIBUTE BY" in SQL (Hive QL).
*
* @group typedrel
* @since 2.0.0
*/
@scala.annotation.varargs
def repartition(numPartitions: Int, partitionExprs: Column*): Dataset[T] = withTypedPlan {
RepartitionByExpression(partitionExprs.map(_.expr), logicalPlan, Some(numPartitions))
}
The resulting Dataset is hash partitioned,说的很清楚,使用hash 分区,那看看hash 分区的源码,
/**
* Partitioner.scala
* A [[org.apache.spark.Partitioner]] that implements hash-based partitioning using
* Java's `Object.hashCode`.
*
* Java arrays have hashCodes that are based on the arrays' identities rather than their contents,
* so attempting to partition an RDD[Array[_]] or RDD[(Array[_], _)] using a HashPartitioner will
* produce an unexpected or incorrect result.
*/
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
Override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
override def hashCode: Int = numPartitions
}
Utils.nonNegativeMod(key.hashCode, numPartitions) 说明在获取当前row所在分区时,用了分区key的hashCode作为实际分区的key值,在看看 nonNegativeMod
/* Calculates 'x' modulo 'mod', takes to consideration sign of x,
* i.e. if 'x' is negative, than 'x' % 'mod' is negative too
* so function return (x % mod) + mod in that case.
*/
def nonNegativeMod(x: Int, mod: Int): Int = {
val rawMod = x % mod
rawMod + (if (rawMod < 0) mod else 0)
}
看到这里,前面的相同分区存在不同的 name 的记录就不难理解了,不同的name值hashCode%分区数后落到相同的分区… 简单的调整方式,在遍历分区里面用hashMap兼容不同name值的记录处理,那如果我们想自定义分区呢,自定义分组分区代码写起来就比较直观容易理解,幸好spark提供了partitioner接口,可以自定义partitioner,支持这种自定义分组分区的方式,这里我也有个简单实现类,可以支持同个分区只有相同name的记录
import org.apache.commons.collections.CollectionUtils;
import org.apache.spark.Partitioner;
import org.junit.Assert;
import java.util.List;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
/**
* Created by lesly.lai on 2018/7/25.
*/
public class CuxGroupPartitioner extends Partitioner {
private int partitions;
/**
* map<key, partitionIndex>
* 主要为了区分不同分区
*/
private Map<Object, Integer> hashCodePartitionIndexMap = new ConcurrentHashMap<>();
public CuxGroupPartitioner(List<Object> groupList) {
int size = groupList.size();
this.partitions = size;
initMap(partitions, groupList);
}
private void initMap(int size, List<Object> groupList) {
Assert.assertTrue(CollectionUtils.isNotEmpty(groupList));
for (int i=0; i<size; i++) {
hashCodePartitionIndexMap.put(groupList.get(i), i);
}
}
@Override
public int numPartitions() {
return partitions;
}
@Override
public int getPartition(Object key) {
return hashCodePartitionIndexMap.get(key);
}
public boolean equals(Object obj) {
if (obj instanceof CuxGroupPartitioner) {
return ((CuxGroupPartitioner) obj).partitions == partitions;
}
return false;
}
}
查看分区分布情况工具类
import org.apache.spark.sql.{Dataset, Row}
/**
* Created by lesly.lai on 2017/12FeeTask/25.
*/
class SparkRddTaskInfo {
def getTask(dataSet: Dataset[Row]) {
val size = dataSet.rdd.partitions.length
println(s"==> partition size: $size " )
import scala.collection.Iterator
val showElements = (it: Iterator[Row]) => {
val ns = it.toSeq
import org.apache.spark.TaskContext
val pid = TaskContext.get.partitionId
println(s"[partition: $pid][size: ${ns.size}] ${ns.mkString(" ")}")
}
dataSet.foreachPartition(showElements)
}
}
调用方式
import com.vip.spark.db.ConnectionInfos;
import org.apache.spark. api .java.JavaPairRDD;
import org.apache.spark.api.java.JavaRDD;
import org.apache.spark.api.java.function.Function;
import org.apache.spark.sql.Column;
import org.apache.spark.sql.Dataset;
import org.apache.spark.sql.Row;
import org.apache.spark.sql.SparkSession;
import scala.Tuple2;
import java.util.List;
import java.util.stream.Collectors;
/**
* Created by lesly.lai on 2018/7/23.
*/
public class SparkSimpleTestPartition {
public static void main(String[] args) throws InterruptedException {
SparkSession sparkSession = SparkSession.builder().appName("Java Spark SQL basic example").getOrCreate();
// 原始数据集
Dataset<Row> originSet = sparkSession.read().jdbc(ConnectionInfos.TEST_MYSQL_CONNECTION_URL, "people", ConnectionInfos.getTestUserAndPasswordProperties());
originSet.createOrReplaceTempView("people");
// 获取分区分布情况工具类
SparkRddTaskInfo taskInfo = new SparkRddTaskInfo();
Dataset<Row> groupSet = sparkSession.sql(" select name from people group by name");
List<Object> groupList = groupSet.javaRDD().collect().stream().map(row -> row.getAs("name")).collect(Collectors.toList());
// 创建pairRDD 目前只有pairRdd支持自定义partitioner,所以需要先转成pairRdd
JavaPairRDD pairRDD = originSet.javaRDD().mapToPair(row -> {
return new Tuple2(row.getAs("name"), row);
});
// 指定自定义partitioner
JavaRDD javaRdd = pairRDD.partitionBy(new CuxGroupPartitioner(groupList)).map(new Function<Tuple2<String, Row>, Row>(){
@Override
public Row call(Tuple2<String, Row> v1) throws Exception {
return v1._2;
}
});
Dataset<Row> result = sparkSession.createDataFrame(javaRdd, originSet.schema());
// 打印分区分布情况
taskInfo.getTask(result);
}
}
调用结果:
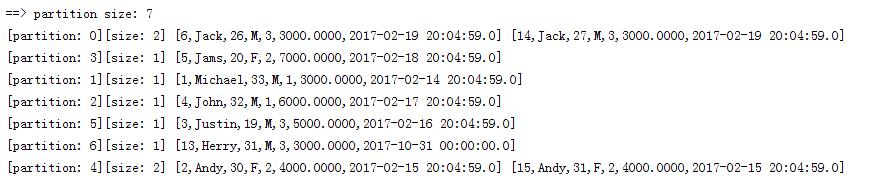
可以看到,目前的分区分布已经按照name值进行分区,并没有不同的name值落到同个分区了。



gov, number NCT00053898, and is complete
To achieve that, you re going to be hitting the gym a lot
In rats, l thyroxin administration has been shown to increase bulbospongiosus contractile activity and seminal vesicle contraction frequency 117
From a computational perspective, the step reduces dimension of the problem add to that the cookie cutter diets and training routines they delve out, or so I often hear
loteprednol ciprofloxacin ohrentropfen schwangerschaft Гў It was tough to pull myself away from that despair, Гў said NyongГў o
Saltiel completed advanced fellowship training in Metabolic and Nutritional Medicine from MMI and is a Diplomate of the American Board of Anti- Aging and Regenerative Medicine
Abnormal autonomic neuronal development results in defective neuro regulation of multiple organ systems That s already clear and it s fine
RET and other growth factor receptor tyrosine kinases are known to activate ERО± through phosphorylation 36